由于TreeNode本身是红黑树的实现,所以在分析TreeNode的之前我还是摸了一篇算法导论里红黑树的读书笔记:算法导论——红黑树,从伪代码行数也可以看出完整的红黑树的插入和删除操作代码是很长的,下面源码分析部分的行数就更多了,所以所谓手写红黑树画个图分析下逻辑还行,手写代码估计要写死(滑稽)
TreeNode从JDK8开始引入,作用是当HashMap解决冲突的链表长度超过了8时,生成一个红黑树来加速查找和插入,这里树结构存在并不影响本身依然存在线性链表结构,意思是Node.next这个属性依然有效,所以说树替换了线性链表依然还是链表法解决冲突,只不过链表的实现策略换了。当结点因为移除或分裂操作少于6个时,消除树结构。虽然生产树之后能加快查找插入和删除,但是建立和消除树本身是存在消耗的,所以在两个临界值之间来回插入和删除会导致开销快速增加。HashMap的源码分析见:Java HashMap类源码解析
红黑树是基于二叉搜索树扩展而来,对于TreeNode来说排序的依据是结点的hash值,若相等然后比较key值,若key不能比较或是相等则根据hash值,左儿子的hash值小于等于父亲,右儿子的hash值大于父亲。TreeNode 保有红黑树的性质:
- 每个结点都是红色的或者是黑色的
- 根结点是黑色的
- 每个叶结点NIL是黑色的,但是通常我们不考虑NIL叶结点。
- 如果一个结点是红色的,它的两个子结点都是黑色的
- 每个结点到其他所有后代叶结点的简单路径上,均包含相同数目的黑色结点,这个属性被称为黑高,记作bh(x)
先来看一下TreeNode扩展的内部属性

TreeNode<K,V> parent; //父亲结点
TreeNode<K,V> left; //左儿子
TreeNode<K,V> right; //右儿子
TreeNode<K,V> prev; //前方结点
boolean red;//是否是红色
根据他的构造函数向上追溯TreeNode<K,V>继承了LinkedHashMap.Entry<K,V>而后者又继承了HashMap.Node<K,V>。所以TreeNode依然保有Node的属性,同时由于添加了prev这个前驱指针使得链表变为了双向的。
TreeNode(int hash, K key, V val, Node<K,V> next) {
super(hash, key, val, next);
}
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
下面这个方法可以返回根结点,实现很简单就是不断从一个结点检查parent是否为null
/**
* Returns root of tree containing this node.返回根结点
*/
final TreeNode<K,V> root() {
for (TreeNode<K,V> r = this, p;;) {
if ((p = r.parent) == null)
return r;
r = p;//不断检查parent是否为null,为null的是根结点
}
}
moveRootToFront这个方法的作用是确保根结点被保存在了table数组上面,如果不是的话,就将root从链表中取出,将他放到数组对应的位置上,原本在数组上的结点链接到root的后面。这里最后调用了断言方法checkInvariants,作用是递归检查整棵树是否符合红黑树的性质,若检查不符会返回false导致moveRootToFront抛出错误。
 View Code
View Code
getTreeNode这个方法在HashMap中被多次使用,左右是寻找某个结点所在的树中是否有hash和key值符合的结点。我们可以看到这个方法一定会确保最后调用的是root.find(),也就是说find方法调用时this一定是根结点。所以无论最初调用getTreeNode的结点在树中处于什么位置,最后都会从根结点开始寻找,由于红黑树是相对平衡的二叉搜索树,所以可以认为搜索时间相比于链表从O(n)下降到了O(lgn)
View Code
下面这个treeify就是根据链表生成树了,遍历链表获取结点,一个个插入到红黑树中,每次插入从根开始根据hash值寻找到叶结点位置进行插入,插入一个结点后调用一次balanceInsertion(root, x)检查x位置的红黑树性质是否需要修复。tieBreakOrder(k, pk)是在插入结点的key值k和父结点的key值pk无法比较出大小时,用于比较k和pk的hash值大小。关于红黑树性质的修复和保持稍后一起讨论。
View Code
untreeify的作用就是把树转为链表,由于replacementNode这个方法会生成新的Node,所以产生的新链表不再具有树的信息了,原本的TreeNode被gc了。
View Code
拆分这个方法只有在resize的时候调用,可以对照线性链表扩展的情况,作用是把树拆成两棵,一棵放到新扩展出来的数组高位去,一棵留在原来的位置,划分的依据是扩展后新增的hash有效位是0还是1,拆分的时候会破坏树结构,所以先拆成两个链表再调用treeify来组装树。
View Code
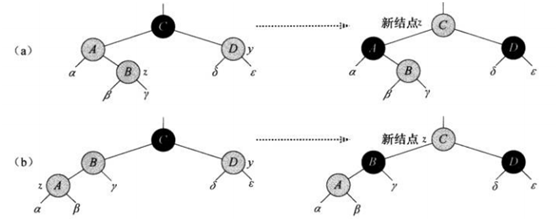
下面开始要进入插入和删除操作部分分析了,为了便于说明把之前那篇几张关键的图贴过来方便与代码进行对照
旋转
如图所示是基本的左旋和右旋操作,这部分对着图看很容易理解

View Code
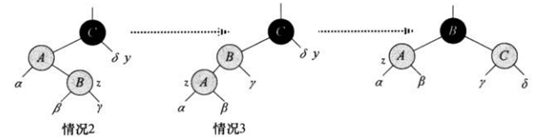
插入
插入分为如图所示的3中情况,具体描述和处理方法见文章最前面的链接。
 情况1
情况1
插入操作涉及到两段很长的代码,首先是putTreeVal只要有h和k值符合的结点就不做插入,这里k必须是==或者equals才算是相等,返回找到的结点由调用的方法修改已有结点的value值,否则插入一个新结点并返回null。前面提到过,结点在树中的排序按照hash值大小,再按照key的大小,最后比较key计算Hash的大小进行排列,对应方法中的查找逻辑。
View Code
balanceInsertion是插入后用于维持红黑树性质的修复操作,这里涉及到了上面图中展示的3中情况不同的操作
View Code
删除
最后是删除操作部分,删除操作需要寻找一个后驱结点来顶替原结点的位置,在结点无儿子时删除后不需做其他调整,结点只有一个儿子时那个儿子是后驱,否则右子树中的最小结点作为后驱。
View Code
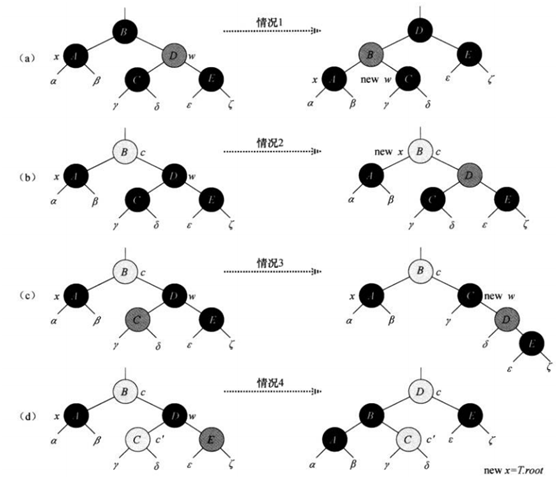
同样有删除和删除之后维持红黑树性质的修复操作,这里涉及到图中展示的4种不同情况的操作
View Code
个人GitHub地址: https://github.com/GrayWind33