1 变量
1.1变量定义的规则
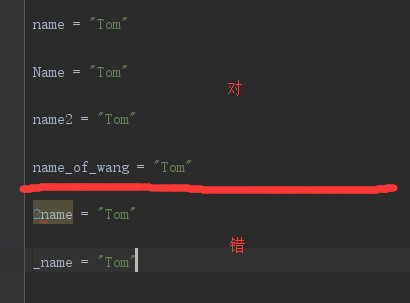
1)变量名只能是字母、数字或下划线的任意组合
2)变量名的第一个字符不能是数字
3)以下的关键字不能声明为变量名
[and, sa, assert, break, class, continue, def, del, elif, else, except, exec, finally, for, from, global, if, import, in, is, lambda, not, or, pass, print, ralse, return, try, while, with, yield]
2 字符编码
python解释器在加载.py文件中的代码时,会对内容进行编码(默认ASCII)。
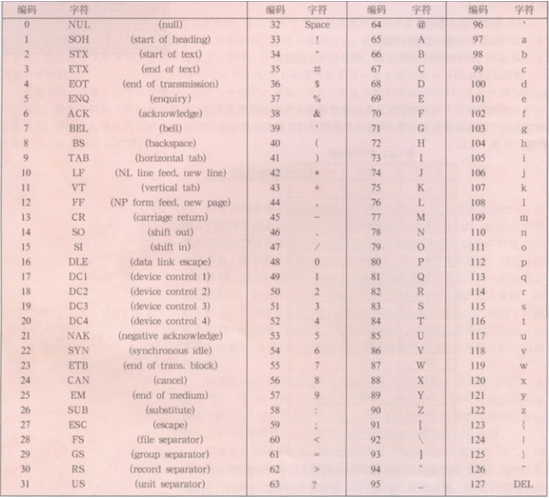
ASCII码(美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,其最多只能用8位来表示(一个字节),即:2**8=256-1,所以,ASCII码最多只能表示255个符号。
关于中文,为了处理汉字,程序员设计了用于简体中文的GB2313和用于繁体中文的big5.
GB2313(1980年)一共收录了7445个字符,包括6763个汉字和682个其他字符。汉字区的内码范围高字节从B0-F7,低字节从A1-FE,占用的码位是72*94=6768.其中五个空位是D7FA-D7FE。
GB2312支持的汉字太少。1995年的汉字拓展规范GBK1.0收录了21888个符号它分为汉字区和图形符号区。汉字区包括21003个字符。2000年的GB18030是取代GBK1.0的正式国家标准。该标准收录了27484个汉字,同时还收录了藏文、蒙文、维吾尔文等主要少数民族文字。现在的PC平台必须支持BG18030,对嵌入式产暂时不做要求。
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。Unicode是为了解决传统的字符编码方案的局限性而产生的,他为每种语言的每个字符设定了统一并且唯一的二进制编码,规定虽有的字符和符号最少由16位来表示(2个字节),即:2**16=65536.。
UTF-8,是对Unicode编码的压缩和优化,他不再使用最少使用2个字节,而是将所有的字符和富豪进行分类:ascii'码中的内容用一个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存...
3 注释
1)当行注释:#被注释内容
2)多行注释:''' 被注释内容'''
4 用户交互程序
"name","age","job","salary"由键盘输入
定义变量info2为如下程序,带入"name","age","job","salary"
输出info2

5 if else 流程判断
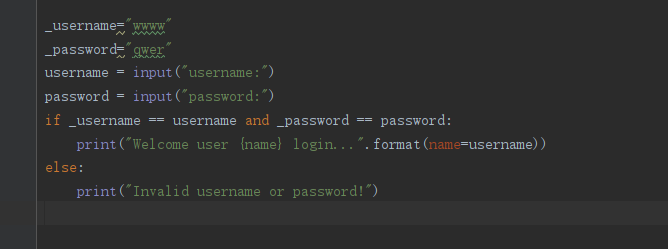
用户名密码判断:
预设用户名位wwww
预设密码位qwer
用户名键盘输入
密码键盘输入
如果用户名等于预设用户名并且密码等于预设密码,输出”欢迎用户***进入。“
如果不,输出无效用户名或者密码
6 while循环
老男孩的年龄为56
键盘输入猜测年龄
如果猜测年龄等于老男孩年龄,输出"you are right"
如果猜测年龄大于老男孩年龄,输出"think bigger!!!"
如果猜测年龄小于老男孩年龄,输出"think smaller!!!"
如果猜错三次,询问"do you want again?"
如果键盘不输入no,继续猜测年龄
如果键盘输入no,结束。

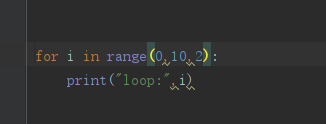
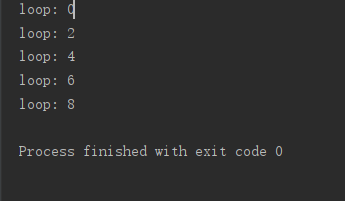
7 for循环
for i in range (n,m,x)
n:开始值
m:结束值+1
x:步长,默认为1