具体分工
我主要负责C++,他负责爬虫部分
PSP表格

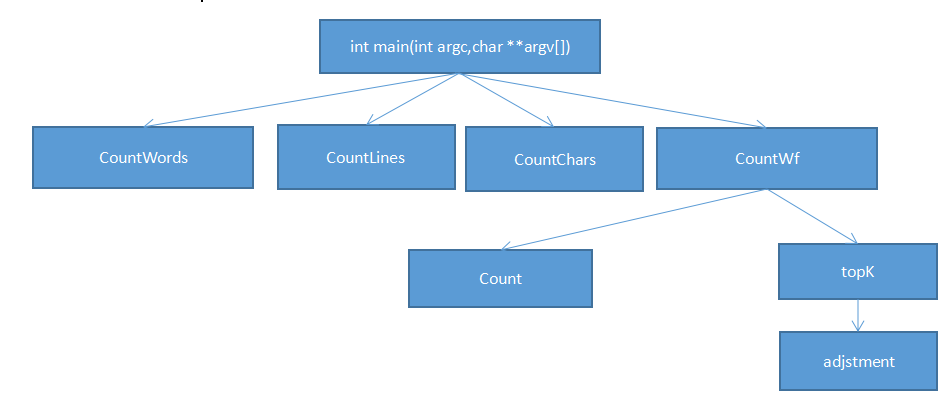
解题思路描述与设计实现说明
代码的核心思路是利用爬虫,爬取论文网址,之后吧对应信息(标题和摘要)写入文件,然后利用上次的WordCount代码把文件读进去然后进行分析,并且要加上权重分析,之后便是统计词频,然后这次的作业还新加了一个功能叫做词项统计,在不断询问大佬之后,大佬说用队列容器,把检测到的合法单词压入队尾,如果单词不合法就清空,确认词项之后再输出队列。
1.爬虫
爬虫爬取论文地址
#定义一个函数,用来爬取网页内容
def Web(www):
try:
w = requests.get(www)
w.raise_for_status()
w.encoding = w.apparent_encoding
except:
print("fail!!!")
temp = w.text
wz = BeautifulSoup(temp,"html.parser")
return wz
www = "http://openaccess.thecvf.com/CVPR2018.py"
wz = getWeb(www)简单处理一下标签,获取标题和摘要,然后写入文件
#定义一个函数,用来论文页面内容
def info(paperLink):
www = "http://openaccess.thecvf.com/" + paperLink
wz = Web(www)
#标签
bq=re.compile('</?\w+[>]*>')
#消除
title =bq.sub('', str(wz.find('div',id="papertitle"))).strip()
abstract = bq.sub('',str(wz.find('div',id="abstract"))).strip()
return title,abstract2.代码组织与内部实现设计
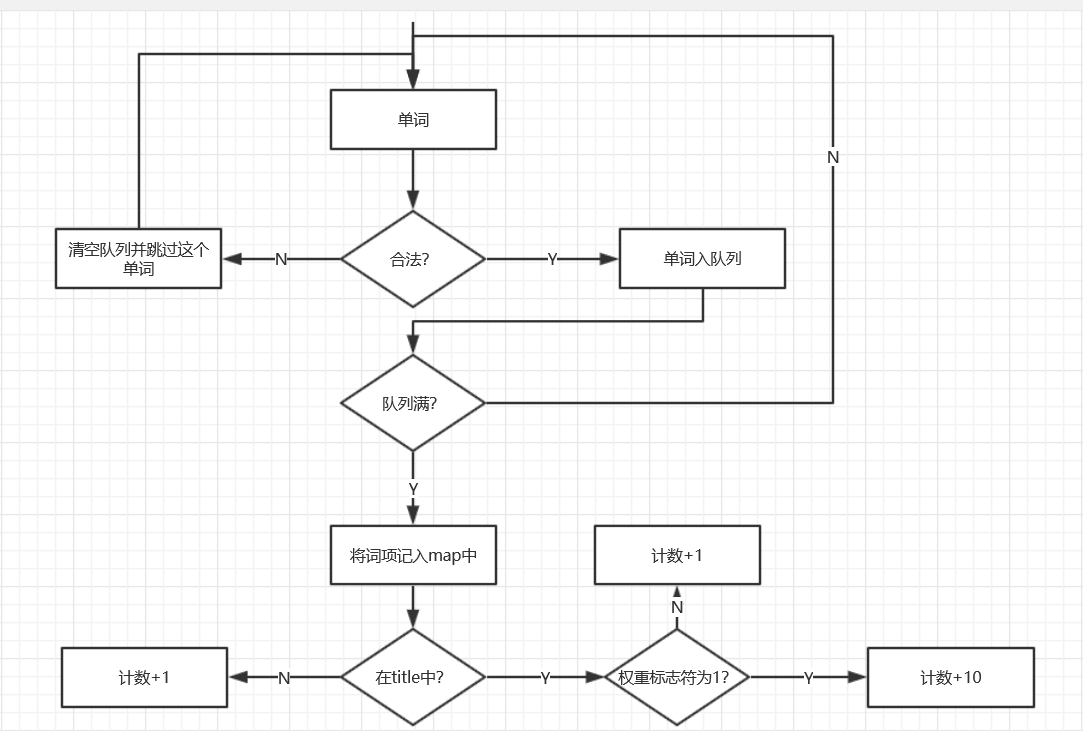
3.算法的关键与关键实现部分流程图
void Count(string tline, int maxn, int start,int quanzhong)
{
for (int i = start; i < tline.length(); i++)
{
int count = 0;//计数
int charcounts = 0;//字符数
int numflag = 0;//判断是否数字
for (int k = i;; k++)//判断是否是单词
{
if (tline[k] >= 'a'&&tline[k] <= 'z'&&numflag == 0)
{charcounts++;count++;}//小写字母
else if (tline[k] >= 'A'&&tline[k] <= 'Z'&&numflag == 0)
{charcounts++;count++;}//大写字母
else if (tline[k] >= '0'&&tline[k] <= '9')
{count++;numflag = 1;}//出现数字
else break;
}
if (charcounts >= 4) //记录
{ char words[100] = { "\0" };
//存储单词
for (int k = i; k < i + count; k++)
{
words[k - i] = tline[k];
}
string s = words;
b.push_back(s);
s = "\0";
if (b.size() == maxn)//队列以满
{
int nowNum = maxn;
for (it1 = b.begin(); it1 != b.end(); it1++)
{
s.append(*it1);
nowNum=nowNum-1;
if (nowNum != 0)s.append(" ");
}
if(start==7&&quanzhong==1)essay[s]+=10;//记录
else essay[s]++;
b.pop_front();
s = "\0";
}
i += count - 1;
}
else if (count > 0 && count < 4)
{
b.clear();
i += count - 1;
}
else continue;
}
if (start == 7)b.clear();//清空
}
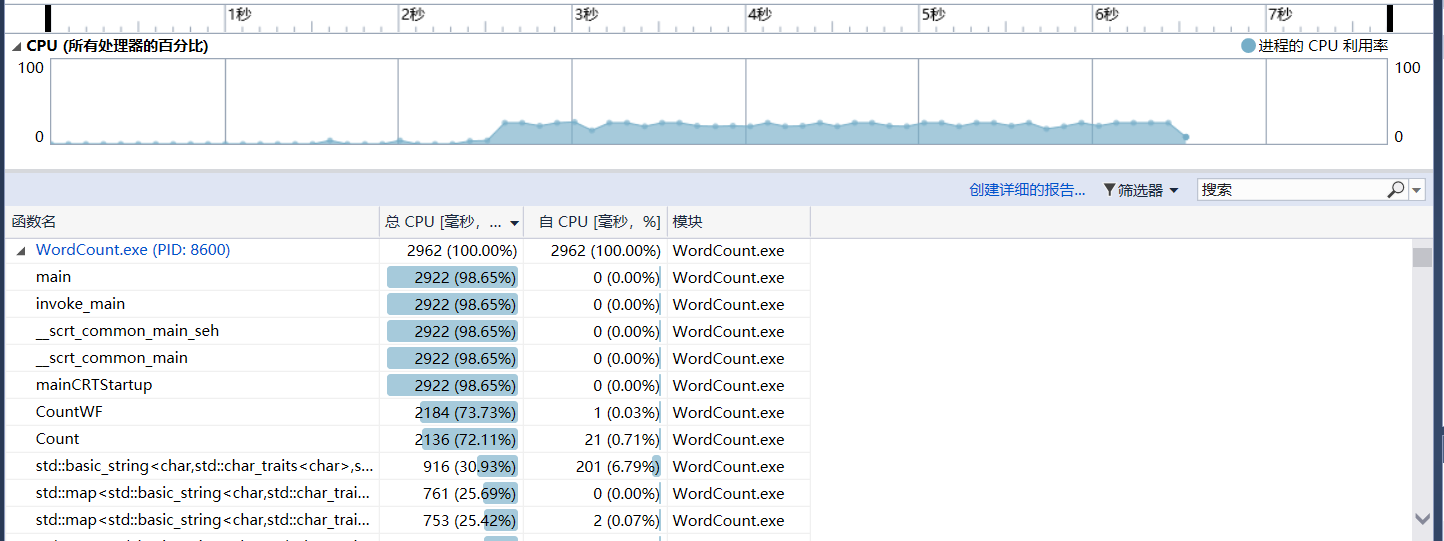
性能分析
测试文本为100w+字符数,花费时间在3s左右,运行结果如下:

VS的性能分析工具结果
遇到的代码模块异常或结对困难及解决方法
•问题描述:C++程序无法读取爬虫的结果文件然后程序崩溃
•做过的尝试: ◦发现爬虫文件为Unicode编码,C++无法识别,所以将文本改为Ascll编码(没有解决)
◦发现读取的文本Abstract字段不管有多少行都算作一行,尝试自动添加换行符解决(失败)
◦最后发现是C++程序中读取每行使用的Char[]容量过小无法读取Abstarct的全部内容导致崩溃,通过增大容量解决(暂时成功)
•通过各种尝试终于解决啦
•收获:细节决定成败。。。但是其实盲目增大容量的做法是很不可取的,改为动态开辟空间应该会好很多。
评价你的队友
真•大佬,敦厚的专业水平值得学习
只是埋头苦干需要改进,应增加沟通
学习进度条
| Skills/技能 | 课前评估 (0..9) | 课后评估 (0..9) |
|---|---|---|
| Programming Overall | 5 | 7.5 |
| Programming:Comprehension | 3 | 6.5 |
| Programming:Test | 0 | 6.5 |
| Programming:Design | 2 | 6.5 |
| Programming:Code Review/Code Quality | 1 | 6.5 |