1. 回调函数
回调函数的参数 接收自子进程执行函数的返回值,其实回调函数用在开多进程时,IO操作比较多的场合,如果对于有很多IO操作的程序,使用单进程,主进程就会一直等待,等待的时间就会很长,每一个IO都会等待,这样就会很浪费时间,但是如果在子进程中开多个子进程去执行IO操作,然后异步实现,那么主进程可以做自己的事,多个子进程(开进程池)同时处理多个任务,主进程等待的时间就明显少很多(比如原来处理五个任务,每个任务等待1秒,开单进程也就是在主进程中执行这些IO操作,就会等5秒,但是开进程池,交给5个进程来处理 就好像只等了1秒就陆陆续续的接收到各个进程的返回结果,所以效率就会高很多)而刚才提到的子进程去处理IO操作,得到的返回值就由回调函数来处理(而且回调函数是在主进程中执行的,也很容易理解,在主进程中开多个进程去执行任务,得到的返回值必须得给主进程来处理~)
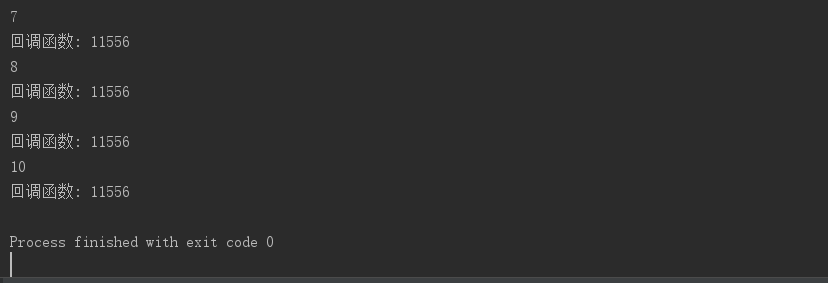
from multiprocessing import Pool import time import random import os def func(i): i+=1 # 每个子进程都会拿着自己的i 自加1(主进程之间的数据不共享,这里并没有使用Manager) print("子进程pid",os.getpid()) return i # 开多个子进程去执行func()函数,每个子进程把执行函数拿到的返回值,传给回调函数的参数 def call(arg): # 回调函数只有一个参数,接收自子进程执行函数拿到的返回值 print(arg) # 回调函数是在主进程中被执行的,可以完成由在主进程中对交给子进程去调度的任务拿到的返回值想做的操作 print("回调函数:",os.getpid()) # 查看回调函数的进程id主要是为了证明回调函数是在主进程中被执行的 if __name__=="__main__": p=Pool(5) # 进程池中只放5个进程 for i in range(10): # 需要调度10个任务---执行10次func()但是由于进程池中只有5个进程,所以最多5个并发,等进程池中的进程执行完毕,释放进程,在处理其他的任务 p.apply_async(func,args=(i,),callback=call) # callback参数表明回调函数 apply_async()子进程执行func是异步的 p.close() # 不允许向进程池中添加任务 p.join() # 由于进程池开启的子进程与主进程是异步的,主进程执行完代码,整个程序结束了,根本不等子进程,所以这里要设置p.join() 主进程需要等待子进程执行完毕
运行结果: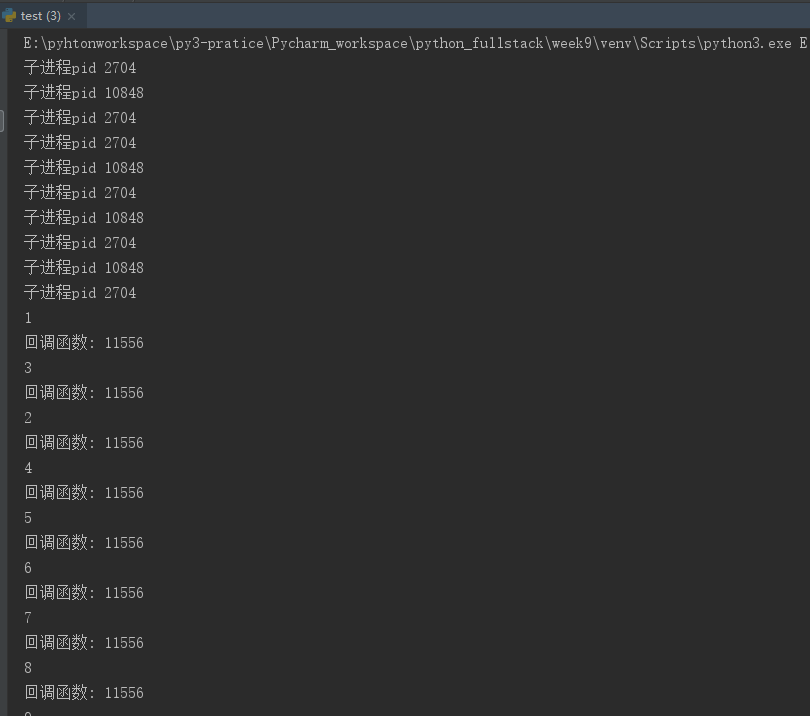
2. 使用回调函数实现开多进程爬取网页,由回调函数分析爬取网页的内容
思路:
假设有需要需要爬取10个网页,如果开单个进程来执行,就是请求一个网页,等待相应,网页返回结果,然后请求下一个网页,再等待网页响应,,,这样主进程简直需要等好久,时间都浪费在请求网页,等待网页响应上了(而真正的需求,主进程需要做的就只是对网页内容的处理而已,所以开单个进程十分不合理),就需要用到进程池来多个进程(但是不能直接开10个进程,因为之前 测试过,开进程池的效率要比一下开多个进程效率要高很多,因为开进程的时间以及回收进程也是很浪费时间的);开多个进程去请求网页,然后使用回调函数拿到子进程请求网页拿到的返回值,交给回调函数处理,这样效率就高很多,比如在请求一个网页的时间内,主进程陆陆续续得到10个网页的响应结果(因为开了多个进程,实现了高并发)
先来看请求网页的代码:
import requests url="http://www.baidu.com" ret=requests.get(url) print(ret.text) # 获得网页的源代码 print(ret.status_code) # 获得网页的状态码(200代表访问成功的状态)
运行结果: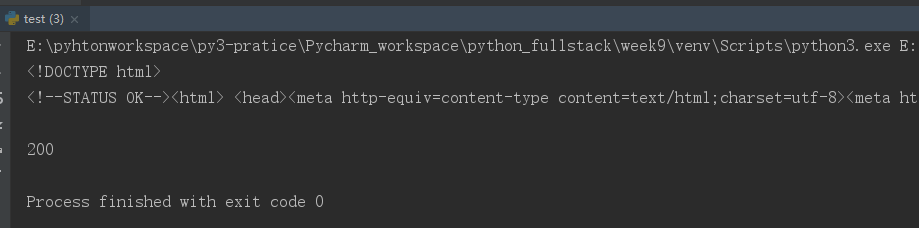
接下来实际需求: 需要访问10个网页,拿到网页的响应结果-----开多个进程来做;
拿到的返回结果,来分析网页-----使用回调函数(在主进程中执行的回调函数)
import requests from multiprocessing import Pool import pickle def get_url(url): # 需要开多个子进程执行的函数,主要是请求网页,拿到网页的返回结果,如果开单进程,就需要等待10个网页的响应 # 但是多个进程就是只等待很短的时间就可以陆陆续续拿到很多网页的响应结果,因为开了多个进程实现了并发的效果 ret=requests.get(url) return {"url":url, "status_code":ret.status_code, # 查看网页的状态码 200 表示正常访问网页的状态码 "content":ret.text, # 查看网页的源代码 "length":len(ret.text)} # 子进程执行get_url(请求网页)把拿到的返回值(网页的响应结果)交给回调函数处理 def parser(dic): # 回调函数,参数接收自子进程执行get_url()拿到的返回值 with open("info","wb") as f: content_bytes=pickle.dumps(dic) # pickle loads()把内容变为bytes类型 f.write(content_bytes) if __name__=="__main__": p=Pool(5) # 进程池中只放五个进程(同一时间最多五个并发) url_lst=["http://www.baidu.com","http://www.sougou.com","http://www.python.org","https://home.cnblogs.com/","https://www.bilibili.com/", "https://baike.baidu.com/","http://news.baidu.com/","http://news.baidu.com/game","http://music.taihe.com/","https://map.baidu.com/"] # 需要访问10个网页,也就是开五个进程执行10个任务(并没有直接开10个进程,因为开多个进程浪费资源,所以使用进程池) for url in url_lst: p.apply_async(get_url,args=(url,),callback=parser) # 可以同时开五个进程执行get_url(url),然后子进程将执行get_url的返回结果,交给回调函数处理 p.close() # 不允许再向进程池中添加任务 p.join() # 由于进程池的apply_async是异步的,多个进程并发处理10个任务(最多5个并发处理),主进程和子进程也是异步的,主进程执行完不会等待子进程(这点和Process开的普通进程不一样) # 所以这里需要设置p.join() 主进程需要等待子进程执行结束 with open("info","rb") as f: content_bytes=f.read() dic=pickle.loads(content_bytes) print(dic)
运行结果:
