文章首发于微信公众号《与有三学AI》
【模型解读】network in network中的1*1卷积,你懂了吗
02 这是深度学习模型解读第二篇,本篇我们将介绍Network InNetwork。
Network In Network 是发表于2014年ICLR的一篇paper。这篇文章采用较少参数就取得了Alexnet的效果,Alexnet参数大小为230M,而Network In Network仅为29M,这篇paper主要两大亮点:
01 提出MLP卷积层
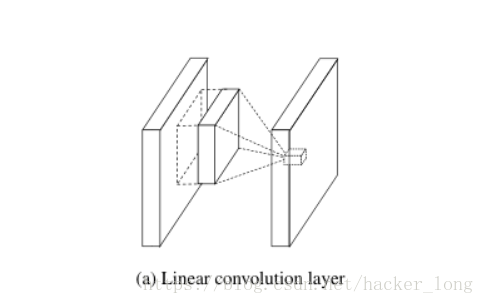
下图是传统卷积结构:
使用relu的一个非线性变换操作为:
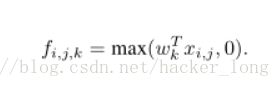
i,j表示像素下标,xi,j表示像素值,wk表示卷积参数,k就是下标的索引。
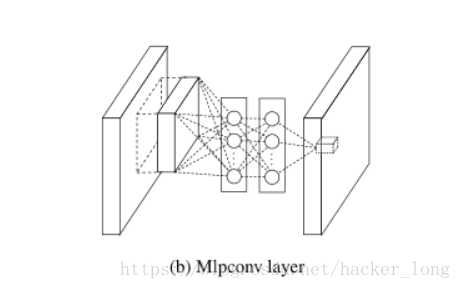
MLP卷积层结构如下图:

mlpconv层的计算公式为:
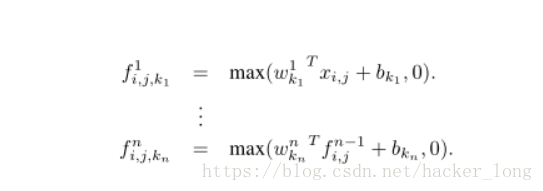
i,j表示像素下标,xi,j表示像素值,wk,n表示第n层卷积卷积参数。
从以上可以看出,MLP卷积层通过叠加"micro network"网络,提高非线性表达,而其中的"micro network"基本组成单元是1*1卷积网路,说到这,就要解释一下1*1卷积了,该篇论文是首次提出1*1卷积,具有划时代的意义,之后的Googlenet借鉴了1*1卷积,还专门致谢过这篇论文。
1*1卷积的意义:
1. 实现了不同通道同一位置的信息融合
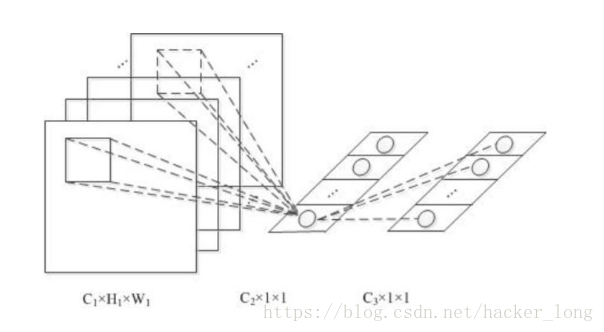
如上图,C2融合了C1不同通道同一位置的信息。
2. 可以实现通道数的降维或升维
1*1*n,如果n小于之前通道数,则实现了降维,如果n大于之前通道数,则实现了升维。
02 用全局均值池化代替全连接层
首先让我们看下Network In Network的网络结构,如下图。
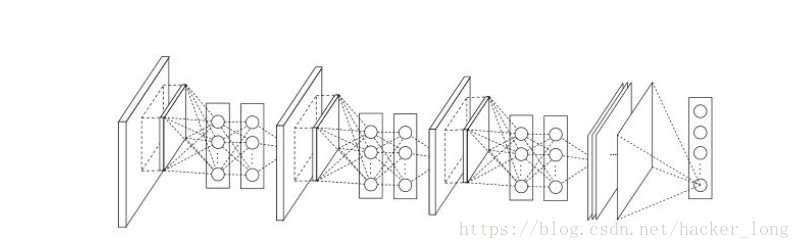
上图看出,该网络结构有三个MLP卷积层组成,每个MLP卷积层分别是一个普通卷积,加两个1*1卷积。以1000分类为例,最后一个1*1卷积输出的featuremap大小为6*6*1000。之后每个featuremap采用全局均值池化,输出1000个分类。由于没有全连接的大量参数,使用全局均值池化不需要参数,极大的降低了参数量。
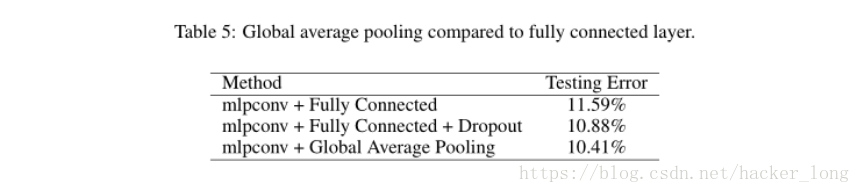
如下图是在CIFAR-10 数据集中 Global average pooling 和 fully connected测试对比图, 从下图可以看出无参数的Global average pooling层 相比较于有参数的全连接层错误率更低。
03 总结
Network In Network通过创新的创建MLP卷积层,提高了网络的非线性表达同时降低了参数量,用全局均值池化代替全连接层,极大的降低了参数量。
参考文献
Lin M, Chen Q, Yan S. Network In Network[J]. Computer Science, 2014
同时,在我的知乎专栏也会开始同步更新这个模块,欢迎来交流
https://zhuanlan.zhihu.com/c_151876233
注:部分图片来自网络
—END—
打一个小广告,我在gitchat开设了一些课程和chat,欢迎交流。