目录
浮点数(floating-point number) -> 整数(integer)
01.命名方法
文件名
- 整个应用或包的主入口文件应当是
main.go或与应用名称简写相同。例如:Gogs的主入口文件名为gogs.go。
函数或方法
-
若函数或方法为判断类型(返回值主要为
bool类型),则名称应以Has,Is,Can或Allow等判断性动词开头:func HasPrefix(name string, prefixes []string) bool { ... } func IsEntry(name string, entries []string) bool { ... } func CanManage(name string) bool { ... } func AllowGitHook() bool { ... }
常量
-
常量均需使用全部大写字母组成,并使用下划线分词:
const APP_VER = "0.7.0.1110 Beta" -
如果是枚举类型的常量,需要先创建相应类型:
type Scheme string const ( HTTP Scheme = "http" HTTPS Scheme = "https" ) -
如果模块的功能较为复杂、常量名称容易混淆的情况下,为了更好地区分枚举类型,可以使用完整的前缀:
type PullRequestStatus int const ( PULL_REQUEST_STATUS_CONFLICT PullRequestStatus = iota PULL_REQUEST_STATUS_CHECKING PULL_REQUEST_STATUS_MERGEABLE )
变量
-
变量命名基本上遵循相应的英文表达或简写。
-
在相对简单的环境(对象数量少、针对性强)中,可以将一些名称由完整单词简写为单个字母,例如:
user可以简写为uuserID可以简写uid
-
若变量类型为
bool类型,则名称应以Has,Is,Can或Allow开头:var isExist bool var hasConflict bool var canManage bool var allowGitHook bool -
上条规则也适用于结构定义:
// Webhook represents a web hook object. type Webhook struct { ID int64 `xorm:"pk autoincr"` RepoID int64 OrgID int64 URL string `xorm:"url TEXT"` ContentType HookContentType Secret string `xorm:"TEXT"` Events string `xorm:"TEXT"` *HookEvent `xorm:"-"` IsSSL bool `xorm:"is_ssl"` IsActive bool HookTaskType HookTaskType Meta string `xorm:"TEXT"` // store hook-specific attributes LastStatus HookStatus // Last delivery status Created time.Time `xorm:"CREATED"` Updated time.Time `xorm:"UPDATED"` }
变量命名惯例
变量名称一般遵循驼峰法,但遇到特有名词时,需要遵循以下规则:
- 如果变量为私有,且特有名词为首个单词,则使用小写,如
apiClient。 - 其它情况都应当使用该名词原有的写法,如
APIClient、repoID、UserID。
下面列举了一些常见的特有名词:
// A GonicMapper that contains a list of common initialisms taken from golang/lint
var LintGonicMapper = GonicMapper{
"API": true,
"ASCII": true,
"CPU": true,
"CSS": true,
"DNS": true,
"EOF": true,
"GUID": true,
"HTML": true,
"HTTP": true,
"HTTPS": true,
"ID": true,
"IP": true,
"JSON": true,
"LHS": true,
"QPS": true,
"RAM": true,
"RHS": true,
"RPC": true,
"SLA": true,
"SMTP": true,
"SSH": true,
"TLS": true,
"TTL": true,
"UI": true,
"UID": true,
"UUID": true,
"URI": true,
"URL": true,
"UTF8": true,
"VM": true,
"XML": true,
"XSRF": true,
"XSS": true,
}02.变量
Go语言变量有固定的数据类型,决定了变量内存的长度和存储格式。Go变量只能修改变量值,不能改变变量的数据类型。Go编译器会把未使用的局部变量当做错误,未使用的全局变量不受影响。
// 声明包main
package main
// 导入包
import(
"fmt"
)
// 定义变量
var a int // 初始化为二进制零值
var b = false // 显示初始化变量的值,可以省略变量类型,由编译器自动类型推断
var c, d = 100, "hello" // 一次定义多个变量,数据类型可以不同
// 定义多个变量,建议使用组的形式定义多个变量
var (
e, f int
g, h = 100, "hello"
)
// 定义函数main
func main() {
// 简短模式声明变量
i := 100
/**
*简短模式声明变量,有以下3个条件
*显示初始化
*不能显示指定数据类型
*只能在函数内部使用
*/
// 多变量赋值
x, y := 1, 10
x, y = x+10, y+1 // 先计算右值,然后再对左边变量赋值,必须保证左右值得数据类型相同
// 打印变量的值
fmt.Println(a);
fmt.Println(b);
fmt.Println(c, d)
fmt.Println(e, f)
fmt.Println(g, h)
fmt.Println(i)
fmt.Println(x, y)
}
03.变量声明
Go的语言结构
1、Go的语言基础部分由这几个部分组成
-
包声明
-
引入包
-
函数
-
变量
-
语句&表达式
-
注释
比如下面这个简单的代码:
func main() {
fmt.Println("第一个程序")
}需要注意的是,如果想把单独的.go文件作为独立的可执行文件的时候。需要在代码的第一行加上
package main文件的入口方法为:
func main(){
}go的语法和c是很像的,但是又没有c那么底层。所以有c基础的人,学习go会特别的快。需要注意的一点是:
go声明变量的时候是把变量类型放在变量的后面的,就像这样:
var a string = "abc"go也可以不指定数据类型,但是必须要赋值。如果不赋值,自动类型检查就无法起到作用
哪怕你直接这样:
var a=""附一个空格值给变量也是可以的,就是不能不赋值,也不能为null。而且在go中也没有null的概念,取而代之的是nil:意思为0、无的意思。
还可以使用默认值,就像这样:
var a bool输出为:false
GO语言变量声明的方式
-
指定变量类型,声明后如果不做赋值,那么使用默认值。
//没有进行赋值,但是指明了是什么类型、go会自动加上空值。
var a string-
不指定变量类型,需要进行赋值操作。
//可以不指定变量类型,通过变量值,go会自行判断该变量的类型。
var a=1-
不使用var关键字,直接:=对变量进行赋值操作。
//这种方式是省略了var,但是这种方式能对新的变量使用,对已经声明的变量使用会报错。
a:=1注:
三种变量的声明形式的作用都是一样的,要么赋值可自动判断其类型,要么不赋值,指定变量类型,就这么两点。还需要注意的是,go的变量是如果被声明了,那么必须使用,不然会报错,如果不想使用可以加上_=varName,表示为已抛弃的变量。
//已声明,但未使用
var a=1
//标识为已抛弃的变量。
_=a还需要重点强调的点:
go的变量在已经被声明后,是不能使用:=再次赋值的。
//这样是错误的
var a=1
a:=2但是可以使用=为已声明的变量赋新的值。
//这样做是可以的。
var a=1
a=2而且如果变量值没被使用,那么请加上以抛弃的标识。
_=ago可以直接声明多个变量,通过函数可以返回多个返回值,比如:
//一次性声明所有的变量类型为string类型
var name1,var name2,var name3 string
//函数返回多个返回值
func getName(name1,name2,name3,name4){
return "aa","bb","cc","dd"
}
//返回多个返回的值的函数需要用多个变量进行接受
var a, b, c, d = getName()go可使用var关键字声明全局变量,但是:=这种方式是不能用在全局变量中的。:=只能用在函数体内部。
var (
a int
b bool
xx,yy,dd string="xx","yy","dd"
//这里省略变量类型也是可以的。
zz,aa="zz","aa"
)比如像这样,这样做会报语法错误
var(
a:=1
)03.变量初始化
操作 := 只能用于方法内部, 声明并初始化新的变量
v := 3但是不能用于已声明变量赋值, 下面的做法编译器会报错误"no new variables on left side of :="
var v int = 0
v := 1通过错误可以了解到, := 操作左边必须要有新变量, 那么多个变量初始化只需要满足左边至少有一个新变量即可
err := errors.New("error1")
ret, err := test_fun()这种做法是合法的, 因为ret是新变量, 这样就很方便了, 因为go方法经常会返回错误err, 那么在同一个方法内
只需要声明一个err变量即可
二 :=陷阱
由于:=只能用于局部变量, 那么下面的代码会发生什么情况呢?
var out int = 1
func test() {
out, in := 2, 3
}变量out的作用域包含test(), 但是实际上:= 操作会新创建新的局部变量out, 谨记!!!
那么类似情况:
func test1() {
v := 1
{
v := 1
}
}编译器会不会报"no new variables on left side of :="? 编译器没有报错,所以两个v是不同的变量
在go中 if for switch都可能产生特殊作用域的局部变量,在if for switch中有变量赋值时需要注意 :=
结论:
1 := 左边出现了同层作用域的局部变量,只是赋值操作,没有新生成局部变量
2 := 左边出现了上层作用域的局部变量,新生成同名局部变量并赋值
3 := 左边出现了非局部变量,生成与非局部变量同名的局部变量
GoLang定义变量的方式多种多样,主流的包含以下几种方式:
普通变量:
1、 不指定变量类型的构造函数定义(其实就是强制类型转换)
/*
直接用某个类型的"构造函数"进行赋值,这种赋值方式在C++中比较常见
构造函数打上引号是因为:"在GoLang中实际是没有构造函数的,但是把它理解成构造函数便于大家理解"
*/
var val = uint64(1)
val := uint64(1)2、不指定关键词的推导定义(作用域不同,且无法在全局区定义)
/*关键字也不写!完全交给编译器判断*/
str := "admin"3、 指定关键词的推导定义(作用域不同,可以在全局区定义)
/*只指定关键字的初始化*/
var str := "admin"指针变量定义:
指针变量定义在C家族中的定义与初始化分2种:
1、在C中,推荐的方法是这样的:
/*C 中从heap中分配一块能存储T类型的空间的内存,然后初始化这块内存空间*/
T *t = (T*)malloc(sizeof(T))
memset(t, 0, sizeof(T))2、在C++中,推荐的方法是这样的:
/*C++ 中使用T类型的构造函数进行初始化*/
T *t = new T | new T()而在GoLang中,的指针定义方法是这样的:
/*
new用来分配内存的内建函数,但是与C家族不同的是:”它并不初始化内存,只是将其置零。"
*/
p := new([]int)
*p = make([]int, 1024)这句话可能有点难理解!没事,我们先来看一个示例:
package main
import . "fmt"
func main() {
Println(new([]int))
}
/*
结果输出:
&[]
*/new方法的原型与上述C++的new有点类似,它返回一个type类型为”空“的指针!
然后,我们使用make生成了一个数组并初始化后,就有了一个内存空间。再将p指向这个空间之后,指针的初始化与赋值工作也就结束了。
有些同学可能要问道:这个"空"为什么要打引号呢?
1、 因为这个空是相对而言的,不同类型对空的定义是不一样的;
2、 这个"空"代表未被初始化;
例如:
/*bool 类型的"空"是False*/
b := new(bool)
Println(*b)
/*int 类型的"空"是0*/
i := new(int)
Println(*i)
/*string 类型的'空'是 '' —— 一个空的字符串 */
s := new(string)
Println(*s)
04. 变量赋值
v
要点
- 可以先用var声明,然后用等号赋值;
- 也可以用:=把上面两步合并为一步。
- 区别:=仅用于已经声明过的变量;而:=是声明加赋值。——可参考编译错误信息。
示例
hello.c:
package main
import "fmt" // implements formatted IO
func main() {
var a int
a = 5
b := 10
fmt.Printf("a = %d, b = %d", a, b);
}
运行:
D:\examples>go build hello.go
D:\examples>hello.exe
a = 5, b = 10
D:\examples>
分号
习惯了其他语言(C/C++, Java等),有时候不自觉会在一行最后添加一个分号。事实上,在Go中,一个语句之后不需要加分号,直接换行即可。但如果要在一行写多条语句,则中间要加分号。——Python也不用分号,但需要缩进。
变量类型
在:=情形下,变量的数据类型会自动推导得出。——这和脚本语言非常类似。另外,在代码执行过程中,变量类型也会根据其赋值而自动转变。
1、变量声明和赋值语法
Go语言中的变量声明使用关键字var,例如
复制代码代码如下:
var name string //声明变量
name = "tom" //给变量赋值
这边var是定义变量的关键字,name是变量名称,string是变量类型,=是赋值符号,tom是值。上面的程序分两步,第一步声明变量,第二步给变量赋值。也可以将两步合到一起。
复制代码代码如下:
var name string = "tom"
如果在声明时同时赋值,可以省略变量类型,Go语言可以根据初始值来判断变量的类型,所以也可以这样写
复制代码代码如下:
var name = "tom"
Go语言还提供了一种更简短的写法
复制代码代码如下:
name := "tom"
在Go语言中不能对同一个变量声明多次。例如下例的代码就是不允许的:
复制代码代码如下:
i := 1
i := 2 //这个是不允许的
:= 表示声明和赋值,所以是不允许的,运行后系统会提示:no new variables on left side of :=
2、变量命名规则
变量名由字母、数字、下划线组成,其中首个字母不能为数字。
变量的声明不能和保留字同名,以下是保留字:
复制代码代码如下:
break default func interface select
case defer go map struct
chan else goto package switch
const fallthrough if range type
continue for import return var
3、范例
复制代码代码如下:
b := false //布尔型
i := 1 //整型
f := 0.618 //浮点型
c := 'a' //字符
s := "hello" //字符串
cp := 3+2i //复数
i := [3]int{1,2,3} //数组
_(下划线)是个特殊的变量名,任何赋予它的值都会被丢弃:
_, i, _, j := 1, 2, 3, 4
func test() (int, string) {
return 250, "sb"
}
_, str := test()
06. 匿名变量
_(下划线)是个特殊的变量名,任何赋予它的值都会被丢弃:
_, i, _, j := 1, 2, 3, 4
func test() (int, string) {
return 250, "sb"
}
_, str := test()
07.常量
*声明一个常量
const MAX = 4096*声明一个指定类型的常量
const LIMIT int16 = 1024
const LIMIT2 = int16(1024)*声明一组常量
const (
start = 0x1
resume = 0x2
stop = 0x4
)*声明一组指定类型的常量
const (
start int8 = 0x1
resume int8 = 0x2
stop int8 = 0x4
)*用iota简化上面的写法
const (
start int8 = 1 << iota
resume
stop
)
常量是指程序运行时不可改变的值,常量必须初始化值,定义常量可以指定类型,编译器也可以通过常量初始化值做类型推断。在函数代码块中定义常量,不被使用也不会出现编译错误。在常量组中如果不指定常量类型和初始化值,那么常量会和上一行的非空常量值相同。
// 声明包main
package main
// 导入包
import (
"fmt"
)
// 定义常量
const a = 10 // 必须赋值,可指定类型,也可以编译器通过初始化值类型推断
const b = "Hello World"
const c = false
const d, e = 1, 10
// 常量组
const (
f = true
g = 100
)
// 定义函数main
func main() {
// 函数块中定义的常量,不适用也不会出现编译错误
const (
h = 1
i // 在常量组中不指定常量类型和初始化值,会和上一行非空的常量值相同。
j
k
)
const g = "Hello World"
fmt.Println(a)
fmt.Println(b)
fmt.Println(c)
fmt.Println(d, e)
fmt.Println(f, g)
fmt.Println(i)
fmt.Println(j)
fmt.Println(k)
}字面常量(常量值)
在源代码中字面量可以描述像数字,字符串,布尔等类型的固定值。Go 和 JavaScript、Python 语言一样,即便是复合类型(数组,字典,切片,结构体)也允许使用字面量。Golang 的复合字面量表达也很方便、简洁,使用单一语法即可实现。在 JavaScript 中它是这样的:
var numbers = [1, 2, 3, 4]
var thing = {name: "Raspberry Pi", generation: 2, model: "B"}
在 Python 中有类似的语法:
elements = [1, 2, 3, 4]
thing = {"name": "Raspberry Pi", "generation": 2, "model": "B"}
在 Go 中也类似(这里有些地方可以变通):
elements := []int{1, 2, 3, 4}
type Thing struct {
name string
generation int
model string
}
thing := Thing{"Raspberry Pi", 2, "B"}
// 或者直接使用结构体的项名称
thing = Thing{name: "Raspberry Pi", generation: 2, model: "B"}
除了字典类型以外的其他类型,键是可选的,便于理解没有歧义:
- 对结构体而言,键就是项名称
- 对于数组或切片而言,键就是索引
键不是字面量常量,就必须是常量表达式;因此这种写法是错误的:
f := func() int { return 1 }
elements := []string{0: "zero", f(): "one"}
这将导致编译异常 -- "index must be non-negative integer constant"。而常量表达式或者字面量是合法的:
elements := []string{0: "zero", 1: "one", 4 / 2: "two"}
编译一切顺利。
重复的键是不允许的:
elements := []string{
0: "zero",
1: "one",
4 / 2: "two",
2: "also two"
}
在编译时会报出 "duplicate index in array literal: 2" 的异常信息。这也同样适用于结构体:
type S struct {
name string
}
s := S{name: "Michał", name: "Michael"}
编译结果是 "duplicate field name in struct literal: name" 的错误。
相应的字面量必须被赋值给相应的键,元素或结构体的项。更多关于可赋值性的内容可查看 "Go 语言中的可赋值性"一文。
结构体
对于结构体类型定义的项,这里有两三个创建实例时的规定。
像下面的代码片段,结构体的定义必须指定内部项的名称,并且如果使用了那些定义以外的名称,那么在编译时会发生错误:"unknown S field ‘name’ in struct literal":
type S struct {
age int8
}
s := S{name: "Michał"}
如果最先的字面量有对应的键,那么之后的字面量也必须有对应的键,下面这样写是不合理的 :
type S struct {
name string
age int8
}
s := S{name: "Michał", 29}
像这样,编译器会抛出异常"mixture of field:value and value initializers",可以通过省略结构体中所有元素对应的键来更正它。
s := S{"Michał", 29}
但这样又有一个附加限制:字面量的依次顺序必须与结构体定义时各项的顺序保持一致。
必须使用键:值或值的形式初始化结构体,并不代表我们必须赋值结构体中的每一项。被忽略的项将会默认赋值为该项类型对应的零值:
type S struct {
name string
age int8
}
s := S{name: "Michał"}
fmt.Printf("%#v\n", s)
输出:
main.S{name:"Michał", age:0}
只有使用键:值的形式初始化结构体时,才会有默认赋零值的操作:
s := S{"Michał"}
这种写法是不能编译通过的,会抛出异常"too few values in struct initializer"。当有新的项被添加到结构体的一个被字面量赋值的项之前时,这种报错的做法对程序员更加安全--如果这个结构体中,一个名为"title"的字符串类型的项被加到了"name"项之前,那么值"Michał"将被认为是一个"title",而这个问题是很难被排查出来的。
如果结构体字面量是空值,那么结构体内每一项都会被赋于零值:
type Employee struct {
department string
position string
}
type S struct {
name string
age int8
Employee
}
main.S{name:"", age:0, Employee:main.Employee{department:"", position:""}}
最后一个规定,结构体的赋值与导出标示有关(简而言之,字面量不允许给非导出项赋值)
数组和切片
数组或者切片的元素都是被索引的,所以在字面上键必须是整数常量表达式。对于没有键的元素,键将会被赋值为前一个元素索引加一。在字面上,第一个元素的键(索引)如果没有被赋值,默认设为零。
numbers := []string{"a", "b", 2 << 1: "c", "d"}
fmt.Printf("%#v\n", numbers)
[]string{"a", "b", "", "", "c", "d"}
赋值元素的数量可以小于数组的长度(被忽略的元素将会被赋值为零):
fmt.Printf("%#v\n", [3]string{"foo", "bar"})
[3]string{"foo", "bar", ""}
不允许对超出范围的索引赋值,所以下面几行代码是无效的:
[1]string{"foo", "bar"}
[2]string{1: "foo", "bar"}
可以通过使用三个点(...)的快捷符号来省去程序员声明数组长度的工作,编译器会通过索引最大值加一的方式获得它:
elements := […]string{2: "foo", 4: "bar"}
fmt.Printf("%#v, length=%d\n", elements, len(elements))
输出:
[5]string{"", "", "foo", "", "bar"}, length=5
切片与之前数组内容基本一致:
els := []string{2: "foo", 4: "bar"}
fmt.Printf("%#v, length=%d, capacity=%d\n", els, len(els), cap(els))
得出结果:
[]string{"", "", "foo", "", "bar"}, length=5, capacity=5
字典
除了将数组长度替换成了键类型以外,字典字面量的语法和数组非常类似。
constants := map[string]float64{"euler": 2.71828, "pi": .1415926535}
快捷方式
如果作为字典键或者数组、切片、字典元素的字面量的类型与键或元素的类型一致,那么为了简洁,这个类型可以省略不写:
coords := map[[2]byte]string{{1, 1}: "one one", {2, 1}: "two one"}
type Engineer struct {
name string
age byte
}
engineers := [...]Engineer{{"Michał", 29}, {"John", 25}}
同样,如果键或元素是指针类型的话,&T也可以被省略:
engineers := […]*Engineer{{"Michał", 29}, {"John", 25}}
fmt.Printf("%#v\n", engineers)
输出:
[2]*main.Engineer{(*main.Engineer)(0x8201cc1e0), (*main.Engineer)(0x8201cc200)}iota
枚举类型在C#或C++,java,VB等一些计算机编程语言中是一种基本数据类型而不是构造数据类型,而在C语言等计算机编程语言中是一种构造数据类型。它用于声明一组命名的常数,当一个变量有几种可能的取值时,可以将它定义为枚举类型。
枚举可以根据Integer、Long、Short或Byte中的任意一种数据类型来创建一种新型变量。这种变量能设置为已经定义的一组之中的一个,有效地防止用户提供无效值。该变量可使代码更加清晰,因为它可以描述特定的值。
从上面知道:是一组命名的常数,常量值可以是连续的,也可以是断续的。比较正规的理解如下:
在程序设计中,有时会用到由若干个有限数据元素组成的集合,如一周内的星期一到星期日七个数据元素组成的集合,由三种颜色红、黄、绿组成的集合,一个工作班组内十个职工组成的集合等等,程序中某个变量取值仅限于集合中的元素。此时,可将这些数据集合定义为枚举类型。因此,枚举类型是某类数据可能取值的集合,如一周内星期可能取值的集合为:
{ Sun,Mon,Tue,Wed,Thu,Fri,Sat}
该集合可定义为描述星期的枚举类型,该枚举类型共有七个元素,因而用枚举类型定义的枚举变量只能取集合中的某一元素值。由于枚举类型是导出数据类型,因此,必须先定义枚举类型,然后再用枚举类型定义枚举型变量。
2、枚举类型注意事项
使用枚举类型要从以下方面考虑:
1、枚举概念:查看《1、枚举类型定义》
2、枚举成员:用于声明新的枚举类型。是该枚举类型的命名常数。任意两个枚举成员不能具有相同的名称。每个枚举成员均具有相关联的常数值。此值的类型就是枚举的基础类型。每个枚举成员的常数值必须在该枚举的基础类型的范围之内。
3、枚举成员默认值:在枚举类型中声明的第一个枚举成员它的默值为零。
4、枚举成员显示赋值:允许多个枚举成员有相同的值。没有显示赋值的枚举成员的值,总是前一个枚举成员的值+1。
5、枚举类型与基础类型的转换
3.1 枚举类型实现
查看2.4,可根据iota特性进行枚举类型的定义:

测试输出如下:
![7_T9%2}S6%SBW187F[]HAOW](http://static.oschina.net/uploads/img/201609/10204709_Ykxj.png)
枚举类型使用步骤:
- 声明枚举类型
- 定义枚举变量
- 使用枚举变量
注意:从golang枚举类型定义来看,变量enum也可以为99等其他int类型。从这个方面来看,golang定义的枚举类型比较广泛。如下图:

3.2 iota的优势
从3.1来看golang的枚举类型实现也是比较简单的,利用iota的递增规则进行编程。
iota的使用规则,详情查看《golang 使用 iota》。
3.3 如何使用多个iota
3.1中定义的枚举类型对应的值Success=1、Failed=2、DuplicateEvent=3、DuplicateCommand=4,是按照iota递增规则进行的,加入要试下Success=1、Failed=2、DuplicateEvent=0、DuplicateCommand=1,可行吗?答案是完全行的通的,修订枚举定义格式:

测试结果如下:
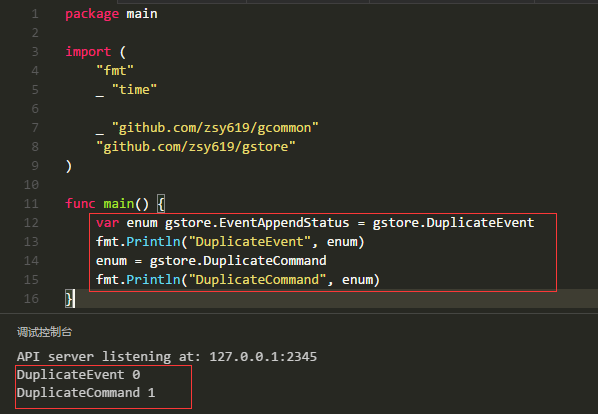
3.4 枚举类型定义二
3.1是一种实现方式,由于iota还可以与表达式一起是使用,所以可以简化定义,如下:

测试如下:
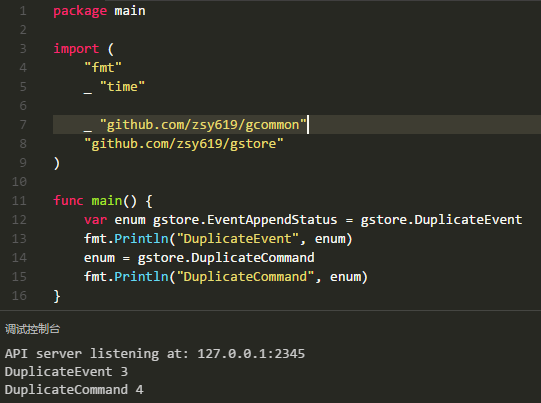
与预期一样。
3.5 总结
使用iota可以试下golang枚举类型的定义。但golang的枚举类型并不是严格意义上的枚举类型,要认识到这点。
08.基础数据类型
| 类型 |
名称 |
长度 |
零值 |
说明 |
| bool |
布尔类型 |
1 |
false |
其值不为真即为家,不可以用数字代表true或false |
| byte |
字节型 |
1 |
0 |
uint8别名 |
| rune |
字符类型 |
4 |
0 |
专用于存储unicode编码,等价于uint32 |
| int, uint |
整型 |
4或8 |
0 |
32位或64位 |
| int8, uint8 |
整型 |
1 |
0 |
-128 ~ 127, 0 ~ 255 |
| int16, uint16 |
整型 |
2 |
0 |
-32768 ~ 32767, 0 ~ 65535 |
| int32, uint32 |
整型 |
4 |
0 |
-21亿 ~ 21 亿, 0 ~ 42 亿 |
| int64, uint64 |
整型 |
8 |
0 |
|
| float32 |
浮点型 |
4 |
0.0 |
小数位精确到7位 |
| float64 |
浮点型 |
8 |
0.0 |
小数位精确到15位 |
| complex64 |
复数类型 |
8 |
|
|
| complex128 |
复数类型 |
16 |
|
|
| uintptr |
整型 |
4或8 |
|
⾜以存储指针的uint32或uint64整数 |
| string |
字符串 |
|
"" |
utf-8字符串 |
1 整数
在 Go 语言中,如果不加特殊前缀,都是10进制表示,例如:“100”
整数可以直接用指数形式,例如:“1E9”,意思是 1 * (10^9),1 乘以 10 的 9 次方
整数的加减法用 + 和 - 号,乘法用 * 号,除法用 / 号, 得到的商是整数,例如 5 / 2 = 2,而 % 号是求余(取模), 例如 5 % 2 = 1
在 Go语言中,整数类型分为带符号整型和不带符号整型,接着又分别按照长度各自划分为4个类型。
带符号整型 int8 int16 int32 int64
不带符号整型 uint8 uint16 uint32 uint 64
除此之外还有默认类型 int 和 uint,目前都是32位,未来可能会变成64位
还有2个特殊的整型别名 ,和字符串很相关,分别是:byte(uint8),rune(int32),到字符串相关时在做解释
整数比较用 > / < / == / != / <= / >=,结果是布尔类型, true or false
按位运算 &(且), |(或), ^(异或),&^(与非),<<(左移),>>(右移)
异或自身,相当于取反码, 例如 ^1 = -2(ps:(^-1) + 1 = 求-1的补码)
2 浮点数
在 Go 语言中,浮点数分为 float32 和 float64 两种类型,符合 IEEE 754 的规定。
只有整数部分的浮点数,要加小数点标识,例如浮点数 1 的标识为 1.0
对于整数字面量 和浮点数字面量,Go 根据使用的场合,会自动 整数->浮点数 或 浮点数-> 整数 转换
3 复数
基本上很少用到,简单介绍下
在 Go 语言中,复数分为 complex64 和 complex128,可以用 0+1i 的格式表示
4 布尔
在 Go 语言中,布尔值的类型为 bool,值是 true 或 false
布尔可以做3种逻辑运算,&&(逻辑且),||(逻辑或),!(逻辑非)
在逻辑表达式中,Go语言也支持短路判断
布尔类型的值不支持其他类型的转换
5 字符串
在 Go 语言中,组成字符串的最小单位是字符,存储的最小单位是字节,字符串本身不支持修改。
字节是数据存储的最小单元,每个字节的数据都可以用整数表示,例如一个字节储存的字符a,实际存储的是97而非字符的字形,将这个实际存储的内容用数字表示的类型,称之为byte。
字符是 UTF-8 编码的 Unicode 字符,Unicode 为每一个字符而非字形定义唯一的码值(即一个整数),例如 字符a 在 unicode 字符表是第 97 个字符,所以其对应的数值就是 97,也就是说对于Go语言处理字符时,97 和 a 都是指的是字符a,而 Go 语言将使用数值指代字符时,将这样的数值称呼为 rune 类型
通常Unicode表示一个字符时,通常会用"U+"然后紧接着一组十六进制的数字来表示这个字符,例如 字符a 通常用 U+0061 来表示。
在 Go 语言中,如果直接按照字符的字形的话,可以用单引号 (') 括起来表示,例如 'a' ,也可按照码值来表示,可以用 \xNN ,\uNNNN , \UNNNNNNNN 的 格式,每个 N 代表一位数。例如 字符a 可以用 \x61 或 \u0061 或 \U00000061
在 Go 语言中,可以用两种方式表示字符串,一种是双引号 (") 括在一起的,可以包含转义字符。另一种是使用反引号 (`) 括起的,可以包含换行等格式字符,感觉有点象其他语言的 heredoc 。
因为组成字符串的最小单位是字符,而存储的最小单位是字节,对于字符串遍历,只有全是小于1个字节字符(即码值小于256)组成的,可以直接遍历或者转成byte切片遍历,而包含大于1个字节字符组成的,最安全的做法是转换成rune切片。
09.格式化输出输入
2.5.1 格式说明
| 格式 |
含义 |
| %% |
一个%字面量 |
| %b |
一个二进制整数值(基数为2),或者是一个(高级的)用科学计数法表示的指数为2的浮点数 |
| %c |
字符型。可以把输入的数字按照ASCII码相应转换为对应的字符 |
| %d |
一个十进制数值(基数为10) |
| %e |
以科学记数法e表示的浮点数或者复数值 |
| %E |
以科学记数法E表示的浮点数或者复数值 |
| %f |
以标准记数法表示的浮点数或者复数值 |
| %g |
以%e或者%f表示的浮点数或者复数,任何一个都以最为紧凑的方式输出 |
| %G |
以%E或者%f表示的浮点数或者复数,任何一个都以最为紧凑的方式输出 |
| %o |
一个以八进制表示的数字(基数为8) |
| %p |
以十六进制(基数为16)表示的一个值的地址,前缀为0x,字母使用小写的a-f表示 |
| %q |
使用Go语法以及必须时使用转义,以双引号括起来的字符串或者字节切片[]byte,或者是以单引号括起来的数字 |
| %s |
字符串。输出字符串中的字符直至字符串中的空字符(字符串以'\0‘结尾,这个'\0'即空字符) |
| %t |
以true或者false输出的布尔值 |
| %T |
使用Go语法输出的值的类型 |
| %U |
一个用Unicode表示法表示的整型码点,默认值为4个数字字符 |
| %v |
使用默认格式输出的内置或者自定义类型的值,或者是使用其类型的String()方式输出的自定义值,如果该方法存在的话 |
| %x |
以十六进制表示的整型值(基数为十六),数字a-f使用小写表示 |
| %X |
以十六进制表示的整型值(基数为十六),数字A-F使用小写表示 |
2.5.2 输出
//整型
a := 15
fmt.Printf("a = %b\n", a) //a = 1111
fmt.Printf("%%\n") //只输出一个%
//字符
ch := 'a'
fmt.Printf("ch = %c, %c\n", ch, 97) //a, a
//浮点型
f := 3.14
fmt.Printf("f = %f, %g\n", f, f) //f = 3.140000, 3.14
fmt.Printf("f type = %T\n", f) //f type = float64
//复数类型
v := complex(3.2, 12)
fmt.Printf("v = %f, %g\n", v, v) //v = (3.200000+12.000000i), (3.2+12i)
fmt.Printf("v type = %T\n", v) //v type = complex128
//布尔类型
fmt.Printf("%t, %t\n", true, false) //true, false
//字符串
str := "hello go"
fmt.Printf("str = %s\n", str) //str = hello go
2.5.3 输人
var v int
fmt.Println("请输入一个整型:")
fmt.Scanf("%d", &v)
//fmt.Scan(&v)
fmt.Println("v = ", v)
10.类型转换
有时候你可能需要将变量转换为其他类型。Golang 不容许随意处理这种转换,转换是由类型系统的强制保证的某些规则。在这篇文章中,我们将讨论哪些转换是可能的,哪些是不可能,以及什么时候进行转换是有价值的。
Go 是一门强类型语言。它在类型上是严格的,编译期间会报告类型错误。
package main
import "fmt"
func main() {
monster := 1 + "2"
fmt.Printf("monster: %v\n", monster)
}
> go build
# github.com/mlowicki/lab
./lab.go:6: cannot convert "2" to type int
./lab.go:6: invalid operation: 1 + "2" (mismatched types int and string)
JavaScript 是弱类型语言的一种,让我们看看它的实际效果:
var monster = 1 + "foo" + function() {};
console.info("type:", typeof monster)
console.info("value:", monster);
我将数字,字符串甚至函数加在一起,这似乎是件奇怪的事情。但不用担心,JavaScript 会无报错地为你处理这些事情。
type: string
value: 1foofunction () {}
在特定的情况,可能需要将一个变量转为其他类型,例如将它作为函数参数传递,或是放进某个表达式中。
func f(text string) {
fmt.Println(text)
}
func main() {
f(string(65)) // 整型常量转换为字符串。
}
函数调用的表达式是类型转换的常见情况, 下面我们会多次看到类似的转换。上面的代码是能够正常运行的,但是如果移除类型转换:
f(65)
会导致一个编译时错误:"cannot use 65 (type int) as type string in argument to f" (无法将整数类型的 65 作为字符串类型参数给 f )
底层类型(Underlying type)
字符串,布尔值,数字或者字面量类型的底层类型仍是他们本身,其他情况下,类型声明定义了底层类型:
type A string // string
type B A // string
type C map[string]float64 // map[string]float64 (type literal)
type D C // map[string]float64
type E *D // *D
(注释里是对应的底层类型) 如果底层类型是相同的,那么类型转换时百分百有效的。
package main
type A string
type B A
type C map[string]float64
type C2 map[string]float64
type D C
func main() {
var a A = "a"
var b B = "b"
c := make(C)
c2 := make(C2)
d := make(D)
a = A(b)
b = B(a)
c = C(c2)
c = C(d)
var _ map[string]float64 = map[string]float64(c)
}
上面的程序不会有任何的编译问题。底层类型的定义不能是递归的( Definition of underlying types isn’t recursive)
译按:
关于底层类型的定义不能是递归的情况,译者对这种说法保持怀疑。 底层类型的定义要么解释到内置类型(int, int64, float, string, bool...), 要么递归解释到 unnamed type 的。例如
- B->A->string, string 为内置类型,解释停止, B 的底层类型为 string;
- U->T->map[S]float64, map[S]float64 为 unnamed type, 解释停止,U 的底层类型为 map[S]float64。
type A string // string type B A // string type S string // string type T map[S]float64 // map[S]float64 type U T // map[S]float64
type S string
type T map[S]float64
....
var _ map[string]float64 = make(T)
上面的程序会在编译期间报错:
cannot use make(T) (type T) as type map[string]float64 in assignment
赋值错误的发生,是因为 T 的底层类型不是 map[string]float64 而是 map[S]float64。类型转换也会报错:
var _ map[string]float64 = (map[string]float64)(make(T))
上面的代码会在编译时导致如下错误:
cannot convert make(T) (type T) to type map[string]float64
可赋值性(Assignability)
Go 语言规范提出可赋值性(Assignability)的概念,它定义了什么时候一个变量 v 能够被赋值给 T 类型的变量。让我们在代码中了解它的一个规则:赋值时,两者应该具有相同的底层类型,并且至少有一个不是 named 类型。
package main
import "fmt"
func f(n [2]int) {
fmt.Println(n)
}
type T [2]int
func main() {
var v T
f(v)
}
程序输出 “[0 0]”。在可赋值性规则许可的范围内,所有的类型转换都是可行的。程序员能用这种方式清晰地表达他的具体的想法:
f([2]int(v))
上面的调用方法会和之前的得到一样的结果。关于可赋值性更多信息可以在之前的文章中找到。
类型转换的第一个规则(具有相同的底层类型)和可赋值规则的一条规则是重合的 - 当底层类型是相同的时候,至少有一个的类型是 unnmaed 类型(这一节的第一个例子)。较弱的规则会影响更严格的规则。因此当类型转换时,只需要底层类型保持一致,是否是 named/unnamed 类型并不重要。
常量
常量 v 能够被转换为类型 T, 当 v 能被 T 类型的变量表示时。
a := uint32(1<<32 – 1)
//b := uint32(1 << 32) // constant 4294967296 overflows uint32
c := float32(3.4e38)
//d := float32(3.4e39) // constant 3.4e+39 overflows float32
e := string("foo")
//f := uint32(1.1) // constant 1.1 truncated to integer
g := bool(true)
//h := bool(1) // convert 1 (type int) to type bool
i := rune('ł')
j := complex128(0.0 + 1.0i)
k := string(65)
对于常量更深入的介绍可以在官方博客中找到。
数字类型
浮点数(floating-point number) -> 整数(integer)
var n float64 = 1.1
var m int64 = int64(n)
fmt.Println(m)
小数部分被移除,因此代码输出 ”1“。
对于其他转换:
- 浮点数 -> 浮点数,
- 整数 -> 整数,
- 整数 -> 浮点数,
- 复数 -> 复数。
变量会被四舍五入至目标精度:
var a int64 = 2 << 60
var b int32 = int32(a)
fmt.Println(a) // 2305843009213693952
fmt.Println(b) // 0
a = 2 << 30
b = int32(a)
fmt.Println(a) // 2147483648
fmt.Println(b) // -2147483648
b = 2 << 10
a = int64(b)
fmt.Println(a) // 2048
fmt.Println(b) // 2048
指针
可赋值性(Assignability) 以和处理其他类型一样的方式处理指针类型。
package main
import "fmt"
type T *int64
func main() {
var n int64 = 1
var m int64 = 2
var p T = &n
var q *int64 = &m
p = q
fmt.Println(*p)
}
程序正常工作并且输出 ”2“,这依赖于已经被讨论过的可赋值性规则(assignability rule)。int64 和 T* 的底层类型是相同的,并且 int64* 是 unnamed 类型。类型转换则更宽松一些。对于 unnamed 指针类型,指针的基类型(base type)具有相同的底层类型即可转换。
译按: 指针的基类型(base type)为指针所指向变量的类型,例如 p *int, p 的基类型为 int。
package main
import "fmt"
type T int64
type U W
type W int64
func main() {
var n T = 1
var m U = 2
var p *T = &n
var q *U = &m
p = (*T)(q)
fmt.Println(*p)
}
*T 应该在括号内,否则他会被理解成 *(T(q))
和之前的程序一样,输出 “2”。因为 U 和 T 的在作为U* 和 T* 的基类型的同时,他们的底层类型是相同的。 如下的赋值操作:
p = q
是不会成功的,因为它尝试处理两种不同的底层类型: T* 和 U*。作为练习,让我们稍微改变声明,看会发生什么
type T *int64
type U *W
type W int64
func main() {
var n int64 = 1
var m W = 2
var p T = &n
var q U = &m
p = T(q)
fmt.Println(*p)
}
U 和 W 的声明已经被改变。思考一下,会发生什么?
编译器在以下位置报一个错误 “cannot convert q (type U) to type T”(无法将 q (类型 U) 转换为类型 T):
p = T(q)
这是因为 p 的底层类型是 int64,而 q* 的是 W。q 的类型是 named(U*),因此获取指针基类型的底层类型的规则并不适用在这里。
字符串
整数 -> 字符串
传递数字 N 到 string 内置地将 N 转化为 UTF-8 编码的字符串,该字符串是 N 表达的字符组成。
fmt.Printf("%s\n", string(65))
fmt.Printf("%s\n", string(322))
fmt.Printf("%s\n", string(123456))
fmt.Printf("%s\n", string(-1))
输出:
A
ł
�
�
前两个转换使用完全有效的码位。也许你会好奇为什么后两行显示奇怪的符号。它是一个替换字符(replacement character),是称为 specials Unicode 区段的一员。它的编码为 \uFFFD ( 更多信息)
对 strings 的简要介绍
Strings 基本上是字节的切片:
text := "abł"
for i := 0; i < len(text); i++ {
fmt.Println(text[i])
}
输出:
97
98
197
130
97 和 98 是 UTF-8 编码的 “a” 和 “b“ 字符。第三和第四行的输出是字符 “ł” 的 UTF8 编码,该编码占据了两个字节的空间。
range 循环有助于迭代 Unicode 定义的码位( 码位在 Golang 中被称为 rune )
text := "abł"
for _, s := range text {
fmt.Printf("%q %#v\n", s, s)
}
输出:
'a' 97
'b' 98
'ł' 322
想了解更多类似 %q 和 %v 这样的占位符,可以看 fmt 包的文档
更多的讨论可在 《Golang的字符串,字节,rune 和字符》。在这个快速解释之后,在字符串和字节切片之间的转换应该不会再难以理解。
string ↔ slice of bytes
bytes := []byte("abł")
text := string(bytes)
fmt.Printf("%#v\n", bytes) // []byte{0x61, 0x62, 0xc5, 0x82}
fmt.Printf("%#v\n", text) // "abł"
切片由被转换 string 的 utf8 编码字节组成。
string ↔ slice of runes
runes := []rune("abł")
fmt.Printf("%#v\n", runes) // []int32{97, 98, 322}
fmt.Printf("%+q\n", runes) // ['a' 'b' '\u0142']
fmt.Printf("%#v\n", string(runes)) // "abł"
从被转换 string 中创建的切片是由 Unicode 编码的码位( rune )组成。
11.类型别名
如你所知, 类型别名(type aliases) 最终还是加入到Go 1.9中, Go 1.9 beta2今天已经发布了, 正式版预计8月初发布, 是时候深入了解一下它的新特性了,本文介绍的就是它的重要的新特性之一: 类型别名。
当然,如果你想尝试这些新特性,需要安装Go 1.9的版本,目前是beta2版,可以在官方网站下载。
类型别名主要解决什么问题,为什么需要这个特性? Russ Cox 的论文Codebase Refactoring (with help from Go)介绍了它的背景。类型别名主要用在:
- 在大规模的重构项目代码的时候,尤其是将一个类型从一个包移动到另一个包中的时候,有些代码使用新包中的类型,有些代码使用旧包中的类型, 比如
context - 允许一个庞大的包分解成内部的几个小包,但是小包中的类型需要集中暴漏在上层的大包中
类型别名
类型别名的语法如下:
1 |
type identifier = Type |
它和类型定义(type definition)类似,仅仅是在identifier和Type之间加了一个等号=,但是和类型定义区别很大,这一点会在后面专门比较。
下面这个例子就是为字符串string类型定义了一个别名S,你可以声明变量、常量为S类型,将字符串赋值给它,它和字符串类型几乎一模一样。
1 2 3 4 5 6 7 8 9 10 |
package main import "fmt" type S = string func main() { var s S = "hello world" fmt.Println(s) } |
当然, 你可以为任意的类型定义类型别名,语言规范中没有限制,可以为数组、结构体、指针、函数、接口、Slice、Map、Channel定义别名,甚至你还可以为通过类型定义(type definition)的类型定义别名,更甚者是你可以为别名定义别名。
比如下面这个例子, 为函数类型func()定义了一个别名F:
1 2 3 4 5 6 7 8 9 10 11 12 13 |
package main import "fmt" type F = func() func main() { var foo F = func() { fmt.Println("hello type aliases") } foo() } |
又如下面的代码,为interface{}定义了别名G:
1 2 3 4 5 6 7 8 9 10 |
package main import "fmt" type G = interface{} func main() { var g G = "hello world" fmt.Println(g) } |
类型别名还可以为其它包中的类型定义别名,只要这个类型在其它包中是exported的:
1 2 3 4 5 6 7 8 9 10 11 12 13 |
package main import ( "fmt" "time" ) type MyTime = time.Time func main() { var t MyTime = time.Now() fmt.Println(t) } |
类型命名和类型声明的区别
记住下面一句话:
类型别名和原类型完全一样,只不过是另一种叫法而已
这句话隐藏着很多的智慧,你可以慢慢体会。
完全一样(identical types)意味着这两种类型的数据可以互相赋值,而类型定义要和原始类型赋值的时候需要类型转换(Conversion T(x))。
下面这个例子中,v是整数类型,可以直接赋值给d,因为d的类型是D,是是整数的别名。而var i I = v这一句会出错,因为I和整数是两个类型。
所以类型别名和类型定义最大的区别在于:类型别名和原类型是相同的,而类型定义和原类型是不同的两个类型。
1 2 3 4 5 6 7 8 9 10 |
package main type D = int type I int func main() { v := 100 var d D = v var i I = v } |
比如类型定义type Tnamed Tunderlying,系列类型和组合类型是不同的:
Tnamed和Tunderlying*Tnamed和*Tunderlyingchan Tnamed和chan Tunderlyingfunc(Tnamed)和func(Tunderlying)interface{ M() Tnamed }和interface{ M() Tunderlying }
但是对于别名type T1 = T2,下列类型和组合类型是相同的:
T1和T2*T1和*T2chan T1和chan T2func(T1)和func(T2)interface{ M() T1 }和interface{ M() T2 }
还有一个重要的区别在于类型定义的类型的方法集和原始类型的方法集没有任何关系,而类型别名和原始类型的方法集是一样的,下面再介绍。
既然类型别名和原类型是相同的,那么在`switch - type中,你不能将原类型和类型别名作为两个分支,因为这是重复的case:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
package main import "fmt" type D = int func main() { var v interface{} var d D = 100 v = d switch i := v.(type) { case int: fmt.Println("it is an int:", i) // case D: // fmt.Println("it is D type:", i) } } |
类型循环
类型别名在定义的时候不允许出现循环定义别名的情况,如下面所示:
1 2 |
type T1 = T2 type T2 = T1 |
上面的例子太明显,下面这个例子比较隐蔽,也是循环定义类型别名的情况,当然这些在编译代码的时候编译器会帮你检查,如果出现循环定义的情况会出错。
1 2 3 4 5 |
type T1 = struct { next *T2 } type T2 = T1 |
可导出性
如果定义的类型别名是exported (首字母大写)的,那么别的包中就可以使用,它和原始类型是否可exported没关系。也就是说,你可以为unexported类型定义一个exported的类型别名,如下面的例子:
1 2 3 4 5 |
type t1 struct { S string } type T2 = t1 |
方法集
既然类型别名和原始类型是相同的,那么它们的方法集也是相同的。
下面的例子中T1和T3都有say和greeting方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
type T1 struct{} type T3 = T1 func (t1 T1) say(){} func (t3 *T3) greeting(){} func main() { var t1 T1 // var t2 T2 var t3 T3 t1.say() t1.greeting() t3.say() t3.greeting() } |
如果类型别名和原始类型定义了相同的方法,代码编译的时候会报错,因为有重复的方法定义。
另一个有趣的现象是 embedded type, 比如下面的例子, T3是T1的别名。在定义结构体S的时候,我们使用了匿名嵌入类型,那么这个时候调用s.say会怎么样呢? 实际是你会编译出错,因为s.say`不知道该调用s.T1.say还是s.T3.say`,所以这个时候你需要明确的调用。
1 2 3 4 5 6 7 8 9 10 11 12 13 |
type T1 struct{} type T3 = T1 func (t T1) say(){} type S struct { T1 T3 } func main() { var s S s.say() } |
进一步想,这样是不是我们可以为其它库中的类型增加新的方法了, 比如为标准库的time.Time增加一个滴答方法:
1 2 3 4 5 6 7 8 9 |
type NTime = time.Time func (t NTime) Dida() { fmt.Println("嘀嗒嘀嗒嘀嗒嘀嗒搜索") } func main() { t := time.Now() t.Dida() } |
答案是: NO, 编译的时候会报错: cannot define new methods on non-local type time.Time。
byte 和 rune 类型
在Go 1.9中, 内部其实使用了类型别名的特性。 比如内建的byte类型,其实是uint8的类型别名,而rune其实是int32的类型别名。
1 2 3 4 5 6 7 8 |
// byte is an alias for uint8 and is equivalent to uint8 in all ways. It is // used, by convention, to distinguish byte values from 8-bit unsigned // integer values. type byte = uint8 // rune is an alias for int32 and is equivalent to int32 in all ways. It is // used, by convention, to distinguish character values from integer values. type rune = int32 |