一、问题范围
1.1 客户端
1. 浏览器地址
2. 表单提交
3. 超链接
4. js
5. ajax
6. cookie或请求头
7. js文件编码
1.2 服务端
1. tomcat连接器
2. request.getInputStream
3. request.getReader
4. request.getParamter
5. request.getHeader或response.setHeader
6. response.getOutputStream
7. response.getWriter
8. cookie
9. 重定向
1.3 原理简述
以ISO-8859-1编码为例。ISO-8859-1编码,表示一个集合——{一个有限的字符符号集,一种编码方式,一个有限的编码集合},其中字符符号和编码对应关系的集合组成码表。
字符符号:就是人能够看懂的字符,例如“A”、“你”、“我”、“+”等等,对计算机而言他是不知道字符是什么意思,他只知道这些是码点组成的;
编码方式:单字节编码(UTF-8则以1~3字节编码,GBK以2字节编码),也就是文件中一堆二进制怎么断句的问题;
有限编码:二进制断句成一小段一小段,每一个小段就表示一个编码(例如ASCII的码表是128个,ISO-8859-1的码表是256个,UTF-8或GBK也各有各的码表),每一个编码一一对应一个字符符号,码表就是编码和字符符号对应关系的集合;
码表:即字符符号和编码的对应关系的集合,字符符号和编码一一对应;
原理简述:当在windows上对文本文件进行输入的时候,输入一个字符符号,会到GBK码表中进行查找,找到对应的编码,然后写入文件;当在windows上打开一个文本文件的时候,这个文件实际上是一堆二进制,因为windows默认编码是GBK,因此这对二进制会被两个字节两个字节的断开,每断开两个字节得到一个编码,然后到码表中进行查找,然后取出对应的字符符号进行展示;
乱码简述:当一个文件是GBK编码,意味着每两个字节就是一个编码对应一个字符,如果此时用ISO-8859-1的编码方式进行打开,意味着会对这堆二进制进行一个字节一个字节的编码,然后到ISO-8859-1的码表中进行字符符号的查找,因为ISO-8859-1只有256个编码和字符符号,当解析到的字节不在其正常编码范围,则用一个特殊的编码(对应的字符符号是问号“?”)进行展示,即便全部都在其正常的编码范围之内,因为GBK和ISO-8859-1的编码方式和码表并不对应,因此源文件的字符符号也不能进行正常的展示。
1.4 web环境逻辑
web环境下编码的主动权在服务器端。为什么这么说?捋捋逻辑,如果要访问一个网站,首先就是在地址栏输入域名进行访问,服务器端响应回来的第一个content-type中包含的编码信息便奠定了整站的编码基调。后续的访问除非直接在地址栏输入非ascii字符的uri+query string,否则uri默认都是utf-8编码,query string或content(请求体)都会按照响应头中content-type的编码来进行(当然有好几个部分可以进行编码控制,例如html的<meta>标签等,但是响应头content-type中编码的优先级最高)。
二、问题讨论
2.1 客户端
1. 浏览器地址栏
关于url编码,rfc 1738规定只有字母、数字和部分符号可以无需编码直接使用,而其他的字符则必须进行编码,对于进行何种编码,rfc并没有指定,因此不同的浏览器的编码方式不一样在所难免。url之所以如此规定,一是为了兼容方便移植,url的设计目的就是为了定位网络资源,不仅仅是http协议在用,smtp等等其他应用层协议也都在使用;二是为了安全,其他不在范围内的字符必须进行编码。以上原因在《http权威指南》中已有概述,此处不再赘述。
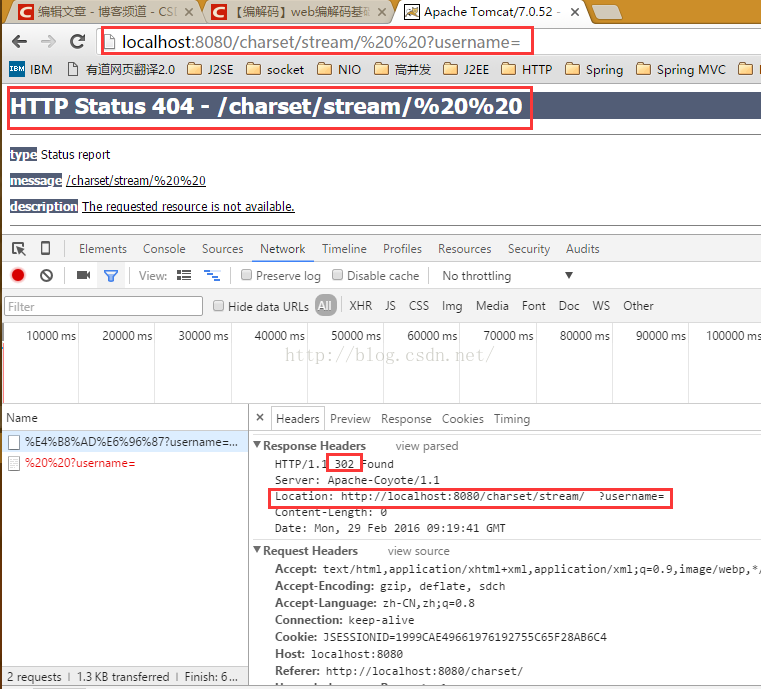
直接在浏览器的地址栏输入地址访问:
uri:urf-8编码;
query string:chrome使用urf-8编码,ie和firefox使用系统编码(windows是GBK)
2. 表单提交
uri使用UTF-8编码,无论method是get还是post,query string或请求体均采用content-type编码;
3. 超链接
uri使用UTF-8,query string使用content-type编码;
4. js
window.location和地址栏直接输入一致;
window.forms.formId.submit()和表单提交方式一致;
还需要补充的是js中url的编码,escape已经弃用了,他只是返回除ascii字符之外字符符号的unicode编码,并不能用于url编码;encodeURI和encodeURIComponent,前者编码范围小于后者,因此前者一般用于uri的编码,后者一般用于query string编码,两者的编码方式都是UTF-8;
5. ajax
主要讨论:
a. javascript的XMLHttpRequest post/get情况下uri/query_string包含中文的编码;
b. 响应时responseText包含中文;
请求时,uri默认UTF-8编码,和浏览器有关系,query string采用content-type中的编码;响应时responseText包含中文,默认是按照UTF-8进行编码,如果响应头中content-type包含编码信息,则按照该编码信息编码数据;
6. cookie或请求头
使用ISO-8859-1编码且不能修改,允许的安全的字符集为ascii字符集,这些字符集不需要进行url编码就能直接使用,超出这些字符集的字符不进行编码则会丢失;
7. js文件编码
通过<script>标签引入外部js文件的时候,如果没有charset属性,则js文件的解码默认使用页面编码,当两者不同的时候JS中出现乱码,这时候通过charset属性告知页面JS文件的编码即可,其实目的就是能够正确的把字符符号解析出来进行展示就可以了;
2.2 服务端
tomcat character encoding wiki: FAQ/CharacterEncoding
1. tomcat连接器
默认使用的是iso-8859-1方式编码,可以通过tomcat server.xml中连接器配置属性URIEncoding="UTF-8"修改为其他编码方式。当uri包含中文的时候,浏览器默认会进行UTF-8编码,如果此时tomcat连接器用iso-8859-1一个字节一个字节的来解码(因为ASCII字符的编码在编码方式中都是一样的,因此不会出现乱码,但是如果超出ASCII字符集部分则会因为不同的编码而出现乱码),必然出现解码失败,因此就需要配置连接器的解码方式为UTF-8;
tomcat连接器设置编码,除了URIEncoding之外,还有useBodyEncodingForURI="true"(默认是false)可以配置,两个参数的官方解释如下:
How do I change how GET parameters are interpreted?
Tomcat will use ISO-8859-1 as the default character encoding of the entire URL, including the query string ("GET parameters") (though see Tomcat 8 notice below).
There are two ways to specify how GET parameters are interpreted:
1. Set the URIEncoding attribute on the <Connector> element in server.xml to something specific (e.g. URIEncoding="UTF-8").
2. Set the useBodyEncodingForURI attribute on the <Connector> element in server.xml to true. This will cause the Connector to use the request body's encoding for GET parameters.
In Tomcat 8 starting with 8.0.0 (8.0.0-RC3, to be specific), the default value of URIEncoding attribute on the <Connector> element depends on "strict servlet compliance" setting. The default value (strict compliance is off) of URIEncoding is now UTF-8. If "strict servlet compliance" is enabled, the default value is ISO-8859-1.
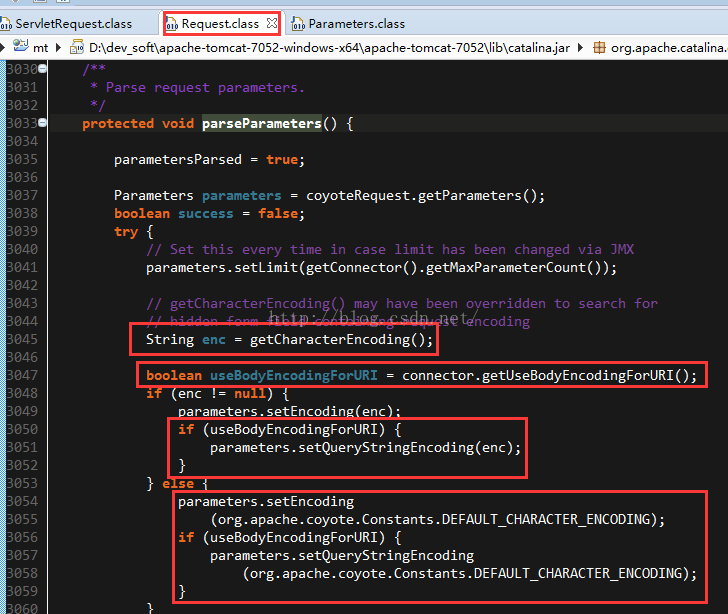
References: Tomcat 7 HTTP Connector, Tomcat 7 AJP Connector, Tomcat 8 HTTP Connector, Tomcat 8 AJP Connector简单而言,URIEncoding是对get请求方式的编码,无论是uri还是query string;但是有的浏览器对于uri的编码和query string的编码不一致(地址栏直接输入),因此可以通过设置useBodyEncodingForURI来对query string进行重新编码,当设置了该参数的时候,会从request.getCharacterEncoding获取编码方式,如果返回为null,则用ISO-8859-1进行编码。
需要注意的是,一般情况下,客户端请求是不会带有编码信息的,因此如果希望对query string重新进行编码,需要手动request.setCharacterEncoding。
2. request.getInputStream
默认ISO-8859-1;
javax.servlet.ServletRequest.getInputStream方法的实现在org.apache.catalina.connector.Request.getInputStream中,返回的是一个ServletInputStream,其继承关系是CoyoteInputStream extends ServletInputStream extends InputStream,返回的实际上是CoyoteInputStream的实例,而在CoyoteInputStream中对InputBuffer进行了装饰,InputBuffer默认编码便是ISO-8859-1,而这一条继承线索基本上就是tomcat请求输入的线索;
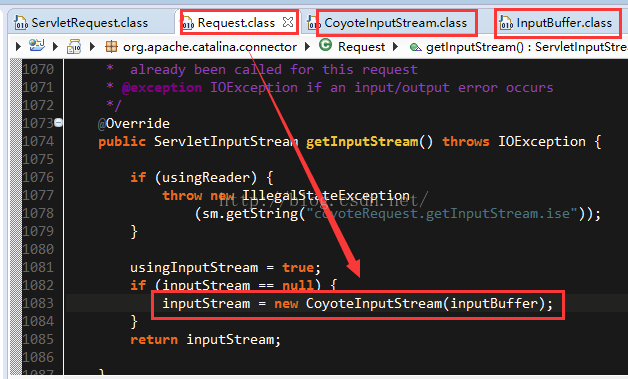
装饰模式就不再讲了,CoyoteInputStream中实际work的是InputBuffer的实例,而InputBuffer的默认编码是ISO-8859-1。

3. request.getReader
request的字符流和字节流并无差别,实际上都是对InputBuffer的装饰,但是在org.apache.catalina.connector.Request中返回字节流或字符流之前有一些区别,对于字节流是直接返回,但是对于字符流会进行编码检查和设置。
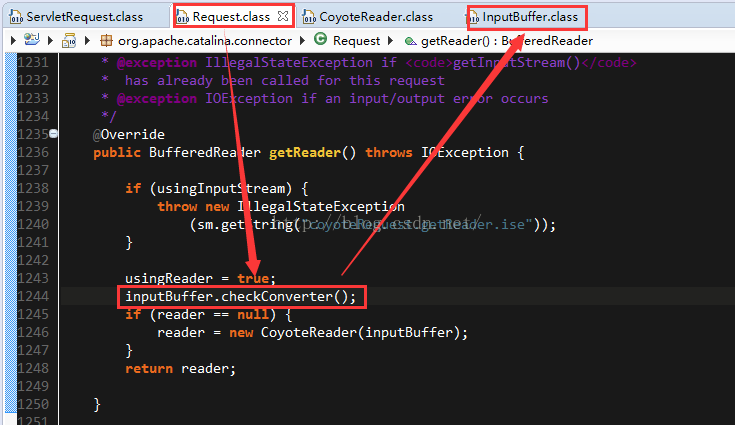

也就意味着,如果需要使用字符输入流,为了避免乱码,你需要在getReader之前设置请求编码,否则使用InputBuffer的默认编码ISO-8859-1。
4. request.getParameter
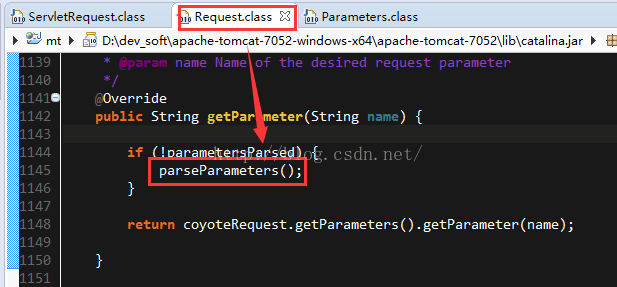
5. request.getHeader或response.setHeader或cookie
6. response.getOutputStream
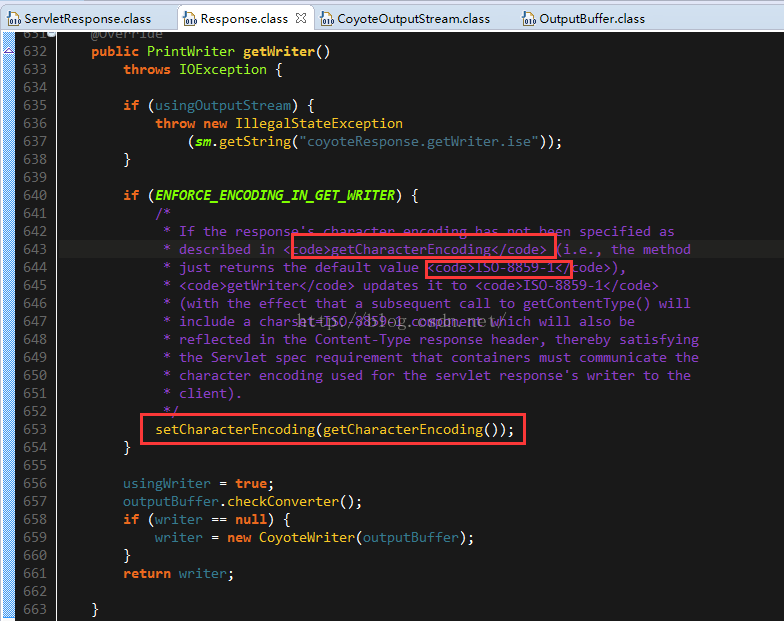
7. response.getWriter
8. 重定向