原文链接:https://developers.google.com/machine-learning/crash-course/framing/ml-terminology
监督式机器学习定义如下:
- 机器学习系统通过学习如何组合输入信息来对从未见过的数据做出有用的预测。
基本术语:
标签
标签是我们要预测的事物,即简单线性回归中的 y 变量。标签可以是小麦未来的价格、图片中显示的动物品种、音频剪辑的含义或任何事物。
特征
特征是输入变量,即简单线性回归中的 变量。简单的机器学习项目可能会使用单个特征,而比较复杂的机器学习项目可能会使用数百万个特征,按如下方式指定:
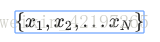
在垃圾邮件检测器示例中,特征可能包括:
- 电子邮件文本中的字词
- 发件人的地址
- 发送电子邮件的时段
- 电子邮件中包含“一种奇怪的把戏”这样的短语。
样本
样本是指数据的特定实例:x。(我们采用粗体 x 表示它是一个矢量。)我们将样本分为以下两类:
- 有标签样本
- 无标签样本
有标签样本同时包含特征和标签。即:
labeled examples: {features, label}: (x, y)
我们使用有标签样本来训练模型。在我们的垃圾邮件检测器示例中,有标签样本是用户明确标记为“垃圾邮件”或“非垃圾邮件”的各个电子邮件。
例如,下表显示了从包含加利福尼亚州房价信息的数据集中抽取的 5 个有标签样本:
| housingMedianAge(特征) | totalRooms(特征) | totalBedrooms(特征) | medianHouseValue(标签) |
|---|---|---|---|
| 15 | 5612 | 1283 | 66900 |
| 19 | 7650 | 1901 | 80100 |
| 17 | 720 | 174 | 85700 |
| 14 | 1501 | 337 | 73400 |
| 20 | 1454 | 326 | 65500 |
无标签样本包含特征,但不包含标签。即:unlabeled examples: {features, ?}: (x, ?)
在使用有标签样本训练了我们的模型之后,我们会使用该模型来预测无标签样本的标签。在垃圾邮件检测器示例中,无标签样本是用户尚未添加标签的新电子邮件。
模型
模型定义了特征与标签之间的关系。例如,垃圾邮件检测模型可能会将某些特征与“垃圾邮件”紧密联系起来。我们来重点介绍一下模型生命周期的两个阶段:
训练表示创建或学习模型。也就是说,您向模型展示有标签样本,让模型逐渐学习特征与标签之间的关系。
推断表示将训练后的模型应用于无标签样本。也就是说,您使用训练后的模型来做出有用的预测 (
y')。例如,在推断期间,您可以针对新的无标签样本预测medianHouseValue。
回归与分类
回归模型可预测连续值。例如,回归模型做出的预测可回答如下问题:
加利福尼亚州一栋房产的价值是多少?
用户点击此广告的概率是多少?
分类模型可预测离散值。例如,分类模型做出的预测可回答如下问题:
某个指定电子邮件是垃圾邮件还是非垃圾邮件?
这是一张狗、猫还是仓鼠图片?