Java 集合框架体系作为Java 中十分重要的一环, 在我们的日常开发中扮演者十分重要的角色, 那么什么是Java集合框架体系呢?
- 在Java语言中,Java语言的设计者对常用的数据结构和算法做了一些规范(接口)和实现(具体实现接口的类)。所有抽象出来的数据结构和操作(算法)统称为Java集合框架(Java CollectionFramework)。
- Java程序员在具体应用时,不必考虑数据结构和算法实现细节,只需要用这些类创建出来一些对象,然后直接应用就可以了,这样就大大提高了编程效率。
├List
│├LinkedList
│├ArrayList
│└Vector
│ └Stack
└Set
Map
├Hashtable
├HashMap
└WeakHashMap
Collection是最基本的集合接口,一个Collection代表一组Object,即Collection的元素(Elements)
Map提供key到value的映射 。
我们来看个Java 的集合体系框架图 :
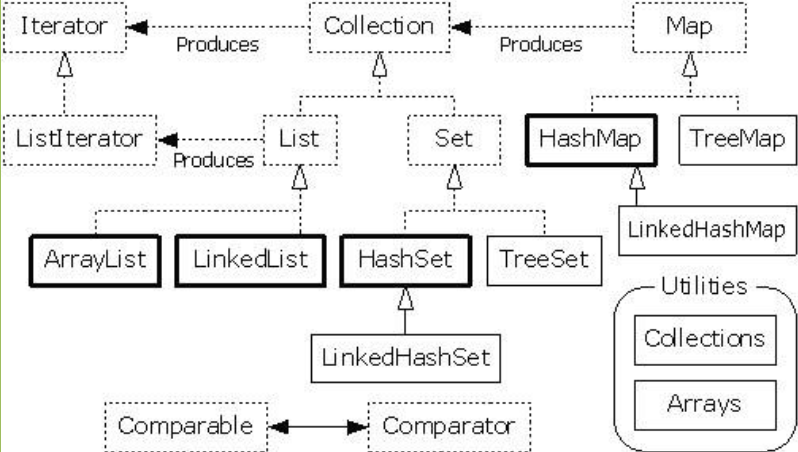
加粗的部分是我们常用的比较重要的集合类型。 集合体系我们常常有一个大的层次 叫Collection 。
Collection 为层次结构中的根接口。Collection 表示一组对象,这些对象也称为 collection 的元素。一些 collection 允许有重复的元素,而另一些则不允许。一些 collection 是有序的,而另一些则是无序的。JDK 不提供此接口的任何直接 实现:它提供更具体的子接口(如 Set 和 List)实现。此接口通常用来传递 collection,并在需要最大普遍性的地方操作这些 collection。
Colltction 为根接口 其下有四个常用子接口 分别为 List ,Set ,Map,Collections。
-
List
API 上 是这样表示的

特征:
list 是一种有序的(存储顺序和取出顺序一致)允许重复的集合类,有序的 collection(也称为序列)。此接口的用户可以对列表中每个元素的插入位置进行精确地控制。用户可以根据元素的整数索引(在列表中的位置)访问元素,并搜索列表中的元素。
List的常用实现类可分为:
1. ArrayList
其底层是基于动态数组的序列。基于线程不安全的,底层使用数组实现,所以查询快(下标直接定位),增删慢(数组特性,所以要挨个修改下标)。效率高。每次容量不足时,自增长度的一半。初始长度java6为10,java7更改为0。 底层增长方式源码为:
1 int newCapacity = oldCapacity + (oldCapacity >> 1);
ArrayList是一个基于数组的可变长度的容器,实现了所有可选列表操作,并允许包括 null 在内的所有元素。除了实现 List 接口外,此类还提供一些方法来操作内部用来存储列表的数组的大小。(此类大致上等同于 Vector 类,除了此类是不同步的)。
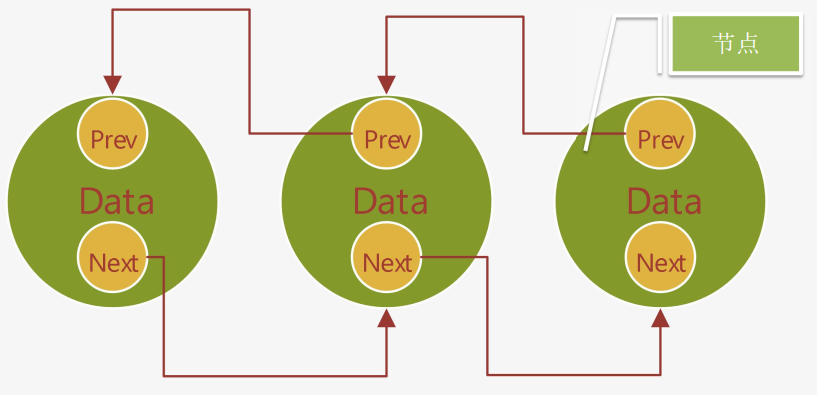
2. LinkedList
线程不安全,底层使用双向链表实现,所以查询慢(挨个一层一层的查找),增删快(只需要修改指针)。效率高。
我们来看一个双向链表结构图 :
3. Vector
Vrctor 和 ArrayList实现一样,只是是一个线程安全的序列 其初始长度为10。
底层使用数组实现,查询快,增删慢。效率低,每次容量不足时,默认自增长度的一倍(如果不指定增量的话),如果增长因子大于0则增加元素个数为增长因子的数量,如果小于0则增长为原长度的2倍。
源码中是这样写的:
1 int newCapacity = oldCapacity + ((capacityIncrement > 0) ? 2 capacityIncrement : oldCapacity);
-
Set
还是看看API 的表述;

特征:
核心 是 : 集
无序,去重,允许一个null 。
SET 是元素唯一的 ,不包含重复元素的 Collection类 。更确切地讲,Set不包含满足 e1.equals(e2) 的元素对 e1 和 e2,并且最多包含一个 null 元素。
Set 常用实现类可分为:
1. HashSet
底层是HashMap的key,所以特点是:
1 . 不会按照存放顺序排序,但会按照自己的算法排序,
2 . 去重
3 . 允许一个null 。
其增长方式,默认大小,最大长度和HashMap一致。
元素无下标。
HashSet 的去重问题:
我们知道HashSet在存放对象的时候会判断对象时候是同一对象。
默认引用类型比较的是地址值,如果地址值相同,那么这是一模一样的对象,那么判断肯定是同一对象,就不再重复的往里放。
如果对象重写了hashcode和equals方法,就比较这二者是否相等。
如果hashcode相等,那么比较equals方法,如果equals再相等,那么证明这是同一个对象;如果equals不相等,那么及时hashcode相等,也是两个对象。
所以得证:
如果equals不相等,那么hashcode可能相等;
如果equals相等,那么hashcode一定相等。
如果hashcode相等,那么equals可能相等;
如果hashcode不相等,那么equals一定不相等。
去重条件: 1. 两个对象的HashCode一致。 2 .两个对象的equals方法返回true 。
Set里的元素是不能重复的,所以我们 用iterator()方法来区分重复与否。equals()是判读两个Set是否相等。
=是用来判断两者是否是同一对象(同一事物),而equals是用来判断是否引用同一个对象。
equals()和==方法决定引用值是否指向同一对象 equals()在类中被覆盖,为的是当两个分离的对象的内容和类型相配的话,返回真值。
==号在比较基本数据类型时比较的是值,而用==号比较两个对象(引用)时比较的是两个对象的地址值:
equals()方法存在于Object类中,因为Object类是所有类的直接或间接父类,也就是说所有的类中的equals()方法都继承自Object类,而通过源码我们发现,Object类中equals()方法底层依赖的是==号,那么,在所有没有重写equals()方法的类中,调用equals()方法其实和使用==号的效果一样,也是比较的地址值,然而,Java提供的所有类中,绝大多数类都重写了equals()方法,重写后的equals()方法一般都是比较两个对象的值。
判断两个对象在逻辑上是否相等,如根据类的成员变量来判断两个类的实例是否相等,而继承Object中的equals方法只能判断两个引用变量是否是同一个对象。这样我们往往需要重写equals()方法。我们向一个没有重复对象的集合中添加元素时,集合中存放的往往是对象,我们需要先判断集合中是否存在已知对象,这样就必须重写equals方法。
值相同,指的应该是equals()方法返回的是true ,可以说,值相同决定不了hashcode相同;但hashcode相同则可以决定值相同。
当向集合Set中增加对象时,首先集合计算要增加对象的hashCode码,根据该值来得到 一个位置用来存放当前对象。 如果在该位置没有一个对象存在的话,那么集合Set认为该对象在集合中不存在,直接 增加进去。 如果在该位置有一个对象存在的话,接着将准备增加到集合中的对象与该位置上的对象 进行equals方法比较。 如果该equals方法返回false,那么集合认为集合中不存在该对象,再进行一次散列, 将该对象放到散列后计算出来的地址中。 如果equals方法返回true,那么集合认为集合中已经存在该对象了,不再将该对象增加到集合中。 2 重写equals方法的时候必须重写hashCode方法。如果一个类的两个对象,使用equals 方法比较时,结果为true,那么这两个对象具有相同的hashCode。原因是equals方法为true,表明是同一个对象,它们的hashCode当然相同。(Object类的equals方法比较的是地址) 3 Object类的hashCode方法返回的是Object对象的内存地址。我们可以通过Integer.toHexString(newObject().hashCode());来得到。
所以Java里面的hashSet中,如何判断两个对象是否相等?
a. 判断两个对象的hashCode是否相等。 如果不相等,认为两个对象不相等。完毕 如果相等,转入下面一步
b. 判断两个对象是否equals 如果不相等,认为两个对象不相等。 如果相等,认为两个对象相等hashcode 相同 一定值相同,一定是同一个对象, 值相同(equals方法为true) ,不一定对象相同,指向的不一定是同一个对象。
2 .TreeSet
底层实现二叉树,由于二叉树的特性,所以TreeSet 是一个有序的集。
特征:
1 . 按照字典排序,
2. 去重
3. 元素无下标
-
Map
- 将键映射到值的对象。一个映射不能包含重复的键;每个键最多只能映射一个值。
- 此接口代替 Dictionary 类,后者完全是一个抽象类,而不是一个接口。
- Map 接口提供三种collection 视图,允许以键集、值集合或键-值映射关系集的形式查看某个映射的内容。映射的顺序 定义为迭代器在映射的 collection 视图中返回其元素的顺序。某些映射实现可明确保证其顺序,如 TreeMap 类;某些映射实现则不保证顺序,如 HashMap类。
Map核心实现为接口中的接口 :

Entry方法摘要

Map 中的常用实现类:
1 .HashMap
底层实现:依赖于实现了Map.Entry接口的节点
特征:允许一个空键和多个空值,非线程同步,默认大小16
增长方式:取决于增长因子,默认增长因子为0.75F,增长方式: newThr = oldThr << 1;
最大长度:MAXIMUM_CAPACITY = 1 << 30
2. HashTable
特征: 不允许空键和空值,线程同步, 默认大小11
增长方式: 增长方式:old*2+1;
最大长度: MAXIMUM_CAPACITY = 1 << 30
-
Collections
此类完全由在 collection 上进行操作或返回 collection 的静态方法组成。它包含在 collection 上操作的多态算法,即“包装器”,包装器返回由指定 collection 支持的新 collection,以及少数其他内容。
换个说法:Collections是个java.util下的类,它包含有各种有关集合操作的静态方法。 Collection是个java.util下的接口,它是各种集合结构的父接口。
下面演示一下Map集合的遍历:
因为Map 的特性使得我们不能像数组那样进行for 循环遍历, 那么Map 集合我们如何遍历呢?
举个栗子:
public class collectionMap {
public static void main(String[] args) {
Map<String,Student> studentmap = new HashMap<String,Student>();
System.out.println("添加元素前长度: "+studentmap.size());
studentmap.put("001", new Student("张三", 22, "man"));
studentmap.put("002", new Student("李四", 21, "man"));
studentmap.put("003", new Student("王五", 23, "woman"));
System.out.println("添加元素后长度: "+studentmap.size());
// 遍历 key
for(String key:studentmap.keySet()){
System.out.println(key);
}
// 遍历map的value
for(Student stu:studentmap.values()){
System.out.println(stu);
}
// 遍历键值对 entry 是map的方法 ,是一个key,对应一个value 数组
Set<Map.Entry<String, Student>>entries =studentmap.entrySet();
for(Entry<String, Student> stu:entries){
System.out.println(stu.getKey()+"\t"+stu.getValue());
}
}
Map遍历的集中方式:
1 public class TestMap {
2 public static void main(String[] args) {
3 Map<Integer, String> map = new HashMap<Integer, String>();
4 map.put(1, "a");
5 map.put(2, "b");
6 map.put(3, "ab");
7 map.put(4, "ab");
8 map.put(4, "ab");
9 // 和上面相同 , 会自己筛选 System.out.println(map.size());
10
11 // 第一种:
12 Set<Integer> set = map.keySet(); //得到所有key的集合
13 for (Integer in : set) {
14 String str = map.get(in);
15 System.out.println(in + " " + str);
16 }
17 System.out.println("第一种:通过Map.keySet遍历key和value:");
18 for (Integer in : map.keySet()) {
19 //map.keySet()返回的是所有key的值
20 String str = map.get(in);//得到每个key多对用value的值
21 System.out.println(in + " " + str);
22 }
23
24
25 // 第二种:
26 System.out.println("第二种:通过Map.entrySet使用iterator遍历key和value:");
27 Iterator<Map.Entry<Integer, String>> it =map.entrySet().iterator();
28 while (it.hasNext()) {
29 Map.Entry<Integer, String> entry = it.next();
30 System.out.println("key= " + entry.getKey() + " and value= " + entry.getValue());
31 }
32 // 第三种:推荐,尤其是容量大时35
33 System.out.println("第三种:通过Map.entrySet遍历key和value");
34 for (Map.Entry<Integer, String> entry : map.entrySet()) {
35 //Map.entry<Integer,String> 映射项(键-值对) 有几个方法:用上面的名字entry
36 //entry.getKey() ;entry.getValue(); entry.setValue();
37 //map.entrySet() 返回此映射中包含的映射关系的 Set视图。
38 System.out.println("key= " + entry.getKey() + " and value= "+ entry.getValue());
39 }
40 // 第四种: System.out.println("第四种:通过Map.values()遍历所有的value,但不能遍历key");
41 for (String v : map.values()) {
42 System.out.println("value= " + v);
43 }
44 }
45}