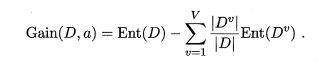第一章 绪论
1、根据西瓜的色泽、根蒂、敲声判断一个瓜是好还是坏,这个是分类。判断西瓜的成熟度是0.95、0.37还是其它。这个是回归。
2、根据训练数据是否拥有标记信息,学习任务可大致划分为两大类:“监督学习”(supervised learning)和“无监督学习”(unsupervised learning),分类和回归是前者的代表,而聚类则是后者的代表。
3、归纳偏好可看作学习算法自身在一个可能很庞大的假设空间中对假设进行选择的启发式或“价值观”,那么,有没有一般性的原则来引导算法确立“正确的”偏好呢?“奥卡姆剃刀“是一种常用的、自然科学研究中最基本的原则,即”若有多个假设与观察一直,则选最简单的那个“,如果采用这个原则,并且假设我们认为”更平滑“意味着”更简单“(例如曲线A更易于描述,而曲线B则要复杂很多,则我们会自然地偏好”平滑“的曲线A。奥卡姆剃刀并非唯一可行的原则。
第二章 模型评估与选择
1、有很多种因素可能导致过拟合,其中最常见的情况是由于学习能力过于强大,以至于把训练样本所包含的不太一般的特性都学到了,而欠拟合则通常是由于学习能力低下而造成的。
2、我们通过实验测试来对学习器的泛化误差进行评估并进而做出选择。为此,需要使用一个测试集来测试学习器对新样本的判别能力,然后以测试集上的测试误差作为泛化误差的近似。通常我们假设测试样本也是从样本真实分布中独立同分布采样而得。但需注意的是,测试集应该尽可能与训练集互斥,即测试样本尽量不在训练集中出现、未在训练过程中使用过。
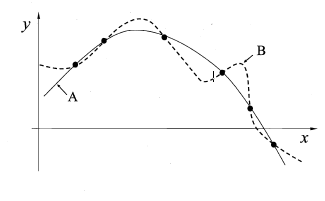
3、通过对数据集D进行适当处理,从中产生出训练集S和测试集T,有下面几种常见的做法:1、留出发;2、交叉验证法(k折交叉验证,K最常用的取值是10);3、自助法。
第三章 线性模型
1、均方误差有非常好的几何意义,它对应了常用的欧几里得距离或简称“欧式距离”。基于均方误差最小化来进行模型求解的方法成为“最小二乘法”。在线性回归中,最小二乘法就是试图找到一条直线,使所有样本到直线上的欧式距离之和最小。
第四章 决策树

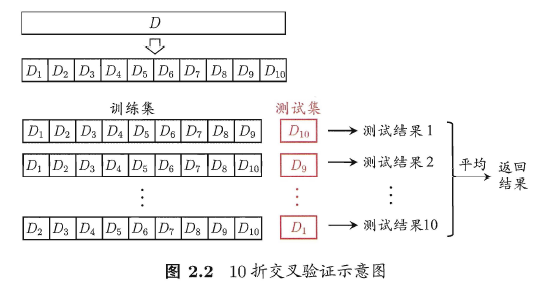
信息增益