软工结对作业之词频统计plusplus
1. 分工明细
- 031602509 董钧昊:Java爬虫的设计,附加题的设计
- 031602523 刘宏岩:升级优化WordCount的功能,命令函参数得使用
2. PSP表格
| psp2.1 | personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 10 | 10 |
| Estimate | 估计这个任务需要多少时间 | 10 | 10 |
| Development | 原型开发 | 600 | 900 |
| Analysis | 需求分析(包括学习新技术) | 60 | 120 |
| Design Spec | 生成设计文档 | 60 | 60 |
| Design Review | 设计复审 | 20 | 150 |
| Coding Standrd | 代码规范(为目前的开发制定合适的规范) | 15 | 15 |
| Design | 具体设计 | 60 | 180 |
| Coding | 具体编辑 | 180 | 180 |
| Code Review | 代码复审 | 120 | 120 |
| Test | 测试(自我测试,修改代码,提交修改) | 30 | 30 |
| Reporting | 报告 | 210 | 300 |
| Test Repor | 测试报告 | 30 | 45 |
| Size Measurement | 计算工作量 | 10 | 15 |
| Postmortem&Process Improvement Plan | 事后总结,并提出过程改进计划 | 20 | 15 |
| - | 合计 | 1435 | 2150 |
3. 学习进度条
| 第N周 | 新增代码(行) | 累计代码(行) | 本周学习耗时(小时) | 累计学习耗时(小时) | 重要成长 |
|---|---|---|---|---|---|
| 1 | 300 | 300 | 18 | 18 | 原型设计,爬虫关于python的urllib库及request库学习 |
| 2 | 0 | 300 | 8 | 26 | 钢铁直男们的审美进步“一点点” |
| 3 | 500 | 800 | 12 | 38 | Java爬虫、 |
4. 设计思路及实现流程
- 仔细阅读了作业文档后,总结了本次作业的两点要求:
- 爬取数据,并按照格式生成result.txt
- 升级第一次作业的WordCount,满足各种新增需求
- 有些功能在上次个人作业中已经说明,所以本次作业就不赘述了,要心疼一下我们两位可爱的助教小姐姐~
4.1 Java爬虫
4.2 代码组织与内部实现设计(类图)
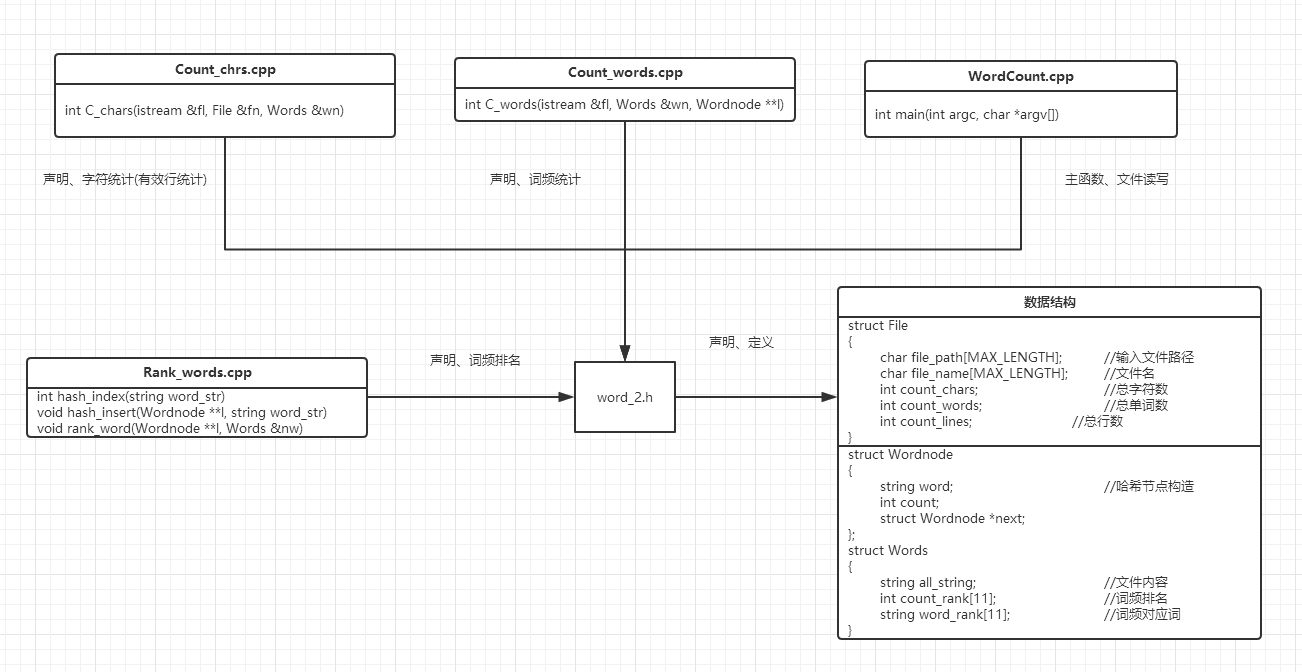
- 和上次个人作业没有很大区别,只是在其基础上修改了几个函数。
| 模块 | 备注 |
|---|---|
| work_2.h | 包含头文件、数据结构以及用到函数的声明 |
| Count_chrs.cpp | 统计字符数模块(也包含行数的统计) |
| Count_words.cpp | 统计单词、词组数模块(结果计入hashmap) |
| Rank_words.cpp | 词频、词组字典序导出模块,用于实现hashmap |
| WordCount.cpp | 主函数 |
4.3 命令行解析
4.4 w—权重统计
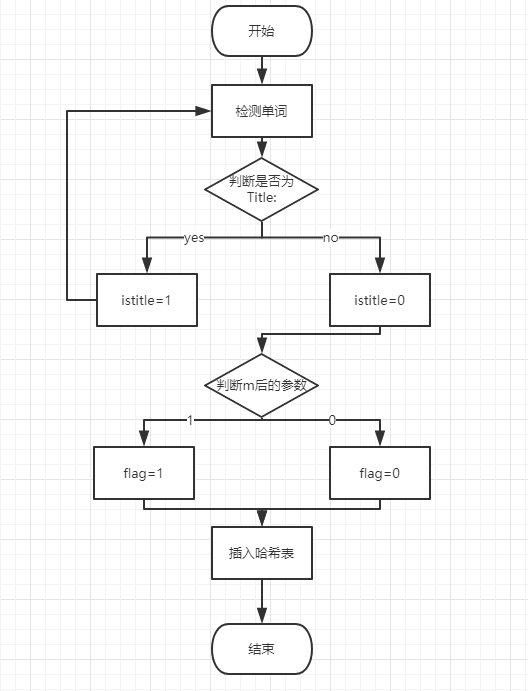
- 标题中的单词(词组)在统计时算出现十次,摘要中的单词(词组)在统计时算出现一次。
- 实现这个功能关键就是区分标题和摘要,我们的思路是:
在提取单词时,通过单词
Title:和Abstract:来检测,并设置一个开关istitle。当检测到Title:时,置istitle为1,表示在此状态下提取出的单词(词组)都属于标题部分。否则置为0,表示在此状态下提取出的单词(词组)都属于摘要部分。这样就把单词(词组)用标题和摘要区分开啦!
当然光有这些还不够,还要根据w后的参数来判断是否需要权重功能。敲重点!!!当istitle和w后的参数同时为1时,才能把标题中的单词(词组)按照10计数。否则不管是标题还是摘要中的单词(词组),都只能按照1计数。
因为我们采用了哈希的方法统计频,所以只要在插入哈希表的函数上稍作改动即可,即增加一个开关flag,当需要计数10次时置flag=1,插入结点的times值置为10,否则flag=0插入结点的times值置为1。
- 本模块的流程图:
- 贴上关键代码,关键处用注释解释:
//istitle开关部分
if (temp_word == "title"&&temp_line[k] == ':'&&k <= temp_line.size())
{
fn.count_chars = fn.count_chars - 7;
count_words--; //title不算有效单词
istitle = 1; //表示目前处于标题状态
wordbuf.clear(); //标题和摘要状态切换时,清空队列因为词组不能跨越二者
k += 2; //跳过“: ”
continue; //获取下一个单词
}
if (temp_word == "abstract"&&temp_line[k] == ':'&&k <= temp_line.size())
{
fn.count_chars = fn.count_chars - 10;
count_words--; //title不算有效单词
istitle = 0; //表示目前处于标题状态
wordbuf.clear(); //标题和摘要状态切换时,清空队列因为词组不能跨越二者
k += 2; //跳过“: ”
continue; //获取下一个单词
}//插入函数
void hash_insert(Wordnode **l, string word_str,int weight_flag)
{
int value = hash_index(word_str); //计算哈希值
Wordnode *p;
//cout << value;
for (p = l[value]; p != NULL; p = p->next) //查找节点并插入
{
if (word_str == p->word) //已有节点存在(重复单词)
{
p->count += 1 + weight_flag * 9;
return;
}
}
p = new Wordnode; //未有节点存在(新单词)
p->count = 1 + weight_flag * 9;
p->word = word_str;
p->next = l[value];
l[value] = p;
}
//带权重的插入部分
if (istitle == 1 && fn.weight == 1)
{
hash_insert(l, temp_comb,1); //插入10次
}
else
{
hash_insert(l, temp_comb,0); //插入1次
}4.5 m—词组统计
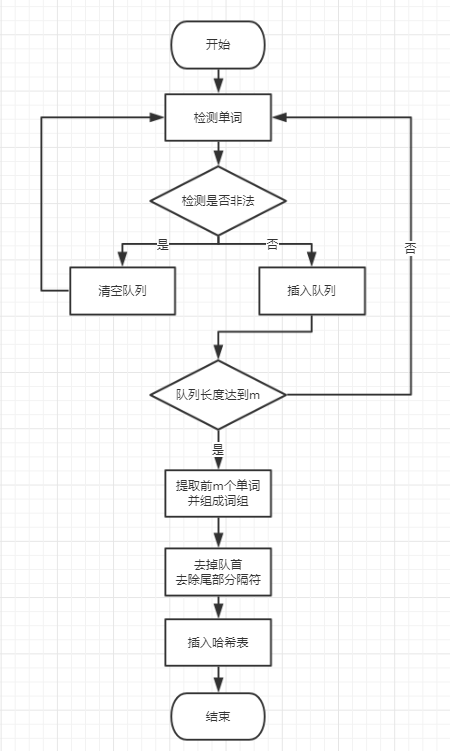
- 本参数要求根据m后的参数,统计对应长度的词组词频。
- 我们总结了几个要点:
- 如何提取对应长度的词组
- 准确并完整的提取单词之间的分隔符
- 如何避免非法单词的干扰(数字,the、we等)
- 避免跨越标题和摘要提取单词组成词组
- 以下是我们的思路:
首先定义短单词、数字开头的单词、
Tiltle和Abstract为非法单词,其余为合法单词 。
在提取词组时,首先就是连续提取m个单词。我们采用了队列的思想。每当提取出一个单词时连同它后面的所有分隔符组成一个string型变量进入队列。然后判断队列中的合法单词数目,如果等于m,就创建一个临时的空的string型变量,用它去连接队列中的前m个合法单词。然后去掉连接后所得字符串后面的所有分隔符,最后插入哈希表,并弹出队首单词。这样我们就取得了完整的分隔符。
要去除非法单词的干扰,只需在检测到非法单词时清空队列即可。因为队列中的单词数目不足m且不能后后面进来的单词组合成词组。
要去除Tiltle和Abstract的干扰,每当我们检测到这两个单词时采用continue忽略,并清空队列,因为队列中的单词数目不足m且不能后后面进来的单词组合成词组。所以我们要清空队列,防止跨越标题和摘要提取单词组成词组。
- 本部分流程图:
- 贴出关键代码,关键处用注释解释:
//词组统计函数
if (temp_chr <= '9'&&temp_chr >= '0')
{
k++; //数字开头判断
while (k <= temp_line.size() - 1 && ((temp_line[k] <= '9'&&temp_line[k] >= '0') || (temp_line[k] <= 'z'&&temp_line[k] >= 'a')))
{
k++;
}
wordbuf.clear(); //数字开头,清空队列
}
else if (temp_chr <= 'z' && temp_chr >= 'a')
{
temp_word = "";
temp_word += temp_chr; //字符补足
//cout<<temp_word<<endl;
k += 1;
if (temp_line.size() - 2 > k) //判断余下位数是否够装下一个单词
{
while (k < temp_line.size() && ((temp_line[k] <= 'z' && temp_line[k] >= 'a') || (temp_line[k] <= '9' && temp_line[k] >= '0')))
{
temp_word += temp_line[k];
//cout << temp_word << endl;
k += 1;
}
//wordbuf.clear();
}
//检测到合法单词
if (3 < temp_word.size() && (temp_word[0] <= 'z'&&temp_word[0] >= 'a') && (temp_word[1] <= 'z'&&temp_word[1] >= 'a') && (temp_word[2] <= 'z'&&temp_word[2] >= 'a') && (temp_word[3] <= 'z'&&temp_word[3] >= 'a'))
{
count_words++;
if (temp_word == "title"&&temp_line[k] == ':'&&k <= temp_line.size())
{
fn.count_chars = fn.count_chars - 7;
count_words--; //title不算有效单词
istitle = 1; //表示目前处于标题状态
wordbuf.clear(); //标题和摘要状态切换时,清空队列因为词组不能跨越二者
k += 2; //跳过“: ”
continue; //获取下一个单词
}
if (temp_word == "abstract"&&temp_line[k] == ':'&&k <= temp_line.size())
{
fn.count_chars = fn.count_chars - 10;
count_words--; //title不算有效单词
istitle = 0; //表示目前处于标题状态
wordbuf.clear(); //标题和摘要状态切换时,清空队列因为词组不能跨越二者
k += 2; //跳过“: ”
continue; //获取下一个单词
}
if (fflag == 1) //只统计词组
{
int thischar = k;
//连接单词后的分隔符
while (isdivide(temp_line[thischar]) && thischar < temp_line.size())
{
temp_word = temp_word + temp_line[thischar];
thischar++;
}
wordbuf.push_back(temp_word); //进入队列
if (wordbuf.size() == len) //长度满足要求
{
for (int i = 0; i < len; i++)
{
temp_comb += wordbuf[i];
}
wordbuf.erase(wordbuf.begin()); //第一个单词清空
while (isdivide(temp_comb[temp_comb.length() - 1])) //去除最后的分隔符
{
temp_comb = temp_comb.substr(0, temp_comb.length() - 1);
}
if (istitle == 1 && fn.weight == 1)
{
hash_insert(l, temp_comb,1);
}
else
{
hash_insert(l, temp_comb,0);
}
temp_comb = "";
}
}
else //只统计单词
{
if (istitle == 1 && fn.weight == 1)
{
hash_insert(l, temp_word,1);
}
else
{
hash_insert(l, temp_word,0);
//cout << temp_word << endl;
}
temp_word = "";
}
}
else //遇见短单词
{
wordbuf.clear(); //清空队列
}
}5. 性能分析与改进
- 使用爬取获得的
result.txt,参数为WordCount.exe -i result.txt -o output.txt -m 3 -n 10 -w 1,性能测试结果如下图:
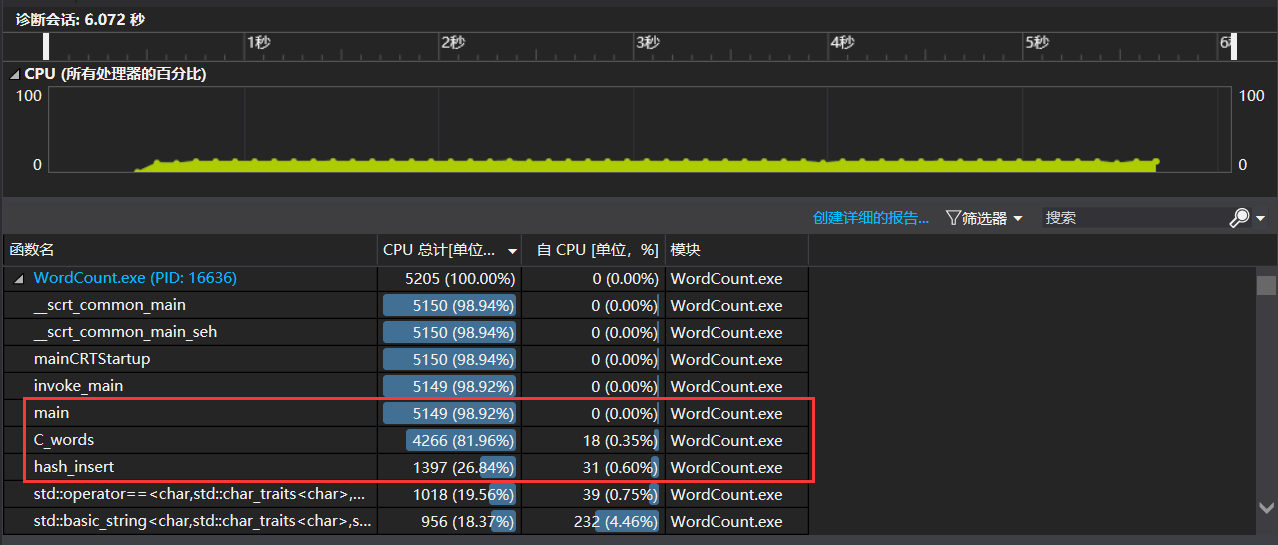
- 可以看出消耗最大的函数为C_words()函数,因为该函数执行单词提取和词组拼接的操作,占用的大部分的CPU时间。
6. 代码覆盖率测试
- 使用
Run OpenCppCoverage工具测试了本次作业程序的代码覆盖率,结果如下图所示:

- 可以看出覆盖率较低的模块为main函数和count_char函数,原因如下:
- main函数中加入了许多异常检测代码段,比如文件打开失败检测等,导致覆盖率降低。
- count_char函数中,为了方便统计单词,我们把文档事先都转化为小写字母,由于爬取结果中大写字母数目很少,所以导致大小写转换的函数的使用率不高,代码覆盖率降低。