并查集的应用十分广泛,包括一些算法,当应用上并查集的时候,也会更容易实现。下面总结下并查集的相关内容。
什么是并查集?
个人的理解是:并查集就是对集合三种常用操作的再一次抽象。分别是集合的合并(Union)、元素的搜索(Find)和对集合的分解。因为这3中操作非常常用并且又不囿于集合,所以就把这一组操作抽象成一个独立的数据结构。
标准定义
在一些应用问题中,需要将n个不同的元素划分成一组不相交的集合。开始时每个元素自成一个单元素集合,然后按照一定规律将归于同一组元素的集合合并,在此过程中需要反复查询某个元素归属于哪个集合的运算,适合于描述这类问题的抽象数据类型称为并查集(union-find set)。
并查集的3种操作!
从上面的定义也可以看出来,并查集的三种操作是:
(1)Union(Root1, Root2):把子集合Root2并入集合Root1中。要求这两个集合互不相交,否则不执行合并。
(2)Find(x):搜索单元素x所在的集合,并返回该集合的名字。
(3)UnionFindSets(s):构造函数,将并查集中s个元素初始化为s个只有一个单元素的子集合。
并查集的一种实现方案
实现并查集的方式有多种,这里主要总结用树结构(父指针表示法)来实现并查集及其相关操作。
用这种实现方式,每个集合用一棵树表示,树的每一个节点代表集合的一个单元素。所有各个集合的全集合构成一个森林,并用树与森林的父指针表示法来实现。其下标代表元素名。第I个数组元素代表包含集合元素I的树节点。树的根节点的下标代表集合名,根节点的父为-1,表示集合中元素个数。
下面看一个例子:
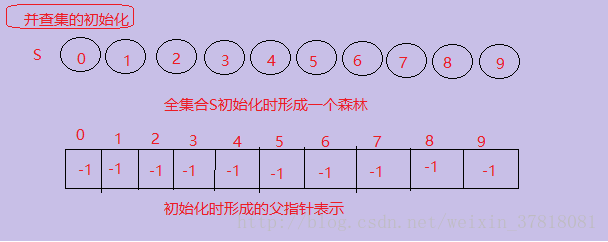
全集合是S = {0,1,2,3,4,5,6,7,8,9},初始化每个元素自成为一个单元素子集合。(书上原图,感觉挺清晰的)
经过一段时间的计算,这些子集合并成3个集合,他们是全集合S的子集合:S1 = {0,6,7,8},S2= {1,4,9},S3 = {2,3,5}。则表示他们并查集的树形结构如下图:
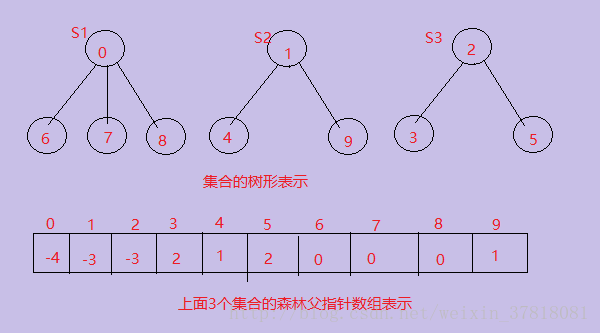
上面数组中的元素值有两种含义:
(1)负数表示当前节点是树的根节点,负数的绝对值表示树中节点的个数,也即集合中元素的个数。
(2)正数表示其所属的树的根节点,由树形表示很容易理解,这也是树的父指针表示的定义。
经过上面对相关数据的组织,再回头来看并查集的3中核心操作是怎样依托于树来实现的:
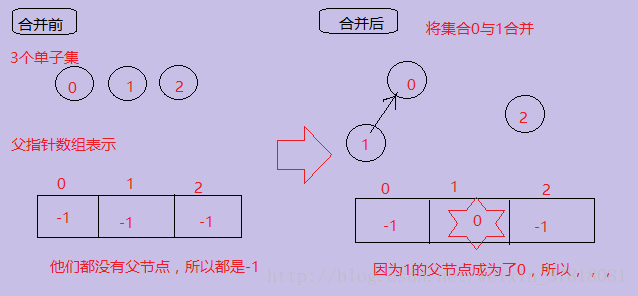
(1)将root2并入到root1中,其实就可以直接把root2的数组元素(就是他的父节点)改成root1的名字(就是他所在的数组下标)。
下面的图表示了合并两个子集合的过程:
(2)查找x所属于的根节点(或者说是x所属于的集合),就可以一直找array[x],直到array[x]小于0,则证明找到了根(所在集合)。
下面的图示意了查找一个节点所属集合的过程:

(3)将整个集合初始化为单元素集合,其实就是建立树的父指针数组的过程,把数组元素全初始化为-1,也就表示了每个元素都各占一个集合。
有了上面的理论,代码也比较容易实现出来!下面给出了一个代码的实例:
/*
*树结构构建并查集,其中树用父指针形式表示
*/
#include <iostream>
const int DefaultSize = 10;
class UFSets { //集合中的各个子集合互不相交
public:
UFSets(int sz = DefaultSize); //构造函数 (并查集的基本操作)
~UFSets() { delete[] parent; } //析构函数
UFSets& operator = (UFSets& R); //重载函数:集合赋值
void Union(int Root1, int Root2); //两个子集合合并 (并查集的基本操作)
int Find(int x); //搜寻x所在集合 (并查集的基本操作)
void WeightedUnion(int Root1, int Root2); //加权的合并算法
private:
int *parent; //集合元素数组(父指针数组)
int size; //集合元素的数目
};
UFSets::UFSets(int sz) {
//构造函数,sz是集合元素的个数,父指针数组的范围0到sz-1
size = sz; //集合元素的个数
parent = new int[size]; //开辟父指针数组
for (int i = 0; i < size; i ++) { //初始化父指针数组
parent[i] = -1; //每个自成单元素集合
}
}
int UFSets::Find(int x) {
//函数搜索并返回包含元素x的树的根
while (parent[x] >= 0) {
x = parent[x];
}
return x;
}
void UFSets::Union(int Root1, int Root2) {
//函数求两个不相交集合的并,要求Root1与Root2是不同的,且表示了子集合的名字
parent[Root1] += parent[Root2]; //更新Root1的元素个数
parent[Root2] = Root1; //令Root1作为Root2的父节点
}
void UFSets::WeightedUnion(int Root1, int Root2) {
//使用节点个数探查方法求两个UFSets集合的并
int r1 = Find(Root1); //找到root1集合的根
int r2 = Find(Root2); //找到root2集合的根
if (r1 != r2) { //两个集合不属于同一树
int temp = parent[r1] + parent[r2]; //计算总节点数
if (parent[r2] < parent[r1]) { //注意比较的是负数,越小元素越多,此处是r2元素多
parent[r1] = r2; //r1作为r2的孩子
parent[r2] = temp; //更新r2的节点个数
}
else {
parent[r2] = r1; //...
parent[r1] = temp; //...
}
}
}
代码的注释比较详尽,我就不在赘言。但是有一个注意点我已经写在了下面!
当前并查集的改进!
的确,有一个极端的状况使得上面的树实现的并查集性能低下!问题原因在于,这里没有规定子集合并的顺序,更确切的说是子集一直在向同一个方向依附:
下面的图片展示了当Union(0,1),Union(1,2),Union(2,3),Union(3,4)执行完后的树的形状。
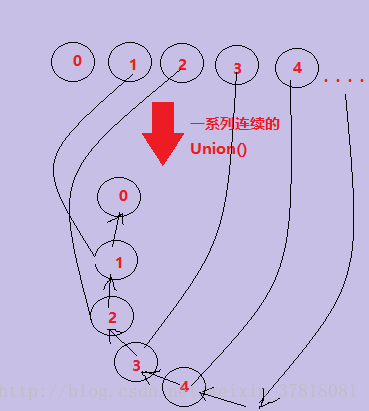
在这种极端情况下他编变成了一个单链表(退化的树),这样的话,用Find函数查找完所有的节点所归属的集合将会开销的时间复杂度为:O(n^2)。
怎样来改变这种状况,就是在合并两个子集的时候,规定顺序,代码中是让元素多的始终作为父节点,这样就避免了这种麻烦。
另外还可以用性能更加的查找算法,例如折叠规则压缩路径。并查集的一个重要的应用是在图论中生成最小生成树的Kruskal算法,充分体现了并查集的优越性和思想,之后会写相关的博文总结此算法!
参考书目:《数据结构 C++语言描述 第二版》 殷人昆著