一、累积BP算法
前文所讲的标准BP算法每次只针对一个训练集中的一个样例。权值和阈值更新的比较频繁,但是对不同的样例进行更新的效果可能出现“抵消”现象。因此,为了达到同样的累积误差极小点,累积BP算法直接针对累积误差最小化,它在读取整个训练集D一遍后才对参数进行更新,频率会低很多。但是,在很多任务中,累积误差下降到一定程度后,进一步的下降会很缓慢,这时,标准的BP往往会更快获得更好的解,在训练集D非常大时就更明显。已证只需一个包含足够多神经元的隐层,多层前馈网络就能以任意精度逼近任意复杂度的连续函数。实际应用中,通常靠“试错法”调整。
BP算法经常遭遇到过拟合。在训练误差减小的同时,测试误差却可能上升。有两种策略:
早停(early stopping):将数据分成训练集和验证集,训练集用来计算梯度,更新连接权和阈值,验证集用来估计误差,若训练集误差降低但验证集误差升高,则停止训练,返回结果。
正则化(regularization):之前有讨论过正则化的内容,在神经网络中,我们给误差目标函数中增加一个用于描述网络复杂度的部分,权值和阈值的平方和。误差目标函数改变为:
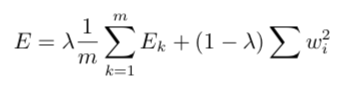
lambda在0到1之间,对经验误差与网络复杂度这两项进行折中。
二、全局最小和局部最小
对于一个误差目标函数,可能会有多个局部最小,但却只会有一个全局最小。我们都希望得到那个全局最小。基于梯度的搜索是使用最为广泛的参数寻优方法。若误差函数具有多个局部极小,则不能保证找到的是全局最小。常用以下策略“跳出”局部极小,进一步接近全局最小:
1、多组不同参数值初始化多个神经网络
按标准方法训练,取误差最小的解作为最终参数。也就是从不同的初始点开始搜索,说不定有一个就可以达到全局最小。
2、使用“模拟退火”(simulated annealing)
模拟退火在每一步都以一定的概率接受比当前解更差的结果,从而有助于“跳出”局部极小。在每步迭代过程中,接受“次优解”的概率要随着时间的推移而逐渐降低,从而保证算法稳定。
3、使用随机梯度下降
计算梯度的时候加入随机因素,于是,即使陷入了局部极小值,计算出的梯度也有可能不为0,就有机会跳出局部极小继续搜索。