背景
Connectionist temporal classification简称CTC,翻译不太清楚,可以理解为基于神经网络的时序类分类。其中classification比较好理解,表示分类问题;temporal可以理解为时序类问题,比如语音识别的一帧数据,很难给出一个label,但是几十帧数据就容易判断出对应的发音label,这个词也给出CTC最核心的意义;connectionist可以理解为神经网络中的连接。
语音识别声学模型的训练属于监督学习,需要知道每一帧对应的label才能进行有效的训练,在训练的数据准备阶段必须要对语音进行强制对齐。
CTC的引入可以放宽了这种一一对应的限制要求,只需要一个输入序列和一个输出序列即可以训练。有两点好处:不需要对数据对齐和一一标注;CTC直接输出序列预测的概率,不需要外部的后处理。
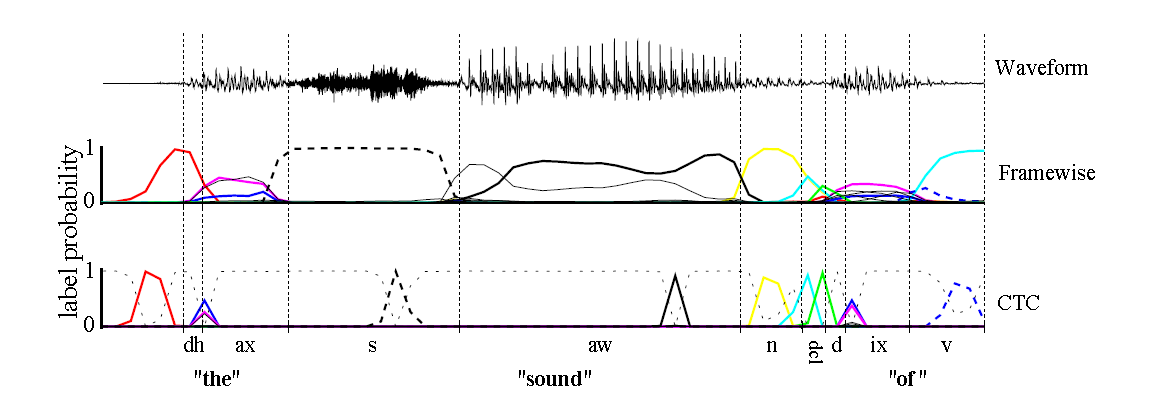
如上图,传统的Framewise训练需要进行语音和音素发音的对齐,比如“s”对应的一整段语音的标注都是s;而CTC引入了blank(该帧没有预测值),“s”对应的一整段语音中只有一个spike(尖峰)被认为是s,其他的认为是blank。对于一段语音,CTC最后的输出是spike的序列,不关心每一个音素对应的时间长度。
输出
语音识别中的DNN训练,每一帧都有相应的状态标记,比如有5帧输入x1,x2,x3,x4,x5,对应的标注分别是状态a1,a1,a1,a2,a2。
CTC的不同之处在于输出状态引入了一个blank,输出和label满足如下的等价关系:
多个输出序列可以映射到一个输出。
参考
《Supervised Sequence Labelling with Recurrent Neural Networks》 chapter7