实例说明
音频编解码常用的实现方案有三 种。
第一种就是采用专用的音频芯片对 语音信号进行采集和处理,音频编解码算法集成在硬件内部,如 MP3 编解码芯片、语音合成 分析芯片等。使用这种方案的优点就是处理速度块,设计周期短;缺点是局限性比较大,不灵活,难以进行系统升级。
第二种方案就是利用 A/D 采集卡加上计算机组成硬件平台,音频编解码算法由计算机上的软件来实现。使用这种方案的优点是价格便 宜,开发灵活并且利于系统的升级;缺点是处理速度较慢,开发难度较大。
第三种方案是使用高精度、高速度 的 A/D 采集芯片来完成语音信号的采集,使用可编程的数据处理能力强的芯片来实现语音信号处理的算法,然后 用 ARM 进行控制。采用这种方案的优点是系统升级能力强,可以兼容多种音频压缩格式甚至未来的音频压缩格 式,系统成本较低;缺点是开发难度较大,设计者需要移植音频的解码算法到相应的 ARM 芯 片中去。
经过综合比较以上三种方案的优缺 点,本实例选用第三种设计方案来实现语音信号的音频编解码。
音频编解码框图
将模拟的、连续的声音波形数字化 ( 离 散化 ) ,可以得到数字音频。数字音频是把模拟的声音信号通过采样、量化和编码过程转变成数字信号,然后再 进行记录、传输及其他加工处理;重放时再将这些记录的数字音频信号还原为模拟信号,获得连续的声音。
采用数字音频技术可以避免模拟信号容易受噪声和干扰的影响,可以扩大音频的动态范围,可以利用计算机 进行数据处理,可以不失真地远距离传输,可以与图像、视频等其他媒体信息进行多路复用,以实现多媒体化和网络化。
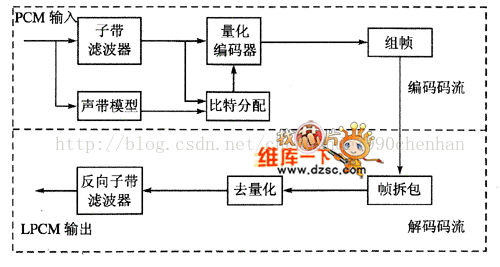
音频编码过程
音频信号数字化
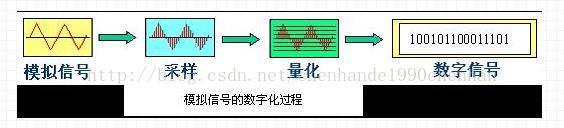
数字音频的质量取决于采样频率和量化位数。采样频率越高,量化位数越多,数字化后的音频质量越高。
音频采样
采样就是从一个时间上连续变化的 模拟信号取出若干个有代表性的样本值,来代表这个连续变化的模拟信号。一个在时间和幅值上都连续的模拟音频信号的函数表为 x(t), 采样的过程就是在时间上将函数 x(t) 离 散化的过程。一般的采样是按均匀的时间间隔进行的。设这一时间间隔为 T ,则取样后的信号 为 x(nT) , n 为自然数。
根据奈奎斯特采样定理:要从采样值序 列完全恢复原始的波形,采样频率必须大于或等于原始信号最高频率的 2倍。设连续信号 x(t) 的频谱为 x(W) ,以采样间隔时间 T 抽样得到离散信号 x(nT) ,如果满足 │ W │ ≤ Wc 时,其中 Wc 是截止频率,即 T ≤ l/2Wc 时,可以由 x(nT) 完全确定连续信号 x(t) 。
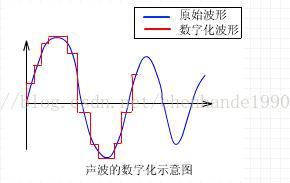
当采样频率为 1 / 2T 时,即 WN=Wc=1/2T 时,称 WN 为奈奎斯特采样频率。
音频量化
量化的过程 是先将采样后的信号按整个声波的幅度划分成有 限个区段的集合,把落入某个区段内的样值归为一类,并赋于相同的量化值。如何分割采样信号的幅度呢 ? 我们还是采取二进制的方式,以8位 (bit) 或 16 位 (bit) 的方式来划分纵轴 。也就是说在一个以8位为记录模式的音效中,其纵轴将会被划分为2^8个量化等级,用以记录其幅度大小,其精度为 音频信号最大振幅的 1/256 。量化位数越多,量化值越接近于采样值,其精度越高,但要求的信息存储量就越大。
存储数字音频信号的比特率为:
I=N·Ws
其中的 Ws 是采样率, N 是每个采样值的比特数。
要减小比特率 I ,在 Ws 已经确定的情况下,只能去减少 N 的值。 N 的值降低会导致量化的精 度降低, N 的值增加又会导致信息存储量的增加。因此在编码时就需要合理地选择 N 的值。
均匀量化就是采用相等的量化间隔进行采样,也称为线性量化。用均匀量化来量化输入信号时,无论对大的输入信号还是小的输入信号都一律采用相同的量化间隔。因此,要想既适应幅度大的输入信号,同时又要满足精度高的要求,就需要增加采样样本的位数。
非均匀量化的基本思想是对输入信号进行量化时,大的输入信号采用大的量化间隔,小的输入信号采用小的量化间隔,这样就可以在满足精度要求的情况下使用较少的位数来表示。其中采样输入信号幅度和量化输出数据之间一般定义了两种对应关系,一种称为 u 律压缩算法,另一种称 为 A 律压缩算法。
采用不同的量化方法,量化后的数据量也就不同。因此说量化也是一种压缩数据的方法。
G711编码原理
G711编码的声音清晰度好,语音自然度高,但压缩效率低,数据量大常在32Kbps以上。常用于电话语音(推荐使用64Kbps),sampling rate为8K,压缩率为2,即把S16格式的数据压缩为8bit,分为a-law和u-law。
a-law也叫g711a,输入的是13位(其实是S16的高13位),使用在欧洲和其他地区,这种格式是经过特别设计的,便于数字设备进行快速运算。
运算过程如下:
(1) 取符号位并取反得到s,
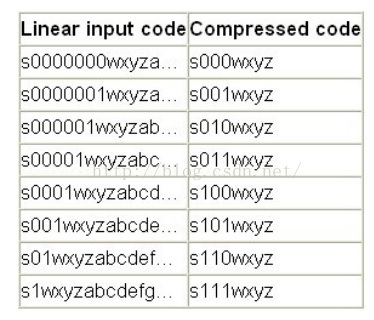
(2) 获取强度位eee,获取方法如图所示
(3) 获取高位样本位wxyz
(4) 组合为seeewxyz,将seeewxyz逢偶数为取补数,编码完毕
示例:
输入pcm数据为3210,二进制对应为(0000 1100 1000 1010)
二进制变换下排列组合方式(0 0001 1001 0001010)
(1) 获取符号位最高位为0,取反,s=1
(2) 获取强度位0001,查表,编码制应该是eee=100
(3) 获取高位样本wxyz=1001
(4) 组合为11001001,逢偶数为取反为10011100
编码完毕。
u-law也叫g711u,使用在北美和日本,输入的是14位,编码算法就是查表,没啥复杂算法,就是基础值+平均偏移值,具体示例如下:
pcm=2345
(1)取得范围值
| +4062 to +2015 in 16 intervals of 128 |
(2)得到基础值0x90,
(3)间隔数128,
(4)区间基本值4062,
(5)当前值2345和区间基本值差异4062-2345=1717,
(6)偏移值=1717/间隔数=1717/128,取整得到13,
(7)输出为0x90+13=0x9D
