spark作为流行的计算框架,下面是其运行流程图,以Cluster模式为例
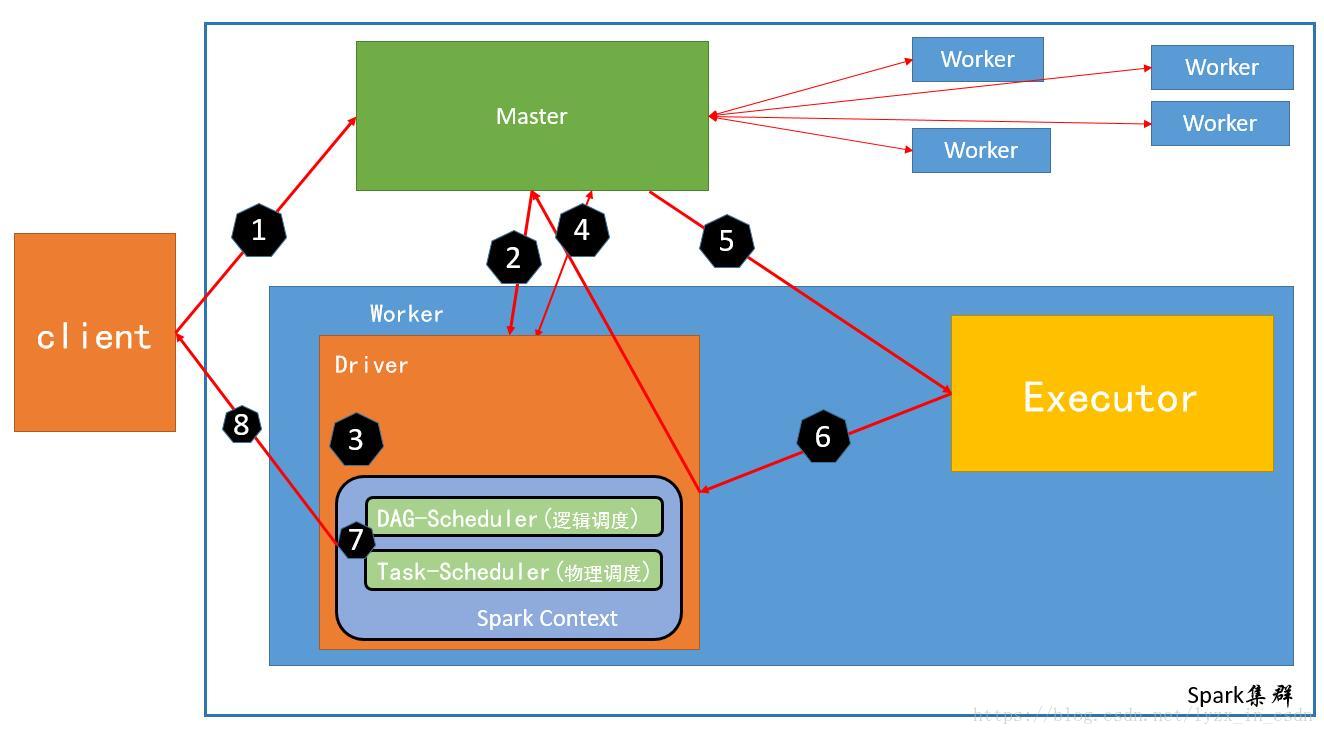
1、通过spark-submit的方式提交作业,此时应用程序向master发送请求启动Driver程序
Driver程序负责对资源和任务的调度
2、Master在资源充足的Worker上启动一个Driver进程
这里需要注意是Master找到资源充足的Worker并向其发送消息有Worker启动Driver进程
3、当Driver启动后,Driver就开始调度任务,首先初始化SparkContext
在初始化SparkContext时会产生两个重要的对象,1个是DAGSchedule另一个是TaskSchedule
首先是TaskSchedule的实现类 TaskScheduleImpl 由它负责具体的任务调度 (当然不同的任务调度由不同的实现类实现,后续文章会有介绍)
DAGSchedule负责任务的逻辑调度和stage切分
最后还会开启一个jetty的web服务,端口默认是4040,向外提供作业的web服务
此时算是SparkContext初始化完成
4、当Spark上下文初始化完成后就需要去执行具体的job即我们写的Spark代码,此时Driver会向Master申请资源(在启动任务时填写的资源)
5、Master找出资源充足的Worker并启动Executor (与Driver一样,Executor也是有Worker启动的)
6、当Executor启动完毕后会反向注册给 TaskScheduleImpl(给该app分配的executor不再经过Master而是直接到该APP对应的TaskScheduleImpl上注册)
7、此时整个Spark作业需要的资源就已经申请完成了
剩下的就是按照spark作业执行任务 有DAGSchedule切分Stage并封装为TaskSet
由TaskScheduleImpl拆分TaskSet并执行对应的任务
8、将执行的任务返回给客户端
总结:所谓的Master和Worker只是Spark内置资源调度框架中资源管理主节点和从节点的叫法,在yarn中叫ResourceManager和NodeManager。