Java集合框架——JCF,在java 1.2版本中被加入,它包含了大量集合操作,是Java体系中的重要组成部分。网上已有很多JCF的框架图,这里根据自己的理解整理了一份JCF框架图如下:
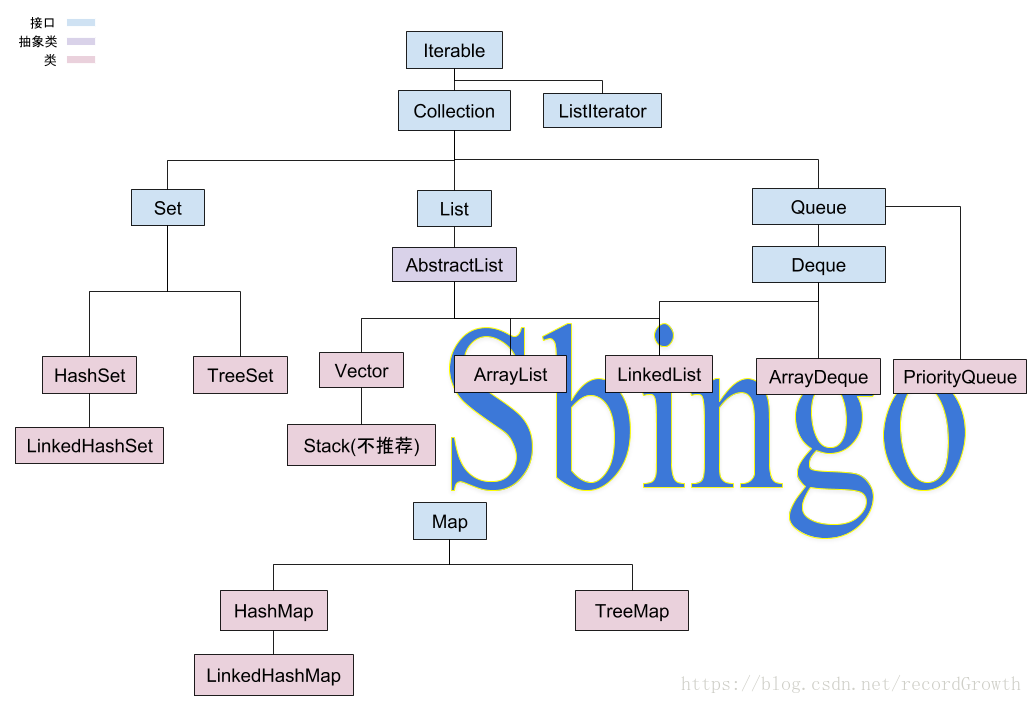
JCF主要包含了Set、List、Queue、Map4个接口,笔者对于该框架图中每个类的理解进行了文字性的描述如下,大部分以关键字进行说明。
Set
HashSet
底层用`HashMap`实现
允许`null`值
不重复原理:HashMap.keySet(),`HashSet`的值用作`HashMap`的键
TreeSet
TreeMap排序,插入时比较次序,红黑树
为了实现排序,须满足以下1条:
TreeSet中的元素须实现Comparable接口
或者
构造TreeSet时须传入实现Comparable接口的类的对象
LinkedHashSet
继承自`HashSet`,构造方法全部调用父类同一个构造方法
底层实现为`LinkedHashMap`
List
List 特有的迭代器 ListIterator 接口,继承了 Iterator 接口
不仅可以正向遍历,还能反向遍历
ArrayList
since 1.2,非线程安全
实现了接口RandomAccess,随机访问(即,通过索引序号访问)效率最高,而使用迭代器的效率最低
内部数组实现,除非构造时指定大小,否则构造后为空数组,添加第一个元素时才分配默认大小10
增加元素时先扩容,扩容为原数组大小的1.5倍 或者 原大小+新增的元素个数
增删元素时调用System.arraycopy
删除、插入慢,查找快
删除元素、查找元素下标等操作时,从0遍历数组查看元素是否为`null`或equals比较
LinkedList
既是`List`,又是栈和队列
双向链表,节点`Node(item, next, prev)`,第一个元素`first`,最后一个元素`last`
删除、插入快,查找慢
通过索引随机访问元素时,判断集合大小的一半与索引大小,向前寻找`prev`或向后寻找`next`
删除元素、查找元素下标等操作时,从`first`开始遍历数组查看元素是否为`null`或equals比较
Vector
since 1.0,线程安全
和ArrayList类似,实现了接口RandomAccess,内部以数组实现
除非构造时指定数组大小,否则构造时分配默认大小10
除非构造时指定扩容增量,否则扩容为原大小的两倍 或者 原大小+新增的元素个数
其余增删改查操作和`ArrayList`几乎相同
Stack
继承自`Vector`,将其作为栈使用
实现了5种栈的操作(包含增删查,`push`、 `pop`、 `peek`)
官方推荐使用`Deque`代替`Stack`
Queue
Queue
队列接口,提供增删查3种操作
每种操作有两种形式:
一种在操作失败时抛出异常
另一种在操作失败时返回`null`或`false`
所以该接口架构提供了6种方法
Deque
`double ended queue`,继承自`Queue`
两端都可以增删查的线性集合,可以表示栈和队列
所以提供的操作是`Queue`的两倍,共12种操作
另外还有`Queue`的6种方法和栈的`push`、 `pop`方法
其中栈和队列的方法分别对应它的12种方法中的一种
ArrayDeque
循环数组实现的双端队列
数组大小默认为16,`head`和`tail`分别为头尾索引,数组没有元素时两个索引相等
每次新增元素后,如果`head`和`tail`相等,说明数组已满,此时进行扩容
扩容后的大小为原数组两倍,分两次进行复制
第一次复制head右边的元素,第二次复制head左边的元素。
扩容后重置`head`为0,`tail`为数组大小`n`
PriorityQueue
优先队列:通过最小堆实现,根节点最小,不允许`null`元素
元素大小的比较可以通过元素本身的自然顺序,也可以通过构造时传入的比较器
底层实现为数组`Object[] queue`,将最小堆中的元素按照层序遍历的方式放入数组,默认大小为11
扩容时如果原大小不足64,则扩为原大小的两倍,否则扩为原大小的1.5倍
索引为`n`的节点的两个子节点索引分别为`2n+1`和`2n+2`,父节点索引为`(n-1)/2`
队列的3种操作:
`增`:上滤
`删`:下滤
`查`:直接返回`(size == 0) ? null : (E) queue[0]`
Map
HashMap
since 1.2
接收`null`的键值,存储着`Node(hash, key, value, next)`对象
线程不安全
顺序不能保证
拉链法:哈希桶数组+链表(jdk8.0+红黑树)
性能相关
初始容量(16),这是一种非常规的设计,常规的设计是把桶的大小设计为素数。相对来说素数导致冲突的概率要小于合数
这里采用这种非常规设计,主要是为了在取模和扩容时做优化,同时为了减少冲突,HashMap定位哈希桶索引位置时,也加入了高位参与运算的过程。
加载因子(0.75)
hash值的计算: `key`的`hashcode`的高16位和低16位的异或,主要是从速度、功效、质量来考虑
桶索引:利用位运算实现`hash`值对数组长度取余
时间复杂度
常数(假设哈希函数保证元素在各个桶之间均匀分布)
数组+链表:O(1)+O(n)
数组+红黑树:O(1)+O(logn)
扩容时间点
插入第一对键值对
插入新键值对后键值对数量超过阙值
扩容过程
哈希桶数组大小翻倍
因为桶索引使用位运算得到,数组大小n为2的指数,所以`n-1`相当于比扩容前多使用了1个bit`1`,因此新的桶索引
只需要看原来的hash值对应新增的那个bit是1还是0就好了,是0的话索引没变,是1的话索引变成“原索引+原哈希桶大小”
这样既节省了计算时间,又能使之前冲突的节点有再次打散的可能。
存
过程
计算哈希桶索引,如果没冲突,直接插入新的键值对
如果有冲突,判断是否为同一个key,是则更新键值对(新旧hash== 且 新旧key==或新旧key满足equals)
如果不是一个key,判断是否为红黑树节点,如果是,直接插入新的树节点。
如果不是树节点(说明链表大小还没达到转变为红黑树的阙值),遍历链表,查看是否有相同的key,有则更新对应的键值对
如果遍历结束仍没找到相同的key,则在链表末尾插入新的键值对,此时如果链表长度太长(默认超过8),就将链表转换为红黑树,从而提高速度
结果
在链表起始或链表末尾处插入新键值对
在链表起始或链表某个节点处更新键值对
将更新后的键值对移至链表末尾
取
计算哈希桶索引,如果桶中第1个节点为`null`,则返回`null`
如果有节点,判断是否为同一个key,是则返回该节点的值
如果不是,判断是否为红黑树节点,是的话直接查找该树节点,并返回它的值
如果不是树节点,则遍历链表查看是否有相同的key,有则返回对应节点的值
如果遍历结束仍没有找到相同的key,则返回`null`
注意:返回`null`也可能是对应key的值就是`null`
TreeMap
since 1.2
为了实现排序,须满足以下1条:
`key`须实现Comparable接口
或者
构造`TreeMap`时须传入实现Comparable接口的类的对象,将其赋值给比较器`comparator`
内部实现为红黑树,根节点`root`,节点对象`Entry(key、value、left、right、parent、color)`
红黑树是满足如下条件的二叉查找树:
每个节点要么是红色,要么是黑色
根节点必须是黑色
红色节点不能连续(即:红色节点的孩子和父亲都不能是红色)
对于每个节点,从该点至null(树尾端)的任何路径,都含有相同个数的黑色节点
存
判断根节点是否为`null`,是的话则将当前键值对保存为根节点
否则从根节点开始,用`comparator`或者`key`本身与当前节点的`key`进行比较,如果相等则更新当前节点的值
否则根据比较值的正负,继续与当前节点的右左子节点比较,直至到达叶节点
如果到达叶节点后,则插入新的节点,并旋转红黑树,使树重新平衡
取
从根节点开始,用`comparator`或者`key`本身与当前节点的`key`进行比较,如果相等则返回当前节点的值
否则根据比较值的正负,继续与当前节点的右左子节点比较,直至找到`key`相同的节点
如果遍历结束,仍没有找到相同的节点,则返回`null`
删
和取一样,找到`key`对应的`Entry`,如果找不到则返回
否则删除这个节点,然后使树重新平衡
LinkedHashMap
继承自`HashMap`,结构基本和`HashMap`一样,二者唯一的区别是它在`HashMap`的基础上,将所有元素链接了起来,形成一个双向链表
因此它的元素对象`Entry`继承自`HashMap.Node`,多了`before`和`after`两个属性
元素`head`和`tail`分别指向双向链表的头尾,便于链表的遍历
这个双向链表的遍历有两种顺序:`insertion-order (默认顺序)`和`access-order`
当采用`insertion-order`时,增查操作同`HashMap`,同时迭代顺序和插入顺序相同
当采用`access-order`时,可用于构建`LRU`缓存,新增元素后可选择是否删除最旧的元素,查找元素后将该元素置于双向链表的末尾
非集合框架
Hashtable
since 1.0,线程安全,继承自抽象类`Dictionary`
不接收`null`的键值
拉链法:哈希桶数组+链表
其他和`HashMap`类似
参考资料:
1. Java 8源码
2. 深入理解Java集合框架
3. 数据结构与算法系列
4. Data Structures & Algorithms