版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/lvxiangyu11/article/details/81151135
代码我都加上注释了,耐心看完就行了,23333。不是作者菜,是没耐心看完代码。作者就是菜!!
/*
这段代码由lvxiangyu11编写,转载请注明出处。https://blog.csdn.net/lvxiangyu11
*/
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
#include<iostream>
#include<vector>
#include<ctime>
//偷懒定义一些东西方便下面缩减代码
#define TYPENAME int
#define NUM 2000000
#define c_size_ sizeof(TYPENAME)*NUM
#define ll long long
using namespace std;
cudaError_t addWithCuda(int *c, const int *a, const int *b, ll size);
//单block单thread向量加
__global__ void addWithGpu_ss(TYPENAME *a, TYPENAME *b, TYPENAME *c, unsigned int n) {
for (ll i = 0; i < n; i++) {
c[i] = a[i] + b[i];
}
}
//d_映射显存
TYPENAME a[NUM] = { 1,2,3,4 }, b[NUM] = { 0 }, c[NUM] = { 0 };
//单block多thread向量加
__global__ void addWithGpu_sm(TYPENAME *a, TYPENAME *b, TYPENAME *c, unsigned int n) {
int tid = threadIdx.x;//在kernel函数中用threaIDx.x获得线程索引号
const int t_n = blockDim.x;//线程索引号做步长
while (tid < n) {
c[tid] = a[tid] + b[tid];
tid += t_n;//反正这里是单层的,对吧?
}
}
//多block单thread向量加
__global__ void addWithGpu_mm(TYPENAME *a, TYPENAME *b, TYPENAME *c, unsigned int n) {
const int tidx = threadIdx.x;
const int bidx = blockIdx.x;
const int t_n = gridDim.x*blockDim.x;
int tid = bidx * blockDim.x + tidx;
while (tid < n) {
c[tid] = a[tid] + b[tid];
tid += t_n;
}
}
TYPENAME *d_a, *d_b, *d_c;
int main()
{
cudaError_t cudaStatus = cudaGetLastError();
//——————DEBUG_INIT——————
for (ll i = 0; i < NUM; i++) {
a[i] = b[i] = i;
}
//——————DEBUG_INIT————————
//显存申请
cudaMalloc((void**)&d_a, c_size_);
cudaMalloc((void**)&d_b, c_size_);
cudaMalloc((void**)&d_c, c_size_);
//内存搬运
cudaMemcpy(d_a,a, c_size_, cudaMemcpyHostToDevice);
cudaMemcpy(d_b,b, c_size_, cudaMemcpyHostToDevice);
//启动单block单thread向量加
//addWithGpu_ss << <1, 1 >> > (d_a, d_b, d_c, NUM);
//启单block多thread向量加
//addWithGpu_sm << <1, 1024 >> > (d_a, d_b, d_c, NUM);//block不超过1024个,GPU利用率下降,妙啊
//启多block多thread向量加
addWithGpu_mm << <1280, 1024 >> > (d_a, d_b, d_c, NUM);//这里block,thread的选择是根据什么来的?
//从显存中搬运结果
cudaMemcpy(c, d_c, c_size_, cudaMemcpyDeviceToHost);
//——————DEBUG_OUT——————
cudaStatus = cudaGetLastError();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "ERROR2:", cudaGetErrorString(cudaStatus));
cout << "ERROR:" << cudaGetErrorString(cudaStatus);
}else
{
//用cpu计算核对结果
for (ll i = 0; i < NUM; i++) {
if (c[i] != (a[i] + b[i])) {
cout << "计算错误,见鬼了!"<<endl;
return 0;
}
}
cout << "运算正确" << endl;
}
//——————DEBUG_OUT————————
//释放显存
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_c);
system("pause");
return 0;
}附送GPU结构图两张,便于理解block和thread
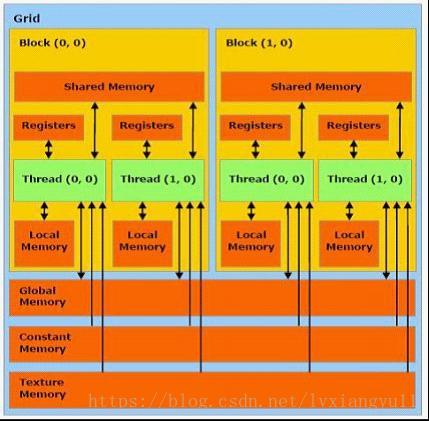

下面是我食用这三个栗子时的GPU
第一个:
第二三个都类似:

PS:本人穷鬼一个,买不起tesla计算卡,倾家荡产才搞来一个1060.。。。各位莫怪啊。QAQ谁能捐个计算卡给我,感激不尽