python爬虫-xpath爬贴吧图片---------------(1)
python爬虫-xpath爬贴吧图片---------------(2)
关于xpath的相关内容请查看上篇python爬虫-xpath爬贴吧图片---------------(1)
接下来进入实战案例!!!
我使用的是Chrome浏览器(即谷歌浏览器),Chrome插件 XPath Helper
安装完成应该和下面一样,自己安装一下吧
我来爬一下火影忍者吧的图片
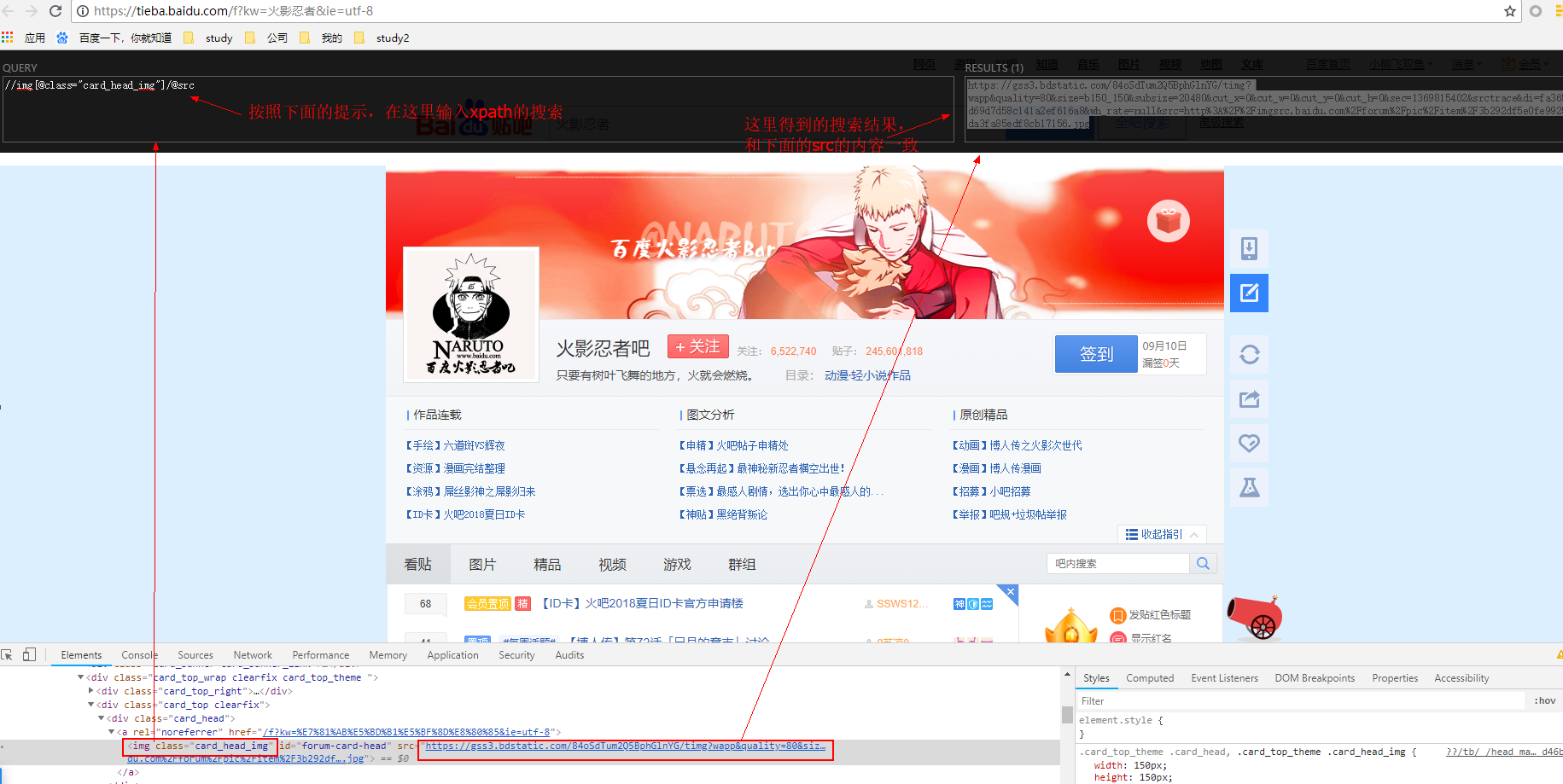
我们先来爬一下贴吧的头像
1.具体操作:进入贴吧->右击头像->检查
可以看出src的链接就是图片的下载地址
2.然后我们使用XPath Helper来查看一下,在网页空白的地方点一下,使用快捷键Ctrl+Shift+x,就会出现小黑框,使用xpath语法就可以查找到该图片的下载地址


3.我们用程序把图片爬下来吧,开动开动!!
代码在/crawler/base/urllib2_re_xml/tieba_picture.py
#coding=utf-8
import urllib2
from lxml import etree
def main():
url= 'https://tieba.baidu.com/f?kw=%E7%81%AB%E5%BD%B1%E5%BF%8D%E8%80%85&ie=utf-8'
header = {"User-Agent": "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1 Trident/5.0;"}
request=urllib2.Request(url,headers=header)
html=urllib2.urlopen(request).read()
#解析html为HTML文档
selector=etree.HTML(html)
# 结果返回的是一个列表
links=selector.xpath('//img[@class="card_head_img"]/@src')
print links[0]
request = urllib2.Request(links[0], headers=header)
img = urllib2.urlopen(request).read()
# wb表示写成二进制文件
with open("./images/head_img.jpg","wb") as file:
file.write(img)
if __name__ == '__main__':
main()
代码再升级一下:如果我们想爬取贴吧内的每个帖子的图片,怎么爬取呢?
拿火影忍者吧 举例思路如下:
1.先进入火影忍者吧
2.先爬取每个贴吧帖子的连接地址
3.遍历这些链接地址再爬取其中的图片
按照这三步走战略,代码如下
代码在/crawler/base/urllib2_re_xml/tieba_xpath.py
#coding=utf-8
import urllib2
from lxml import etree
def main():
# 1. 先进入火影忍者吧
url= 'https://tieba.baidu.com/f?ie=utf-8&kw=%E7%81%AB%E5%BD%B1&fr=search'
header = {"User-Agent": "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1 Trident/5.0;"}
request=urllib2.Request(url,headers=header)
html=urllib2.urlopen(request).read()
#解析html为HTML文档
selector=etree.HTML(html)
# print selector
# 2. 先爬取每个贴吧帖子的连接地址
links=selector.xpath('//div[@class="threadlist_title pull_left j_th_tit "]/a/@href')
counter = 0
# 3. 遍历这些链接地址再爬取其中的图片
for link in links:
img_url= 'https://tieba.baidu.com'+link
request=urllib2.Request(img_url,headers=header)
img_HTML=urllib2.urlopen(request).read()
images_links= etree.HTML(img_HTML).xpath('//img[@class="BDE_Image"]/@src')
for images_link in images_links:
# print images_link
request=urllib2.Request(images_link,headers=header)
img=urllib2.urlopen(request).read()
with open("./images/"+str(counter)+'.png',"wb") as f:
f.write(img)
counter+=1
print counter
#最多爬30多张图片
if (counter>=30):
break
if __name__ == '__main__':
main()
代码放在GitHub上,https://github.com/LoyalWilliams/python-learning.git
以上具体代码在目录/crawler/base/urllib2_re_xml/
有啥私活项目,可以邮箱联系
我的邮箱:[email protected]
我新建了一个大数据的学习交流群
QQ:2541692705
Q群:882855741