版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/github_27587443/article/details/73611664
这个周项目的进度主要是svm模型的应用,关于svm原理:
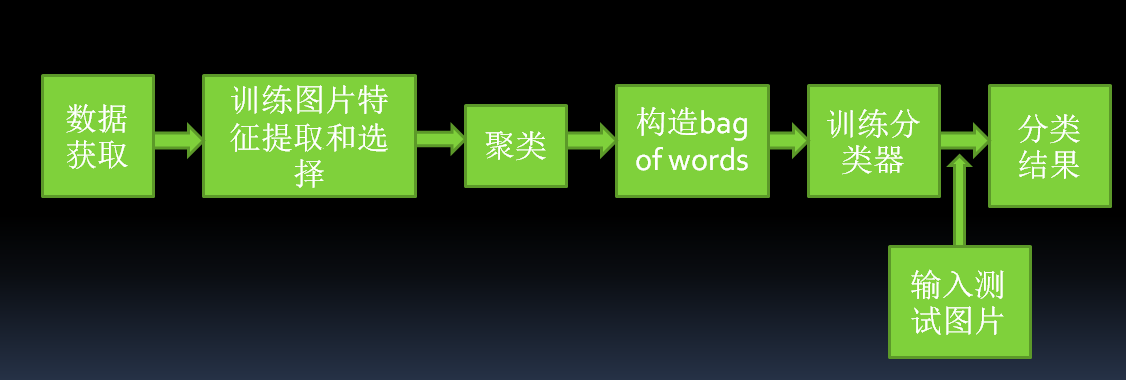
- 数据获取
比如摄像机或视频头的输出,通过采样获得数据,也可以是一般的统计数据集,其中的数据以向量或矩阵形式表示,或者是已经准备好的待检测的图片 - 训练图片特征提取和选择
特征提取是指从对象本身获取各种对于分类有用的度量或属性。特征选择是指如何从描述对象的多种特征中找出那些对于分类最有效的特征。特征提取我们用到了surf算法。Surf具有比sift快的检测速度。
对某一类模式的识别,其关键在于对模式特征的描述以及如何去提取这些特征。征描述直接影响到特征提取以及特征向量库的建立,并影响到最后分类识图像的特征提取和分类别精度的高低 从理论上讲,个体的特征是唯一的,这是因为不存在完全相同的两个个体。但是由于客观条件限制的存在,往往使得选取的特征并不是描述个体的特征全集,而只是特征的一个子集。因此,确定物体的本质特征是识别任务成功的关键。为了提高特征提取时计算的鲁棒性,往往又要求用尽可能少的特征来描述物体,这使得在实际应用中特征描述的不完全性是不可避免的。 - 将这些feature聚成n类。这n类中的每一类就相当于是图片的“单词”,所有的n个类别构成“词汇表”。我的实现中n取1000,如果训练集很大,应增大取值。
- 对训练集中的图片构造bag of words,就是将所有训练图片中的feature归到不同的类中,然后统计每一类的feature的频率。这相当于统计一个文本中每一个单词出现的频率。
- 分类器的设计(也就是训练分类器)
利用样本数据来确定分类器的过程称为分类器设计。训练一个多类分类器,将每张图片的bag of words作为feature vector,将该张图片的类别作为label。支持向量机(Support Vector Machines,SVM)应用发热典型流程是首先提取图形的局部特征所形成的特征单词的直方图来作为特征,最后被通过SVM进行训练得到模型。
在图像分类中用到了一种模型叫做BOW (bag of words) 模型。Bag of words模型最初被用在文本分类中,将文档表示成特征矢量。它的基本思想是假定对于一个文本,忽略其词序和语法、句法,仅仅将其看做是一些词汇的集合,而文本中的每个词汇都是独立的。简单说就是讲每篇文档都看成一个袋子(因为里面装的都是词汇,所以称为词袋,Bag of words即因此而来),然后看这个袋子里装的都是些什么词汇,将其分类。如果文档中猪、马、牛、羊、山谷、土地、拖拉机这样的词汇多些,而银行、大厦、汽车、公园这样的词汇少些,我们就倾向于判断它是一篇描绘乡村的文档,而不是描述城镇的。
最后通过训练好的模型,再次读取未经分类的图片,就可以对其分类。
流程图如图所示: