1 特征筛选
数据集:Titanic数据集;
通过特征筛选来寻找最佳的特征组合,并且达到提高预测准确性的目标
2 实验代码及结果截图
#coding:utf-8
#数据导入
import pandas as pd
titanic=pd.read_csv('http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt')
#分离数据特征和预测目标
y=titanic['survived']
x=titanic.drop(['row.names','name','survived'],axis=1)
#对确是数据进行填充
x['age'].fillna(x['age'].mean(),inplace=True)
x.fillna('UNKNOWN',inplace=True)
#分割数据
from sklearn.cross_validation import train_test_split
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.25,random_state=33)
#类别型特征向量化
from sklearn.feature_extraction import DictVectorizer
vec=DictVectorizer()
x_train=vec.fit_transform(x_train.to_dict(orient='record'))
x_test=vec.transform(x_test.to_dict(orient='record'))
#输出处理后特征向量的维度
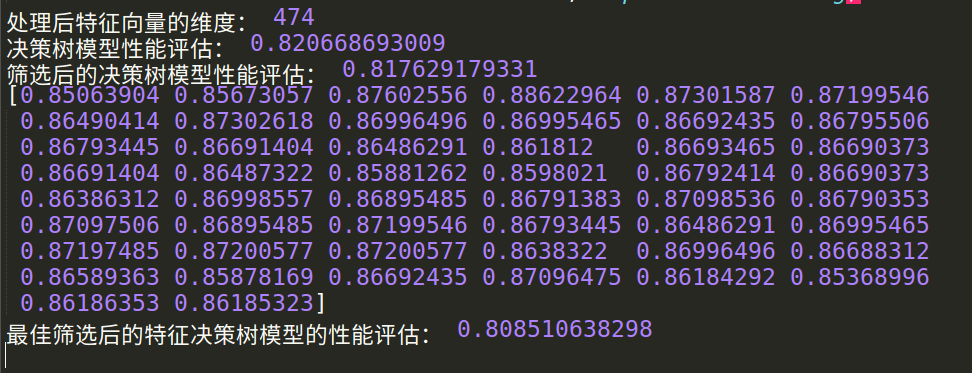
print '处理后特征向量的维度:',len(vec.feature_names_)
#使用决策树模型依靠所有特征进行预测,并做性能评估
from sklearn.tree import DecisionTreeClassifier
dt=DecisionTreeClassifier(criterion='entropy')
dt.fit(x_train, y_train)
print '决策树模型性能评估:',dt.score(x_test,y_test)
#导入特征筛选器
from sklearn import feature_selection
#筛选前20%的特征,使用相同配置的决策树模型进行预测,并进行性能评估
fs=feature_selection.SelectPercentile(feature_selection.chi2,percentile=20)
x_train_fs=fs.fit_transform(x_train,y_train)
dt.fit(x_train_fs, y_train)
x_test_fs=fs.transform(x_test)
print '筛选后的决策树模型性能评估:',dt.score(x_test_fs,y_test)
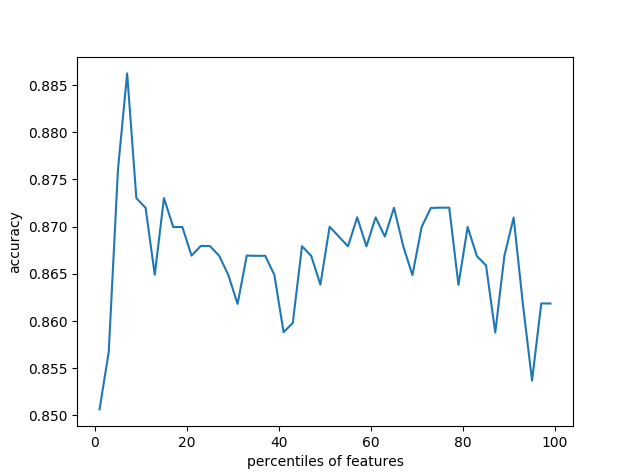
#通过交叉验证的方法,按照固定间隔的百分比筛选特征,并做图展示性能随特征筛选比例的变化
from sklearn.cross_validation import cross_val_score
import numpy as np
percentles=range(1,100,2)
results=[]
for i in percentles:
fs=feature_selection.SelectPercentile(feature_selection.chi2,percentile=i)
x_train_fs=fs.fit_transform(x_train,y_train)
scores=cross_val_score(dt,x_train_fs,y_train,cv=5)
results=np.append(results,scores.mean())
print results
#使用最佳筛选后的特征,利用相同配置的模型在测试集上进行性能评估
from sklearn import feature_selection
FS=feature_selection.SelectPercentile(feature_selection.chi2,percentile=7)
x_train_fs=fs.fit_transform(x_train,y_train)
dt.fit(x_train_fs, y_train)
x_test_fs=fs.transform(x_test)
print '最佳筛选后的特征决策树模型的性能评估:',dt.score(x_test_fs,y_test)
#作图
import pylab as pl
pl.plot(percentles,results)
pl.xlabel('percentiles of features')
pl.ylabel('accuracy')
pl.show()