实现一个简易网页采集器
- 基于搜狗针对指定不同的关键字将其对应的页面数据进行爬取
1 引入一个新的知识点
参数动态化:
- 如果请求的url携带参数,且我们想要将携带的参数进行动态化操作那么我们必须:
- 1.将携带的动态参数以键值对的形式封装到一个字典中
- 2.将该字典作用到get方法的params参数中即可
- 3.需要将原始携带参数的url中将携带的参数删除
2 演示
接下来演示爬取搜狗搜索“hello树先生”的代码和结果
import requests
keyWord = input("输入一个要查询的内容:")
# 携带了请求参数的url,如果想要爬取不同关键字对应的页面,我们需要将url携带的参数进行动态化
# 实现参数动态化
params = {
'query': keyWord
}
url = 'https://www.sogou.com/web'
# params参数(字典):保存请求时url携带的参数
response = requests.get(url=url, params=params)
page_text = response.text
fileName = keyWord + '.html'
with open(fileName, 'w', encoding='utf-8') as fp:
fp.write(page_text)
print(fileName, '爬取完毕!')
运行截图显示成功爬取下来了

但是查看爬下来的网页发现与真正的界面不一样
真正的界面

爬取下来的图片

其实还有可能出现乱码的情况
3 解决问题
先解决乱码问题
乱码原因是写入编码和原本的编码不一致。规定一致即可。在代码中加入
# 修改相应数据的编码格式 # encoding返回的是响应数据的原式的编码格式,如果给其赋值则表示修改了响应数据的编码格式 response.encoding = 'utf-8'解决页面显示【异常访问请求】导致请求数据的缺失问题
- 异常的访问请求
- 网站后台已经检测出该次请求不是通过浏览器发起的请求而是通过爬虫程序发起的请求。(不是通过浏览器发起的请求都是异常请求)
- 网站的后台是如何知道请求是不是通过浏览器发起的呢?
- 是通过判定请求的请求头中的user-agent判定的
- 什么是User-Agent
- 请求载体的身份标识
- 什么是请求载体:
- 浏览器
- 浏览器的身份标识是统一固定,身份标识可以从抓包工具中获取。
- 爬虫程序
- 身份标识是各自不同
该问题解决的代码实现参考2.6
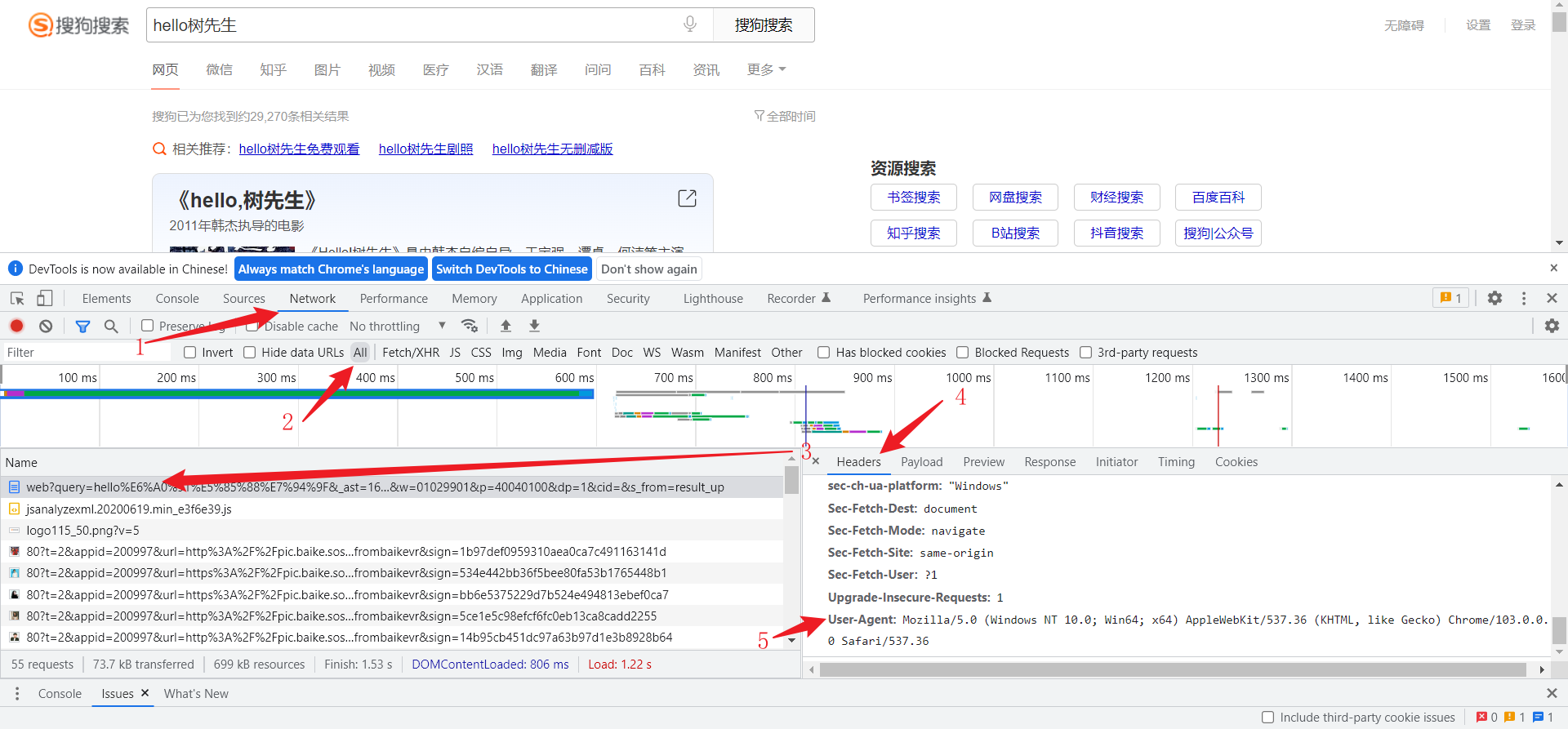
4 如何获得浏览器的User-Agent
- 在一个网页中点击F12。
- 点击NetWork
- 刷新网页
- 找到任意一个请求信息,在右侧选择header
- 找到User-Agent
5 第二种反爬机制
UA检测:网站后台会检测请求对应的User-Agent,以判定当前请求是否为异常请求。
反反爬策略:
- UA伪装:被作用到了到部分的网站中,日后我们写的爬虫程序都默认带上UA检测操作。
- 伪装流程:
- 从抓包工具中捕获到某一个基于浏览器请求的User-Agent的值,将其伪装作用到一个字典中,将该字典作用到请求方法(get,post)的headers参数中即可。
6 异常访问请求代码解决
将我们从浏览器拿到的User-Agent值存入字典headers中
然后将headers字典赋值给请求方法的headers参数
import requests
keyWord = input("输入一个要查询的内容:")
# 携带了请求参数的url,如果想要爬取不同关键字对应的页面,我们需要将url携带的参数进行动态化
# 实现参数动态化
params = {
'query': keyWord
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'
}
url = 'https://www.sogou.com/web'
# params参数(字典):保存请求时url携带的参数
# 加入了headers,实现了UA伪装
response = requests.get(url=url, params=params, headers=headers)
# 修改相应数据的编码格式
# encoding返回的是响应数据的原式的编码格式,如果给其赋值则表示修改了响应数据的编码格式
response.encoding = 'utf-8'
page_text = response.text
fileName = keyWord + '.html'
with open(fileName, 'w', encoding='utf-8') as fp:
fp.write(page_text)
print(fileName, '爬取完毕!')
爬取成功
关注专栏查看更多详细内容