一 项目介绍
1.1 开发工具和环境
这里呢,我们统一一下相关的开发工具和环境:
电商日志分析(用户session数据分析)
使用语言:scala
存储:hdfs(数据来源),kafka,mysql(实时数据和离线数据)
数据对接:
Flume(数据传输),Mysql(存储实时和离线的数据)
分析引擎:
MR(数据清洗),Spark(sparkSql,SparkCore,SparkStreaming)
资源调度:
yarn
1.2 项目简单介绍
用户在网站上会产生大量的点击行为
1 用户进入首页,点击部分品类,再进入到商品页面
2 查找某个具体的商品,在搜索框,搜索关键字
3 把自己感兴趣的商品放到购物车里面,对购物车中的多个商品下单
4 对商品支付
用户的每一个行为,这里都成为是1个action,这个action,包括,点击,搜索,下单,购买
这里的session,指的是用户从第一次进入到首页,到离开网站的一整个过程。
在这个时间范围内,会进行海量的操作,甚至有几十次上百次的操作!
如果离开了网站,或者关闭了浏览器,那么session,就结束了。
以上,用户在网站中访问的,一整个过程,就称为一次的session.
session,其实就是电商网站中的,最基本的数据!这里,我们进行的是面向C端的一个分析
1.3 项目的技术架构
这里呢,可以被分为离线和实时两个模块
1.3.1 离线部分-执行流程
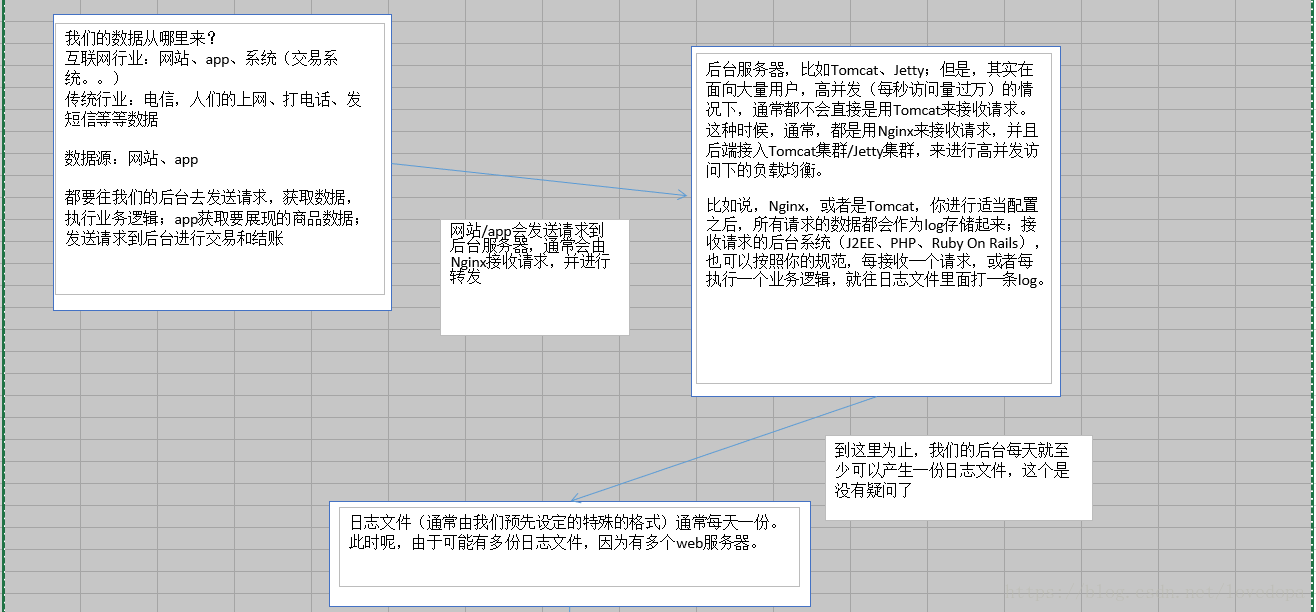
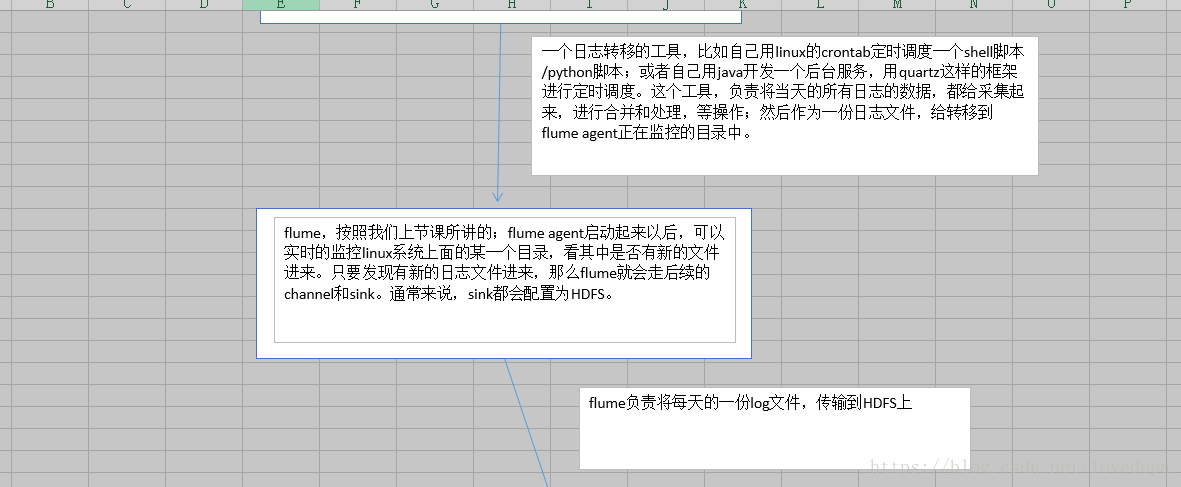

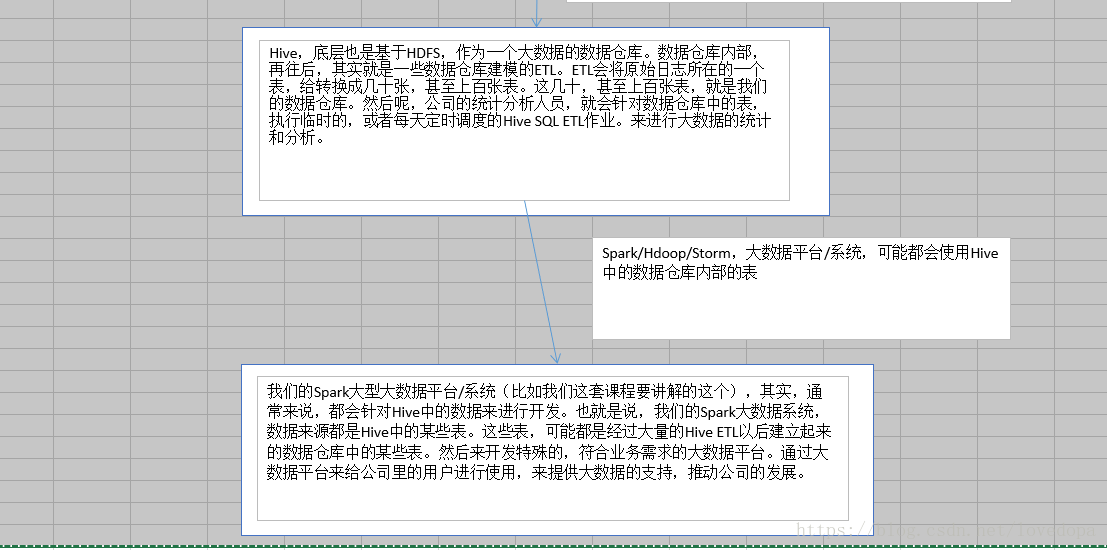
1.3.2 实时部分-执行流程

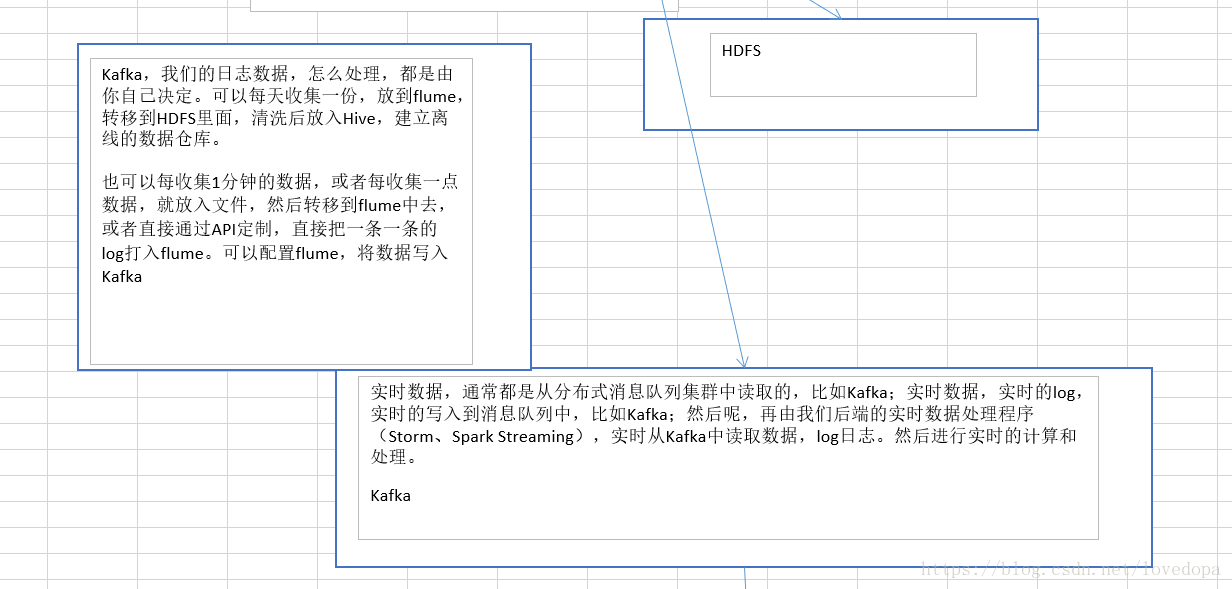

1.4 数据分析平台的架构

1.5 项目的模块需求分析
a 对用户所访问的session数据按条件进行分析
根据使用者(需求方)指定的一些条件,筛选出指定的一些用户(比如按年龄,职业或所在城市等筛选条件)
按条件筛选session,这个功能最大的作用就是灵活。可以让使用者(决策者),对感兴趣的和关心的用户群体,进行后续各种复杂业务逻辑的统计和分析,比如查找搜索过某些关键词的用户、访问时间在某个时间段内的用户、年龄在某个范围内的用户、职业在某个范围内的用户、所在某个城市的用户,等等条件发起的session。拿到的结果数据,就是只是针对特殊用户群体的分析结果,而不是对所有用户进行分析的泛泛的分析结果。例如现在某个企业高层,他想看到用户群体中,28~35岁的消费群体对应的一些统计和分析的结果数据,从而辅助高管进行公司战略上的决策制定。
b session的相关分析
1 用户访问session进行聚合统计
比如需要统计访问时长在0~3的session占比,4~6的session占比。
session访问时长,就是一个session对应的开始的action到结束的action之间的时间范围。访问步长,指的是,一个session执行期间内,依次点击过多少个页面,比如说一次session维持了1分钟,那么访问时长就是1分钟,然后在这1分钟内点击了10个页面,那么session的访问步长就是10。
session占比:举个栗子,符合第1步筛选出来的session的数量大概是有1000万个。在这里面,我们要计算出访问时长在1s~3s内的session的数量,并除以符合条件的总session数量(比如1000万),比如是100万/1000万,那么1s~3s内的session占比就是10%,依次类推。
这个功能的作用,其实就是,可以让人从全局的角度看到,符合某些条件的用户群体使用我们的产品的一些习惯。比如大多数人,到底是会在产品中停留多长时间,大多数人会在一次使用产品的过程中访问多少个页面。那么对于决策者来说,有一个清晰的全局认识。
2 按时间比例随机抽取session
随机抽取本身是很简单的,但是按照时间比例,就复杂了。比如说,这一天总共有1000万的session。现在要从这1000万session中随机抽取出来1000个session。但是这个随机不是那么简单的。需要做到如下要求:首先,如果这一天的12:00~13:00的session数量是100万,那么这个小时的session占比就是1/10,那么这个小时中的100万的session,我们就要抽取1/10 * 1000 = 100个。然后再从这个小时的100万session中,随机抽取出100个session。以此类推,其他小时的抽取也是这样做。
这个功能的作用是可以让使用者能够对于符合条件的session按照时间比例均匀的随机采样出1000个session,然后观察每个session具体的点击行为,比如先进入了首页,然后点击了食品品类,接下来点击了雨润火腿肠商品,然后搜索了火腿肠罐头的关键词,接着对王中王火腿肠下了订单,最后对订单做了支付。
之所以要做到按时间比例随机采用抽取,就是要做到,观察样本的公平性。
3 获取点击、下单、支付次数排名的top10
计算出来通过筛选条件的session,他们访问的所有品类(点击、下单、支付),按照各个品类的点击、下单、支付次数,进行降序排列,然后再获取前10个品类,也就是筛选条件下的那一批session的top10热门品类。
怎么排序?点击、下单、支付次数:优先按照点击次数排序,如果点击次数相等,就按照下单次数来排序,以此类推,这就用到了自定义排序。
对session按照条件排序,用到二次排序(自定义排序)
这个功能很重要,可以让我们了解符合条件的用户最感兴趣的商品是什么品类。这个可以让公司里的相关负责人,清晰地了解到不同层次、不同类型的用户的购买习惯。
4 对于排名前10的品类分别获取其点击次数前10的session
对于top10的品类,每一个都要获取对它点击次数排名前10的session。
这个功能可以分析对某个用户群体最感兴趣的品类,各个品类最感兴趣最典型的用户的session的行为。从top10热门品类,获取每个品类点击次数最多的前10个session,以及对应的访问明细。
这个功能可以分析出每个品类中的最受欢迎或最受关注的商品。
c 页面单跳转化率
- 接收J2EE系统传进来的taskId,根据taskId去MySQL查询任务的参数,日期范围、页面流id
- 针对指定范围日期内的用户访问行为数据,去判断计算页面流id中每两个页面组成的页面切片,它的访问量是多少
- 根据指定页面流中各个页面切片的访问量,计算出各个页面切片的转化率
- 把计算出来的转化率,写入MySQL
d 广告点击流量实时统计
- 实时的动态获取黑名单机制,将每天对每个广告点击超过100次的用户拉黑
- 基于黑名单的非法广告点击流量过滤机制
- 每天各省各城市各广告的点击流量实时统计,基于第二点的数据基础之上
- 统计每天各省top3热门广告
- 统计各广告最近1小时内的点击量趋势,各广告最近1小时内各分钟的点击量,也是基于第2点的数据基础之上
- 使用高性能方式将实时统计结果写入MySQL
1.6.1 相关的数据表 -离线数据分析
user_visit_action表:
就是网站/app每天的点击流的数据。可以理解为,用户对网站/app每点击一下,就会代表在这个表里面生成一条数据。
表名:user_visit_action(Hive表)
date:日期,代表这个用户点击行为是在哪一天发生的
user_id:代表这个点击行为是哪一个用户执行的
session_id :唯一标识了某个用户的一个访问session
page_id :点击了某些商品/品类,也可能是搜索了某个关键词,然后进入了某个页面,页面的id
action_time :这个点击行为发生的时间点
search_keyword :搜索的关键词.如果用户执行的是一个搜索行为,比如说在网站/app中,搜索了某个关键词,然后会跳转到商品列表页面
click_category_id :在网站首页,点击的某个品类(美食、电子设备、电脑)
click_product_id :在首页或商品列表页,点击的某个商品(比如呷哺呷哺火锅XX路店3人套餐、iphone 6s)
order_category_ids :代表了可能将某些商品加入了购物车,然后一次性对购物车中的商品下了一个订单,这就代表了某次下单的行为中,有哪些
商品品类,可能有6个商品,但是就对应了2个品类,比如有3根火腿肠(食品品类),3个电池(日用品品类)
order_product_ids :某次下单,具体对哪些商品下的订单
pay_category_ids :代表的是对某个订单或者某几个订单进行了一次支付的行为,对应了哪些品类
pay_product_ids:代表的是支付行为下对应的哪些具体的商品
city_id:对应所在区域的城市
user_info表
实际上,就是一张最普通的用户基础信息表;这张表里面,其实就是放置了网站/app所有的注册用户的信息。那么我们这里也是对用户信息表,进行了一定程度的简化。比如略去了手机号等这种数据。因为我们这个项目里不需要使用到某些数据。那么我们就保留一些最重要的数据即可。
表名:user_info(Hive表)
user_id:其实就是每一个用户的唯一标识,通常是自增长的Long类型,BigInt类型
username:是每个用户的登录名
name:每个用户自己的昵称、或者是真实姓名
age:用户的年龄
professional:用户的职业
city:用户所在的城市
sex:用户性别
product_info
product_info表,是一张普通的商品基本信息表;这张表中存放了网站/APP所有商品的基本信息。
proudct_id 商品ID,唯一地标识某个商品
product_name 商品名称
extend_info 额外信息,例如商品为自营商品还是第三方商品
task表
其实是用来保存平台的使用者,通过J2EE系统,提交的基于特定筛选参数的分析任务的信息,就会通过J2EE系统保存到task表中来。之所以使用MySQL表,是因为J2EE系统是要实现快速的实时插入和查询的。
表名:task(MySQL表)
task_id:表的主键
task_name:任务名称
create_time:创建时间
start_time:开始运行的时间
finish_time:结束运行的时间
task_type:任务类型,就是说,在一套大数据平台中,肯定会有各种不同类型的统计分析任务,比如说用户访问session分析任务,页面单跳转化率统计任务;所以这个字段就标识了每个任务的类型
task_status:任务状态,任务对应的就是一次Spark作业的运行,这里就标识了,Spark作业是新建,还没运行,还是正在运行,还是已经运行完毕
task_param:重要!用来使用JSON的格式,来封装用户(使用者)提交的任务对应的特殊的筛选参数
1.6.3 在线数据分析
程序每5秒向Kafka集群写入数据,格式如下:
格式 :timestamp province city userid adid
timestamp 当前时间毫秒
userId 0 – 99
provice/city 1 – 9
((0L,"北京","北京"),(1L,"上海","上海"),(2L,"南京","江苏省"),(3L,"广州","广东省"),(4L,"三亚","海南省"),(5L,"武汉","湖北省"),(6L,"长沙","湖南省"),(7L,"西安","陕西省"),(8L,"成都","四川省"),(9L,"哈尔滨","东北省"))
adid 0 - 19
1.6.3 工程搭建
我们这里使用的是mave
maven的好处:
项目构建。
Maven定义了软件开发的整套流程体系,并进行了封装,开发人员只需要指定项目的构建流程,无需针对每个流程编写自己的构建脚本。
依赖管理。
除了项目构建,Maven最核心的功能是软件包的依赖管理,能够自动分析项目所需要的依赖软件包,并到Maven中心仓库去下载。
管理Jar包的依赖。
管理工程之间的依赖关系,即可使用Maven依赖其他的工程。
这里呢,我们使用的是idea,进行的相关的开发-另外,提供好了模拟数据的方法:
下面我提供一个比较全面的pom.xml文件,文件内容可能有点多,初次接触这种商城大项目的人是不可能一蹰而就写完的,肯定是在编写项目的过程中,需要用到哪个jar包,就在pom.xml文件进行配置,这里呢,我保证总目录下的文件,都是独立的,每个子目录下的文件可以额外的添加需要的内容。
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.atguigu</groupId>
<artifactId>commerce</artifactId>
<packaging>pom</packaging>
<version>1.0-SNAPSHOT</version>
<modules>
<module>commons</module>
<module>mock</module>
</modules>
<!-- 声明子项目公用的配置属性 -->
<properties>
<spark.version>2.1.1</spark.version>
<scala.version>2.11.8</scala.version>
<log4j.version>1.2.17</log4j.version>
<slf4j.version>1.7.22</slf4j.version>
</properties>
<!-- 声明并引入子项目共有的依赖 -->
<dependencies>
<!-- 所有子项目的日志框架 -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>jcl-over-slf4j</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>${slf4j.version}</version>
</dependency>
<!-- 具体的日志实现 -->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>${log4j.version}</version>
</dependency>
<!-- Logging End -->
</dependencies>
<dependencyManagement>
<dependencies>
<!-- 引入Spark相关的Jar包 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
<!-- provider如果存在,那么运行时该Jar包不存在,也不会打包到最终的发布版本中,只是编译器有效 -->
<!--<scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.version}</version>
<!--<scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>${spark.version}</version>
<!--<scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.11</artifactId>
<version>${spark.version}</version>
<!--<scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-graphx_2.11</artifactId>
<version>${spark.version}</version>
<!--<scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
<!--<scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>${spark.version}</version>
<!--<scope>provided</scope>-->
</dependency>
</dependencies>
</dependencyManagement>
<!-- 声明构建信息 -->
<build>
<!-- 声明并引入子项目共有的插件【插件就是附着到Maven各个声明周期的具体实现】 -->
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.1</version>
<!-- 所有的编译都依照JDK1.8来搞 -->
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
<!-- 仅声明子项目共有的插件,如果子项目需要此插件,那么子项目需要声明 -->
<pluginManagement>
<plugins>
<!-- 该插件用于将Scala代码编译成class文件 -->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
<executions>
<execution>
<!-- 声明绑定到maven的compile阶段 -->
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<!-- 用于项目的打包插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</pluginManagement>
</build>
</project>如果大家,需要初始化的项目,我这里已经上传了网盘,大家可以在如下的地址下载
链接:https://pan.baidu.com/s/1UT9EBHdGvRF_ekSJ8XDxYA 密码:2u1x
直接打开jar包即可。
1.7 项目的模块介绍
1 commons模块
包名称(package) 解析
conf 配置工具类
获取commerce.properties文件中的所有配置信息,使用户可以通过对象的方式访问commerce.properties中的所有配置
constant 常量接口
包括项目中所需要使用的所有常量
model Spark SQL样例类
包括Spark SQL中的用户访问动作表、用户信息表、产品表的样例类
pool MySQL连接池
通过自定义MySQL连接池实现对MySQL数据库的操作
utils 工具类
提供了日期时间工具类、数字格式工具类、参数工具类、字符串工具类、校验工具类等工具类
2 mock模块
Object 解析
MockDataGenerate 离线模拟数据生成
负责生成离线模拟数据并写入Hive表中,模拟数据包括用户行为信息、用户信息、产品数据信息等
MockRealtimeDataGenerate 实时模拟数据生成
负责生成实时模拟数据并写入Kafka中,实时模拟数据为实时广告数据
3 analyse
这个是具体实现需求的模块,下面我们会在实战中为大家介绍。
一共有
session(用户行为)
page(页面)
product(商品信息)
ad(广告)
四个模块。
具体的实战呢,我们在下一章节为大家介绍