版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/ocp114/article/details/82908559
TreeNode<K,V> 是 HashMap 每个桶中数据树化之后用到数据结构也就是红黑树了,TreeNode<K,V> 是从 Node<K,V> 继承而来的,下图初略看看实现和继承的关系
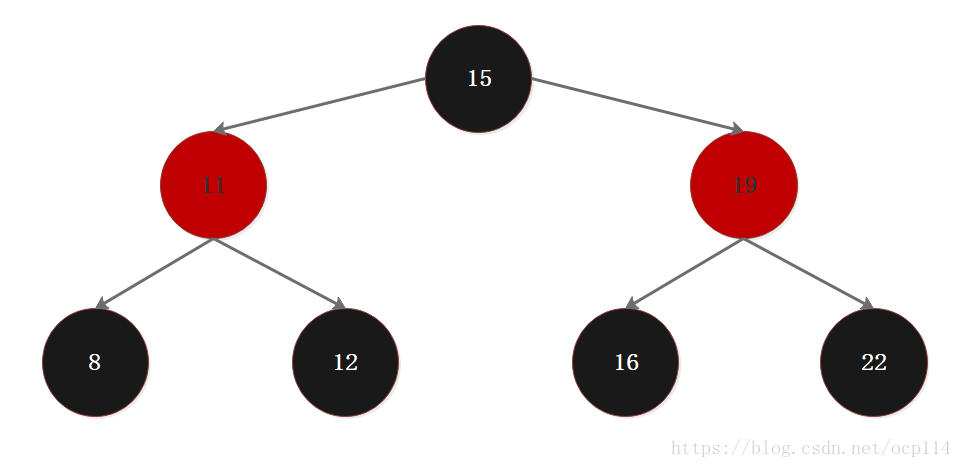
这里由于本人对红黑树的实现挺复杂的,就不深入挖了大概说说红黑树的特性吧

- 把节点当作有颜色地看待的话,有分红色和黑色两种,所以称为红黑树
- 根节点总是黑色的,黑根~
- 如果当前节点是红色的,那么子节点必须是黑色的,但是当前节点是黑色的,子节点不一定要红色的
- 从根节点出发,所能到达的相同层级的每个子孙节点的路径所包含的黑色节点数量必须是相同的
- 在红黑树的操作中主要靠左旋、右旋、变色来维持红黑色节点交替的结构
下面就说说 TreeNode<K,V> 中每个方法的作用吧

// 红黑树两个节点之间的父节点
TreeNode<K,V> parent; // red-black tree links
// 红黑树左节点
TreeNode<K,V> left;
// 红黑树右节点
TreeNode<K,V> right;
// 前驱节点,在删除的时候需要解除绑定关联的元素,个人理解是功能作用类似于链表里面的 next,在删除某个节点的时候,上一个节点的 next 属性需要解绑,
// 有时候也把 parent = pre, 作用应该一样,都是子节点对应上来父节点的关系
TreeNode<K,V> prev; // needed to unlink next upon deletion
// 当前节点是否标红
boolean red;
// 调用父类初始化方法
TreeNode(int hash, K key, V val, Node<K,V> next) { }
// 查找出整棵树的根节点
final TreeNode<K,V> root() { }
// 把根节点移到最前,确保根节点就是桶的第一个元素
static <K,V> void moveRootToFront(Node<K,V>[] tab, TreeNode<K,V> root) { }
/**
** 从根节点开始遍历查找
* @param h 要查找的节点的 hash 值
* @param k 要查找的节点的 key 值
* @param kc 比较器的类型,用来和 Key 的类型做比较,一般在 put 的时候用到,对比 key 是否相同,然后再做后续处理
* @return
*/
final TreeNode<K,V> find(int h, Object k, Class<?> kc) { }
// 从根节点开始查找
final TreeNode<K,V> getTreeNode(int h, Object k) { }
// 当遇到两个对象的 hash 值(在这里基本上是指 key)无法比较时,会使用两个对象的引用来比较,在插入元素以及树化的时候会用到
// HashMap 中的解释是,即使遇到相同的 hash 值,不需要完全保证树的有序性,大家使用的插入规则一样就可以使得整棵树平衡了
static int tieBreakOrder(Object a, Object b) { }
// 由链表树化成红黑树
final void treeify(Node<K,V>[] tab) { }
// 由红黑树退化成链表
final Node<K,V> untreeify(HashMap<K,V> map) { }
// 如果桶中的元素是红黑树的话,就需要用这个方法来添加元素了
final TreeNode<K,V> putTreeVal(HashMap<K,V> map, Node<K,V>[] tab, int h, K k, V v) { }
// 移除节点
final void removeTreeNode(HashMap<K,V> map, Node<K,V>[] tab, boolean movable) { }
// 会对桶中的元素重新排列(也称作树的修剪),树化的过程以及退化成链表的过程都从这里开始
final void split(HashMap<K,V> map, Node<K,V>[] tab, int index, int bit) { }
/* ------------------------------------------------------------ */
// Red-black tree methods, all adapted from CLR
// 红黑树左旋
static <K,V> TreeNode<K,V> rotateLeft(TreeNode<K,V> root, TreeNode<K,V> p) { }
// 红黑树右旋
static <K,V> TreeNode<K,V> rotateRight(TreeNode<K,V> root, TreeNode<K,V> p) { }
// 红黑树的数据插入方法,这里面需要用到上面的左旋和右旋操作,主要是为了维持红黑树的结构,插入时需要对树的结构重新调整
static <K,V> TreeNode<K,V> balanceInsertion(TreeNode<K,V> root, TreeNode<K,V> x) { }
// 和插入的方法一样,平衡删除的操作在删除节点时同样需要对树的结构重新调整以维持红黑树的结构
static <K,V> TreeNode<K,V> balanceDeletion(TreeNode<K,V> root, TreeNode<K,V> x) { }
/**
* Recursive invariant check
*/
// 在对树进行处理的时候, 递归检查要插入的节点是否符合红黑树的规则
static <K,V> boolean checkInvariants(TreeNode<K,V> t) {}
}