一 本章内容介绍:
本章内容介绍spark的概念及安装
1.1 为什么要用spark
V1.0时代 MapReduce
过去五年里,许多企业已慢慢开始接受Hadoop生态系统,将它用作其大数据分析堆栈的核心组件。尽管Hadoop生态系统的MapReduce组件是一个强大的典范,MapReduce自身并不是连接存储在Hadoop生态系统中的数据的最优秀工具。
V2.0 Hive
Hadoop上的SQL支持一开始是Apache Hive,一种类似于SQL的查询引擎,它将有限的SQL方言编译到MapReduce中。Hive对MapReduce的完全依赖会导致查询的很大延迟,其主要适用场景是批处理模式,而且Hive并不完全支持标准SQL
V3.0
开源社区使用Apache Drill来提供延迟时间更短的交互性查询功能。最新的开源产品是SparkSQL,它支持使用SQL查询Spark中的结构化数据。
当然,还有目前比较强大的工具如麒麟和flink,impala等查询工具等。

1.2 到底什么是spark
spark是一个实现快速通用的集群计算平台。它是由加州大学伯克利分校AMP实验室 开发的通用内存并行计算框架,用来构建大型的、低延迟的数据分析应用程序。它扩展了广泛使用的MapReduce计算
模型。高效的支撑更多计算模式,包括交互式查询和流处理。spark的一个主要特点是能够在内存中进行计算,依赖磁盘进行复杂的运算,Spark依然比MapReduce更加高效。
1.3 spark架构简介
Spark组成(BDAS):全称伯克利数据分析栈,通过大规模集成算法、机器、人之间展现大数据应用的一个平台。也是处理大数据、云计算、通信的技术解决方案。
它的主要组件如图所示:

Spark Core:
包含Spark的基本功能;尤其是定义RDD的API、操作以及这两者上的动作。其他Spark的库都是构建在RDD和Spark Core之上的
Spark SQL:
提供通过Apache Hive的SQL变体Hive查询语言(HiveQL)与Spark进行交互的API。每个数据库表被当做一个RDD,Spark SQL查询被转换为Spark操作。
Spark Streaming:
对实时数据流进行处理和控制。Spark Streaming允许程序能够像普通RDD一样处理实时数据
MLlib:
一个常用机器学习算法库,算法被实现为对RDD的Spark操作。这个库包含可扩展的学习算法,比如分类、回归等需要对大量数据集进行迭代的操作。
GraphX:
控制图、并行图操作和计算的一组算法和工具的集合。GraphX扩展了RDD API,包含控制图、创建子图、访问路径上所有顶点的操作
4 spark的优势
Spark优势
1 打造全栈多计算凡是的高效数据流水线
支持MR, SQL查询, 流式计算, 机器学习和图算法, 用户可以在一个工作流无缝搭配这些计算范式
2 轻量级快速处理
Scala简化了代码
利用了第三方组件
基于内存计算,减少了磁盘IO
3 易于使用,支持多语言
支持Scala,Java,Python
自带80多个算子
4 ExternalDataSource多数据支持
5 社区活跃度高
二 安装spark 集群
2.1 spark运行模式简介
- Spark的运行模式多种多样,灵活多变,部署在单机上时,既可以用本地模式运行,也可以用伪分布模式运行,而当以分布式集群的方式部署时,也有众多的运行模式可供选择,这取决于集群的实际情况,底层的资源调度即可以依赖外部资源调度框架,也可以使用Spark内建的Standalone模式。
具体来说:对于外部资源调度框架的支持,目前的实现包括相对稳定的Mesos模式,以及hadoop YARN模式
本地模式:常用于本地开发测试,本地还分别 local 和 local cluster
standalone: 独立集群运行模式
Mesos:Spark可以运行在Mesos里面(Mesos 类似于yarn的一个资源调度框架)
YARN:Spark可以运行在yarn上面
2.2 安装jdk
2.2.1 卸载原有jdk
(1)查询是否安装java软件:
[root@hadoop101 opt]# rpm -qa|grep java
(2)如果安装的版本低于1.7,卸载该jdk:
[root@hadoop101 opt]# rpm -e 软件包
2.2.2 下载jdk并且安装
(1)下载
登录Oracle官网http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html,同意协议条款,选择64位Linux版tar包链接,可以直接单击链接下载,推荐通过多线程下载工具(比如迅雷)加速下载。
2)用SecureCRT工具将jdk、Hadoop-2.7.2.tar.gz导入到opt目录下面的software文件夹下面

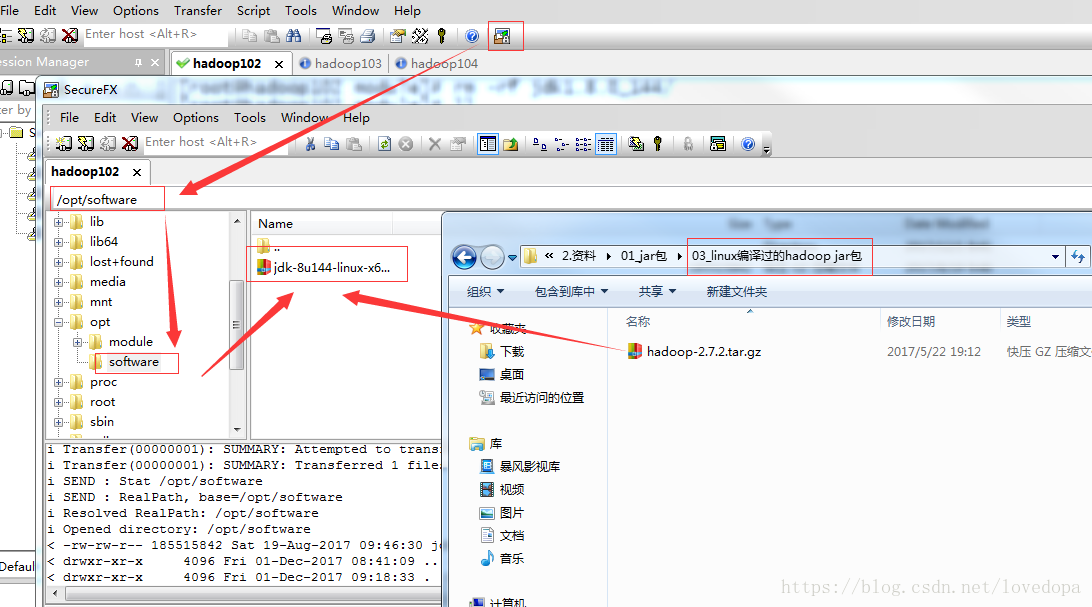
3)在linux系统下的opt目录中查看软件包是否导入成功。
[root@hadoop101opt]# cd software/
[root@hadoop101software]# ls
hadoop-2.7.2.tar.gz jdk-8u144-linux-x64.tar.gz
4)解压jdk到/opt/module目录下
[root@hadoop101software]# tar -zxvf jdk-8u144-linux-x64.tar.gz -C /opt/module/
5)配置jdk环境变量
(1)先获取jdk路径:
[root@hadoop101 jdk1.8.0_144]# pwd
/opt/module/jdk1.8.0_144
(2)打开/etc/profile文件:
[root@hadoop101 jdk1.8.0_144]# vi /etc/profile
在profie文件末尾添加jdk路径:
##JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_144
export PATH=$PATH:$JAVA_HOME/bin
(3)保存后退出:
:wq!
(4)让修改后的文件生效:
[root@hadoop101 jdk1.8.0_144]# source /etc/profile
(5)重启(如果java -version可以用就不用重启):
[root@hadoop101 jdk1.8.0_144]# sync
[root@hadoop101 jdk1.8.0_144]# reboot
6)测试jdk安装成功
[root@hadoop101 jdk1.8.0_144]# java -version
java version "1.8.0_144"
2.3 下载spark安装包
(1)登录Spark官网
http://spark.apache.org/downloads.html
(2)第1个选择spark发行版(选择2.2.0版),第2个选择软件包类型(选择Hadoop 2.7),第3个选择下载类型(直接下载较慢,选择Select Apache Mirror)
(3)单击spark-2.2.0-bin-hadoop2.7.tgz链接,选择国内镜像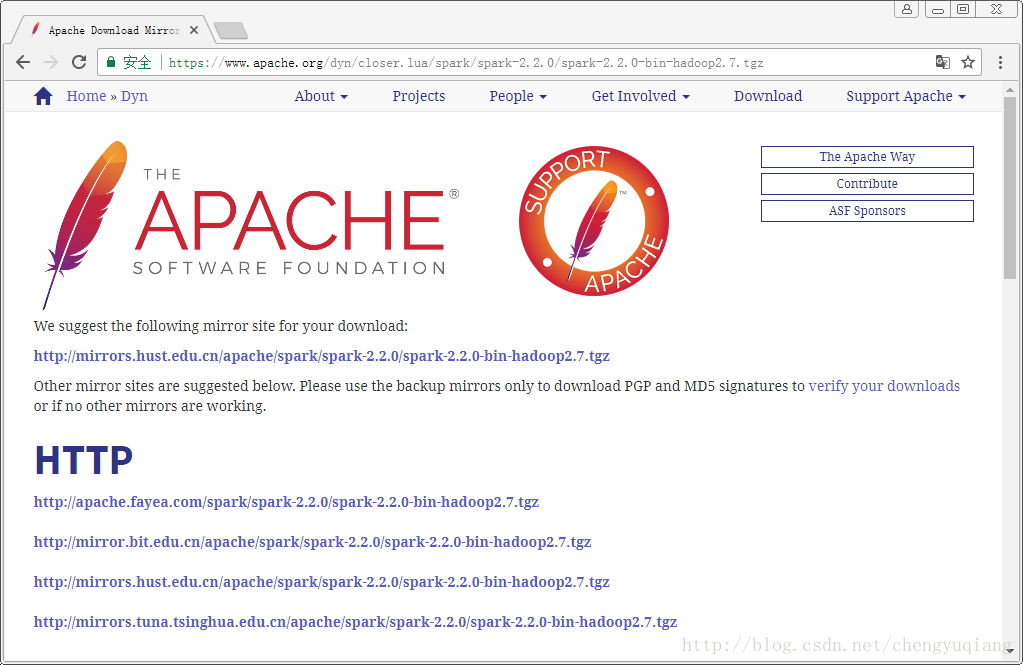

把下载好的文件上传到opt目录下,解压到
(4)然后解压缩/opt目录。我们约定Linux平台下第三方软件包都放到/opt目录下。
[root@master ~]# tar -zxvf spark-2.2.0-bin-hadoop2.7.tgz -C /opt2.4 安装spark-standalone模式
将slaves.template复制为slaves
将spark-env.sh.template复制为spark-env.sh
配置Spark【Standalone】
Spark的部署模式有Local、Standalone、Yarn、Mesos,我们选择最具代表的standalone模式
修改spark-env.sh文件,添加如下配置:
export JAVA_HOME=/opt/module/jdk1.8.0_144
export SPARK_MASTER_IP=linux102
export SPARK_MASTER_PORT=7077
重命名并修改slaves.template文件
mv slaves.template slaves
vi slaves
在该文件中添加子节点所在的位置(Worker节点)
linux102
linux103
linux104
保存退出
将配置好的Spark文件分发到其他节点上
Spark集群配置完毕,目前是1个Master,2个Work,master01上启动Spark集群
/opt/module/spark/sbin/start-all.sh
启动后执行jps命令,主节点上有Master进程,其他子节点上有Work进行,登录Spark管理界面查看集群状态(主节点):http://master01:8080/
注意:如果遇到 “JAVA_HOME not set” 异常,可以在sbin目录下的spark-config.sh 文件中加入如下配置:
export JAVA_HOME=XXXX
2.4.1 Spark集群配置完毕,目前是1个Master,2个Work,在linux102上启动Spark集群
启动后执行jps命令,主节点上有Master进程,其他子节点上有Work进行,登录Spark管理界面查看集群状态(主节点):http://linux102:8080/
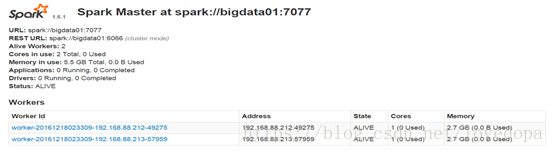
2.5 搭建HA
1 spark HA配置 :
master=linux101,linux102, works = linux103,linux104
Spark集群安装完毕,但是有一个很大的问题,那就是Master节点存在单点故障,要解决此问题,就要借助zookeeper,并且启动至少两个Master节点来实现高可靠,配置方式比较简单:
安装配置zk集群,并启动zk集群(之前博客文档有详解,自行查看并配置 ,不解释)
我们将zk集群安装在了 linux102,linux103,linux104 上面
2 修改配置文件
停止spark所有服务,在linux102上修改配置文件spark-env.sh,在该配置文件中删掉SPARK_MASTER_IP并添加如下配置
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=linux102:2181,linux103:2181,linux104:2181 -Dspark.deploy.zookeeper.dir=/spark"
最终效果大概如图所示

之后使用xsync脚本进行复制,使用xsync脚本请参考
或者用scp也可以
scp -r conf/ linux102:/usr/app/spark-xxx-hadoopx.x/conf
scp -r conf/ linux103:/usr/app/spark-xxx-hadoopx.x/conf
scp -r conf/ linux104:/usr/app/spark-xxx-hadoopx.x/conf
3 测试集群情况
Spark集群配置完毕,目前是1个Master,3个Work,在linux102上启动Spark集群
/opt/module/spark/sbin/start-all.sh
然后在linux101上执行sbin/start-master.sh启动第二个Master
启动后执行jps命令,主节点上有Master进程,其他子节点上有Work进行,登录Spark管理界面查看集群状态(主节点):http://linux102:8080/ 主master alive(你在那个主机启动star-all.sh命令,那么该主机即为master(alive)
http://linux102:8080/ 辅master standby
整完后自己可以测一下spark ha集群的高可用性,手动kill -9 master(主)进程号, 看看过一会另一台standby master是否会自动转变为 alive master
如果大家只开了3台虚拟机,那么可以把linux101的主节点替换到linux103,大家理解原理即可。
2.6 spark-yarn模式
spark的提交模式一共有三种,分别是:standalone,yarn-cluster模式还有yarn-client模式
第一种,standalone模式的搭建前面已经介绍过了。
第二种,是基于YARN的yarn-cluster模式。
第三种,是基于YARN的yarn-client模式。
要切换到第二种和第三种模式,很简单,将我们之前用于提交spark应用程序的spark-submit脚本,加上--master参数,设置为yarn-cluster,或yarn-client,即可。如果你没设置,那么,就是standalone模式。
配置方法:
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>修改Spark-env.sh 添加:
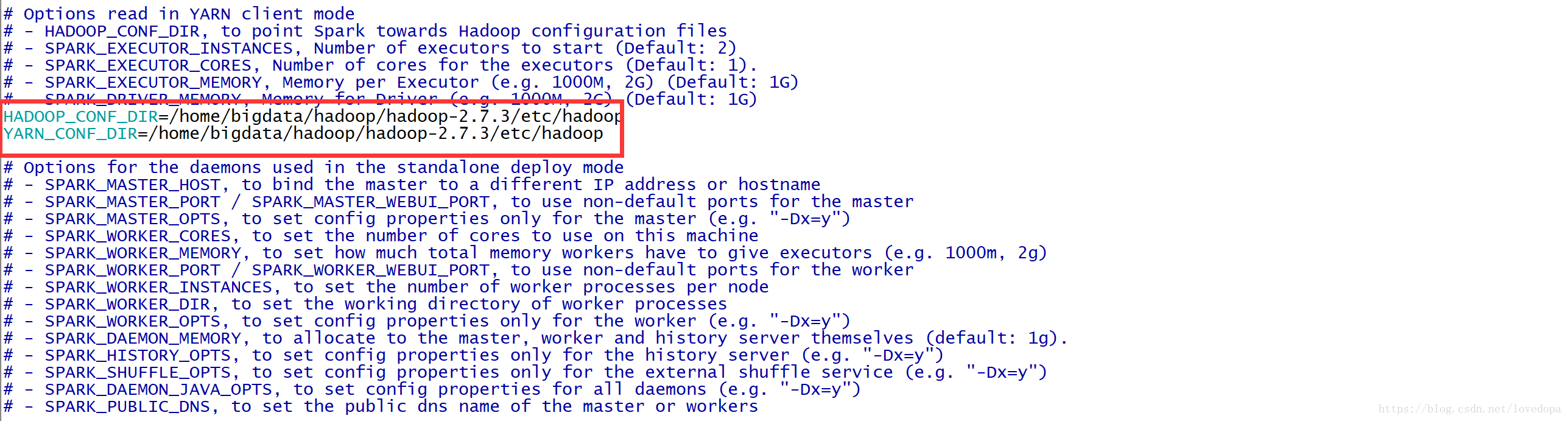
让Spark能够发现Hadoop配置文件
HADOOP_CONF_DIR=/home/bigdata/hadoop/hadoop-2.7.3/etc/hadoop
YARN_CONF_DIR=/home/bigdata/hadoop/hadoop-2.7.3/etc/hadoop
之后启动jobHistoryServer
如果有问题,参考