主成分分析和因子分析的理论与速成应用丨R语言和SPSS比较案例
本章内容
□ 主成分分析
□ 探索性因子分析
□ 理解其他潜变量模型
学习计划:

背景
在实际的科学研究中,为了更好地、全面地、完整地把握和认识问题,我们往往对反映问题的多个变量进行大量观测,尽可能多地收集关于分析对象的数据信息。在大多数情况下,这些变量之间可能存在着相关性,从而增加了数据分析的复杂性。为了更能充分有效地利用数据,通常希望用较少的指标来代替原先较多的变量,同时又要求这些较少的指标尽可能多地反映原始变量的信息,而这些指标之间又互不相关。在本章中的主成分分析和因子分析就是解决这类问题的方法之一。
主成分分析(PCA)是一种数据降维技巧,它能将相关变量转化为一组很少的不相关变量,这些无关变量称为主成分。例如,使用PCA可将30个相关(很可能冗余)的环境变量转化为5个无关的成分变量,并且尽可能地保留原始数据集的信息。
探索性因子分析(EFA)是一系列用来发现一组变量的潜在结构的方法。它通过寻找一组更小的、潜在的或隐藏的结构来解释已观测到的、显式的变量间的关系。
PCA与EFA模型间的区别参见下图。
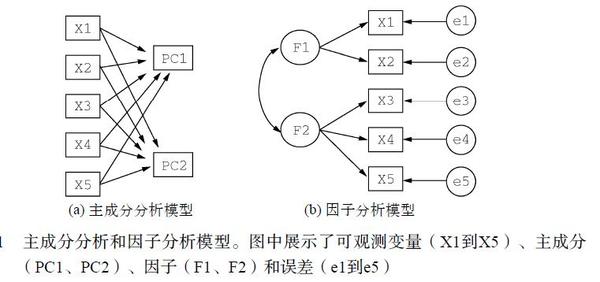
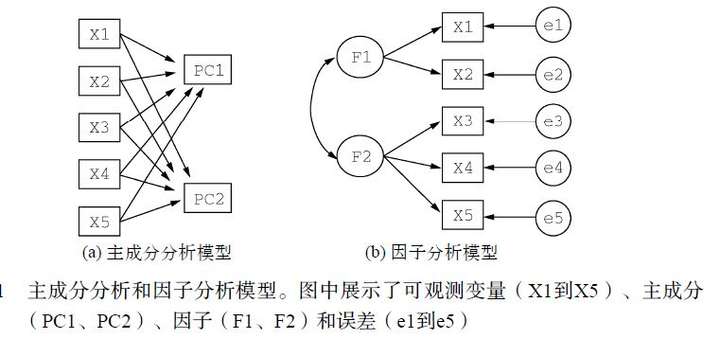
主成分(PC1和PC2)是观测变量(X1到X5)的线性组合。形成线性组合的权重都是通过最大化各主成分所解释的方差来获得,同时还要保证各主成分间不相关。
什么叫最大化各主成分所解释的方差?如何验证各主成分间的独立性?
因子(F1和F2)被当做观测变量的结构基础或“原因”,而不是他们的线性组合。代表观测变量方差的误差(e1到e5)无法用因子来解释。图中的圆圈表示因子和误差无法直接观测,但是可通过变量间的相互关系推导得到。在本例中,因子间带曲线的箭头表示它们之间的相关性。在EFA模型中,相关因子是常见的,但并不是必须的。
1.R中的主成分和因子分析丨R
R的基础安装包提供了PCA和EFA的函数,分别为princomp()和factanal()。本章我们将重点介绍psych包中提供的函数。它们提供了比基础函数更丰富和有用的选项。另外,输出的结果形式也更为社会学家所熟悉,与其他统计软件如(SAS和SPSS)所提供的输出十分相似。
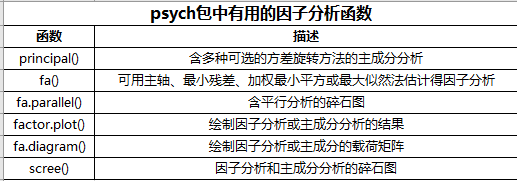
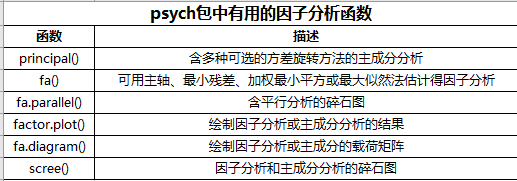
最常见的EFA处理步骤如下:
- 数据预处理。PCA和EFA都根据观测变量间的相关性来推导结果。用户可以输入原始数据矩阵或者相关系数矩阵到principal()和fa()函数中。若输入初始数据,相关系数矩阵将会自动计算,在计算前请确保数据中没有缺失值。
- 选择因子模型。判断是PCA(数据降维)还是EFA(发现潜在结构)更符合你的研究目标。如果选择EFA方法,你还需要选择一种估计因子模型的方法(如最大似然估计)。
- 判断要选择的主成分/因子数目。
- 选择主成分/因子。
- 旋转主成分/因子。
- 解释结果。
- 计算主成分或因子得分。
******************************************************************************************
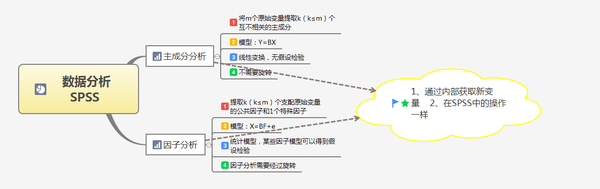
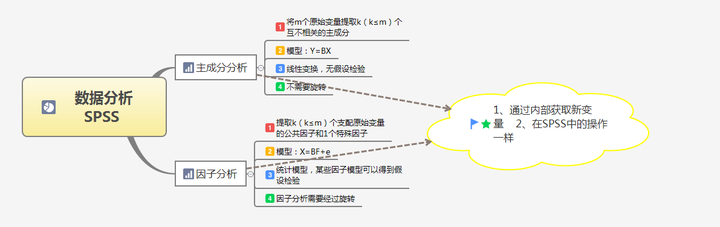
一、主成分分析
2.主成分分析丨SPSS
2.1主成分分析原理和方法
主成分分析(Principal Component Analysis)的思维就是利用降维思想,将多个互相关联的数值变量转化成少数几个互不相关的综合指标的统计方法。这些综合指标就是原来多个变量的主成分,每个主成分都是原始变量的线性组合,并且各个主成分之间互不相关。
主成分分析的任务之一就是计算主成分,计算步骤是:首先将原有的变量标准化,然后计算各变量之间的相关矩阵、该矩阵的特征根和特征向量,最后将特征根由大到小排列,分别计算出对应的主成分。
主成分分析的另一个任务是确定主成分的个数,确定方法主要有两种:
- 累计贡献率:当前k个主成分的累计贡献率达到某一特定值(一般采用70%以上)时,则保留前k个主成分;
- 特征根:一般选取特征根≥1的主成分。
2.2 主成分分析中的相关概念
- 特征根(Eigenvalue):表示主成分影响力度大小的指标,即引入该主成分后可以解释平均多少原始变量的信息。如果特征根小于1,说明该主成分的解释程度还不如直接引入一个原始变量的平均解释程度大,因此在确定主成分个数时,常常选取特征根大于1的主成分。
- 主成分Zi的方差贡献率,计算公式为:
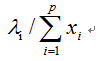
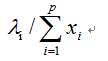
式中分子表示主成分Zi的方差在全部方差中的比重。这个值越大,表明主成分Zi综合原始变量信息的能力越强。
3.累计贡献率:前K个主成分的累计贡献率定义如下,表示前K个主成分累计提取了原始变量多少的信息:
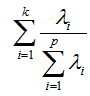
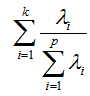
2.3 主成分分析的用途
主要的用途我们在这里介绍两种常用的:
- 主成分评价:在进行多指标综合评价时,由于要求结果客观、全面,就需要从各个方面用多个指标进行测量,但这样就会使得各观测指标间存在信息重叠,同时还存在量纲、累加时如何确定权重系数等问题。因此使用主成分分析方法进行信息的浓缩,并解决权重的确定等问题。
- 主成分回归:在线性模型中,常用最小二乘法求回归系数的估计。但由于共线性的存在,最小二乘法的估计结果并不是很理想。这时我们可以考虑主成分回归求回归系数的估计,所谓主成分回归使用原始自变量的主成分代替原始自变量做回归分析。多重共线性是由于自变量之间关系复杂、相关性大引起的,而主成分既保留了原指标的绝大部分信息,又有主成分之间互不相关的优点,故借用主成分替代原始指标后,再用最小二乘法建立主成分与目标变量之间的回归方程,所得的回归系数估计能克服“估计不稳定”的缺点。但主成分回归不是无偏估计。
2.4 实例与操作丨SPSS
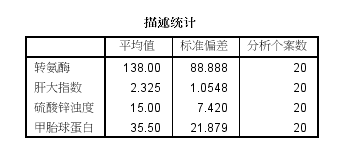
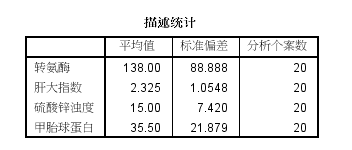
实例:某研究单位测得20名肝病患者4项肝功能指标:转氨酶(x1)、肝大指数(x2)、硫酸锌浊度(x3)、甲胎球蛋白(x4),试做主成分分析。
- 操作:(用软件,比较简单,这里不再介绍)
- 结果解读:
(1)统计描述:包括均数、标准差和样本量,如下图所示:
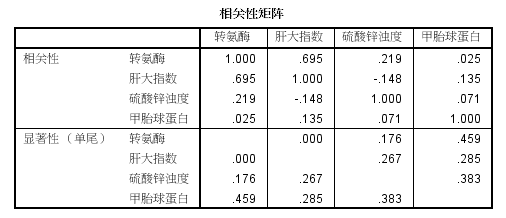
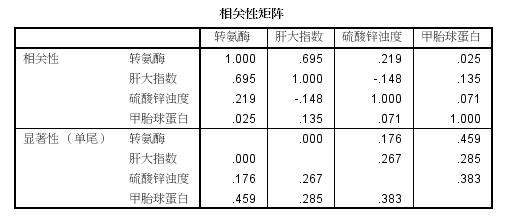
(2)相关矩阵:包含偏相关系数及其相应的P值,如下图所示:
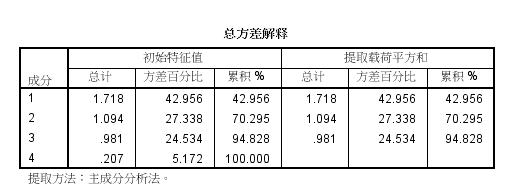
(3)主成分结果如下图所示:包括特征根由大到小的排列顺序、各主成分的贡献率和累计贡献率:第一主成分的特征根为1.718,它解释了总变异的42.956%,第二主成分的特征根为1.094,解释了总变异的27.338%。前两个主成分的特征根均大于1,累计贡献率达到了70.295%。由于第三个主成分的特征根接近于1,且其贡献率与第二主成分相近,故本例选取3个主成分,此时累计贡献率达到了94.828%。

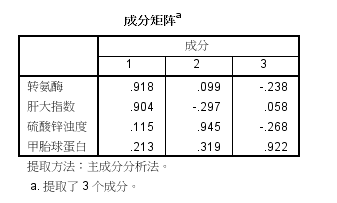
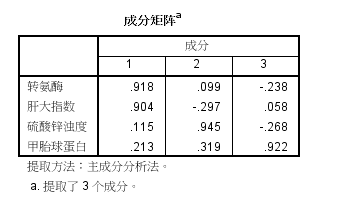
(4)成分矩阵如下图:可见第一主成分包含原变量转氨酶(x1)和肝大指数(x2)的信息,因此第一主成分可作为急性肝炎的描述指标。类似的第二主成分包含原变量硫酸锌浊度(x3)的信息,可作为慢性肝炎的描述指标。第三成分可作为原发性肝癌的描述指标。
(5)如下为因子的得分系数矩阵。这是主成分分析的最终结果,通过该系数矩阵可以将主成分表示为各个变量的线性组合。本题可以写出三个主成分的表达式:
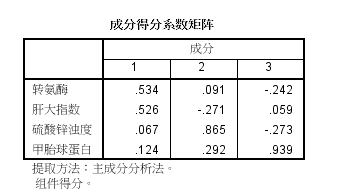
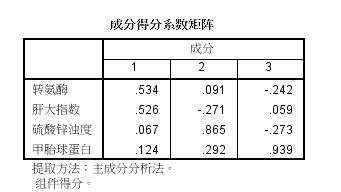
Z1=0.534*stdx1+0.526*stdx2+0.067*stdx3+0.124*stdx4;
Z2=0.091*stdx1-0.271*stdx2+0.865*stdx3+0.292*stdx4
Z3=-0.242*stdx1+0.059*stdx2-0.273*stdx3+0.939*stdx4
其中stdxi(i=1、2、3、4)表示指标变量:
stdx1=(x1-138)/88.888
stdx2=(x2-2.325)/1.0548
stdx3=(x3-15)/7.420
stdx4=(x4-35.5)/21.879
(6)成分得分协方差矩阵:
3 主成分分析丨R
PCA的目标是用一组较少的不相关变量代替大量相关变量,同时尽可能保留初始变量的信息,这些推导所得的变量称为主成分,它们是观测变量的线性组合。如第一主成分为:
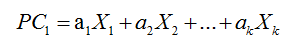

它是k个观测变量的加权组合,对初始变量集的方差解释性最大。第二主成分也是初始变量的线性组合,对方差的解释性排第二,同时与第一主成分正交(不相关)。后面每一个主成分都最大化它对方差的解释程度,同时与之前所有的主成分都正相交。理论上来说,你可以选取与变量数相同的主成分,但从实用的角度来看,我们都希望用较少的主成分来近似全变量集。下面看一个简单的示例。
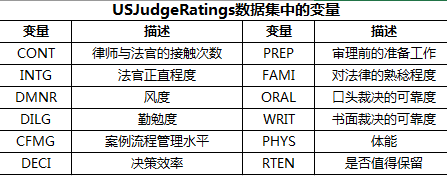
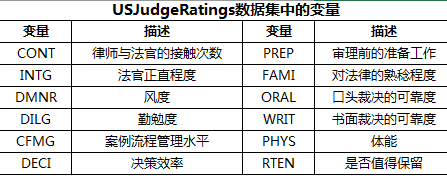
数据集USJudgeRatings包含了律师对美国高等法院法官的评分。数据框包含43个观测,12个变量。如下表列出了所有的变量。
3.1 判断主成分的个数丨R
以下是一些可用来判断PCA中需要多少个主成分的准则:
- 根据先验经验和理论知识判断主成分分数;
- 根据要解释变量方差的积累值的阈值来判断需要的主成分数;
- 通过检查变量间kxk的相关系数矩阵来判断保留的主成分数。
最常见的是基于特征值的方法。每个主成分都与相关系数矩阵的特征值相关联,第一主成分与最大的特征值相关联,第二主成分与第二大的特征值相关联,依次类推。Kaiser-Harris准则建议保留特征值大于1的主成分(此与前面一部分介绍的理论一致),特征值小于1的成分所解释的方差比包含在单个变量中的方差更少。
利用fa.parallel()函数,你可以同时对三种特征值判别准则进行评价。对于11种评分,代码如下:
> install.packages("psych")
> library(psych)
> fa.parallel(USJudgeRatings[,-1],fa="pc",n.iter = 100,
+ show.legend=F,main="Scree plot with parallel analysis")
The estimated weights for the factor scores are probably incorrect. Try a different factor extraction method.
Parallel analysis suggests that the number of factors = NA and the number of components = 1
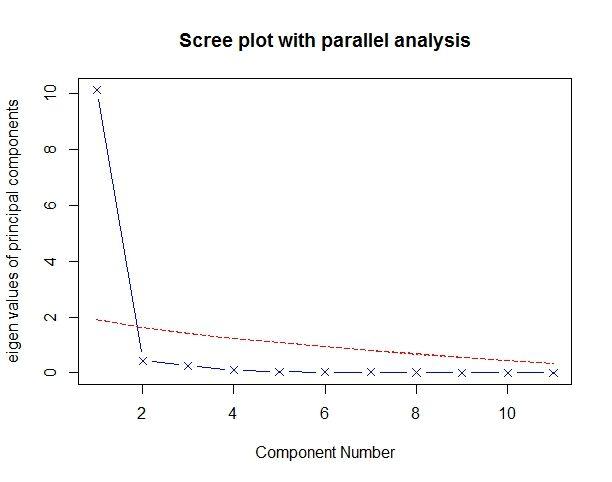
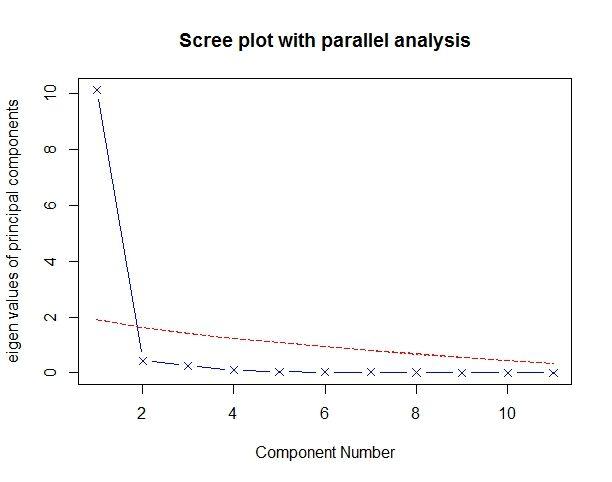
评价美国法官评分中要保留的主成分个数。碎石图(直线与X符号)、特征值大于1准则(水平线)和100次模拟的平行分析(虚线)都表明保留一个主成分即可。
三种准则表明选择一个主成分即可保留数据集的大部分信息。下一步是使用principal()函数挑选出相应的主成分。
3.2 提取主成分
之前已经介绍过,principal()函数可以根据原始矩阵或者相关系数矩阵做主成分分析。格式为:
principal(r,nfactors=,rotate=,scores=)
其中:
- r是相关系数矩阵或原始数据矩阵;
- nfactors设定主成分系数(默认为1);
- rotate指定旋转的方法(默认最大方差旋转(varimax));
- scores设定是否需要计算主成分得分(默认不需要)。
使用代码清单14-1中的代码可获取第一主成分。
代码清单14-1 美国法官评分的主成分分析
> library(psych)
> pc <- principal(USJudgeRatings[,-1],nfactors = 1)
> pc
Principal Components Analysis
Call: principal(r = USJudgeRatings[, -1], nfactors = 1)
Standardized loadings (pattern matrix) based upon correlation matrix
PC1 h2 u2 com
INTG 0.92 0.84 0.1565 1
DMNR 0.91 0.83 0.1663 1
DILG 0.97 0.94 0.0613 1
CFMG 0.96 0.93 0.0720 1
DECI 0.96 0.92 0.0763 1
PREP 0.98 0.97 0.0299 1
FAMI 0.98 0.95 0.0469 1
ORAL 1.00 0.99 0.0091 1
WRIT 0.99 0.98 0.0196 1
PHYS 0.89 0.80 0.2013 1
RTEN 0.99 0.97 0.0275 1
PC1
SS loadings 10.13
Proportion Var 0.92
Mean item complexity = 1
Test of the hypothesis that 1 component is sufficient.
The root mean square of the residuals (RMSR) is 0.04
with the empirical chi square 6.21 with prob < 1
Fit based upon off diagonal values = 1
此处,你输入的是没有CONT变量的原始数据,并指定获取一个未旋转的主成分。由于PCA只对相关系数矩阵进行分析,在获取主成分前,原始数据将会自动转换为相关系数矩阵。
PC1栏包含了成分载荷,指观测变量与主成分的相关系数。如果提取不止一个主成分,那么还将会有PC2、PC3等栏。成分载荷(component loadings)可用来解释主成分的含义。此处可以看到,第一主成分(PC1)与每个变量都高度相关,也就是说,它是一个可用来进行一般性评价的维度。
h2栏指成分公因子方差,即主成分对每个变量的方差解释度。u2栏指成分唯一性,即方差无法被主成分解释的比例(1-h2)。例如,体能(PHYS)80%的方差都可用第一主成分来解释,20%不能。相比而言,PHYS是用第一主成分表示性最差的变量。
SS loadings行包含了与主成分相关联的特征值,指的是与特定主成分相关联的标准化后的方差值(本例中,第一主成分的值为10)。最后,Proportion Var行表示的是每个主成分对整个数据集的解释程度。此处可以看到,第一主成分解释了11个变量92%的方差。
3.3 SPSS的例子用R实现
1.先把数据集导入R
> library(openxlsx)
> data <- read.xlsx(“G:/SPSS/本书源数据/21/data01.xlsx”)
> data
x1 x2 x3 x4
1 40 2.0 5 20
2 10 1.5 5 30
3 120 3.0 13 50
4 250 4.5 18 0
5 120 3.5 9 50
6 10 1.5 12 50
7 40 1.0 19 40
8 270 4.0 13 60
9 280 3.5 11 60
10 170 3.0 9 60
11 180 3.5 14 40
12 130 2.0 30 50
13 220 1.5 17 20
14 160 1.5 35 60
15 220 2.5 14 30
16 140 2.0 20 20
17 220 2.0 14 10
18 40 1.0 10 0
19 20 1.0 12 60
20 120 2.0 20 0
2.提取主成分:(在SPSS中我们已根据特征根判断,需要三个主成分)
> library(psych)
> pc <- principal(data,nfactors = 3)
> pc
Principal Components Analysis
Call: principal(r = data, nfactors = 3)
Standardized loadings (pattern matrix) based upon correlation matrix
RC1 RC2 RC3 h2 u2 com
x1 0.92 0.25 -0.04 0.91 0.092 1.2
x2 0.92 -0.21 0.12 0.91 0.091 1.1
x3 0.02 0.99 0.04 0.98 0.021 1.0
x4 0.04 0.04 1.00 1.00 0.003 1.0
RC1 RC2 RC3
SS loadings 1.69 1.09 1.01
Proportion Var 0.42 0.27 0.25
Cumulative Var 0.42 0.70 0.95
Proportion Explained 0.45 0.29 0.27
Cumulative Proportion 0.45 0.73 1.00
Mean item complexity = 1.1
Test of the hypothesis that 3 components are sufficient.
The root mean square of the residuals (RMSR) is 0.05
with the empirical chi square 0.51 with prob < NA
Fit based upon off diagonal values = 0.98
从上面的结果我们可以查看到与我们SPSS中的数据不一致,经检查,是由于principal()函数中的变量rotate未设置所致,修正后如下:
> pc4 <- principal(data,nfactors = 3,rotate = “none”)
> pc4
Principal Components Analysis
Call: principal(r = data, nfactors = 3, rotate = “none”)
Standardized loadings (pattern matrix) based upon correlation matrix
PC1 PC2 PC3 h2 u2 com
x1 0.92 0.10 -0.24 0.91 0.092 1.2
x2 0.90 -0.30 0.06 0.91 0.091 1.2
x3 0.12 0.95 -0.27 0.98 0.021 1.2
x4 0.21 0.32 0.92 1.00 0.003 1.4
PC1 PC2 PC3
SS loadings 1.72 1.09 0.98
Proportion Var 0.43 0.27 0.25
Cumulative Var 0.43 0.70 0.95
Proportion Explained 0.45 0.29 0.26
Cumulative Proportion 0.45 0.74 1.00
Mean item complexity = 1.2
Test of the hypothesis that 3 components are sufficient.
The root mean square of the residuals (RMSR) is 0.05
with the empirical chi square 0.51 with prob < NA
Fit based upon off diagonal values = 0.98
所得结果与SPSS中的数据一致。
3.4 提取主成分的实例丨R
让我们再来看看第二个例子,它的结果不止一个主成分。Harman23.cor数据集包含了305个女孩的8个身体测量指标。本例中,数据集由变量的相关系数组成,而不是原始数据集。
同样地,我们希望用较少的变量替换这些原始身体指标。如下代码可判断要提取的主成分数。此处,你需要填入相关系数矩阵(Harman23.cor对象中的cov部分),并设定样本大小(n.obs):
> library(psych)
> fa.parallel(Harman23.cor$cov,n.obs = 302,fa=“pc”,n.iter = 100,
-
show.legend=F,main=“Scree plot with parallel analysis”)
Parallel analysis suggests that the number of factors = NA and the number of components = 2

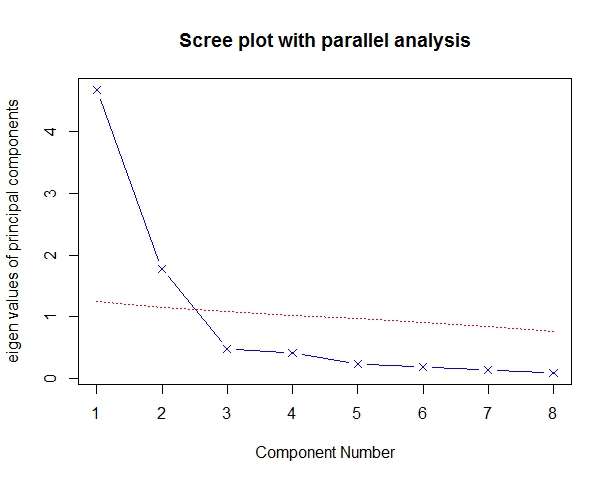
与第一个例子类似,图形中的Kaiser-Harris准则、碎石检验和平行分析都建议选择两个主成分。但是三个准备并不总是相同,你可能根据需要依据实际情况提取不同数目的主成分,选择最优解决方案。代码清单14-2从相关系数矩阵中提取了前两个主成分。
代码清单14-2 身体测量指标的主成成分
> library(psych)
> pc <- principal(Harman23.corKaTeX parse error: Expected 'EOF', got '&' at position 35: …tate = "none") &̲gt; pc Principa…cov, nfactors = 2, rotate = “none”)
Standardized loadings (pattern matrix) based upon correlation matrix
PC1 PC2 h2 u2 com
height 0.86 -0.37 0.88 0.123 1.4
arm.span 0.84 -0.44 0.90 0.097 1.5
forearm 0.81 -0.46 0.87 0.128 1.6
lower.leg 0.84 -0.40 0.86 0.139 1.4
weight 0.76 0.52 0.85 0.150 1.8
bitro.diameter 0.67 0.53 0.74 0.261 1.9
chest.girth 0.62 0.58 0.72 0.283 2.0
chest.width 0.67 0.42 0.62 0.375 1.7PC1 PC2
SS loadings 4.67 1.77
Proportion Var 0.58 0.22
Cumulative Var 0.58 0.81
Proportion Explained 0.73 0.27
Cumulative Proportion 0.73 1.00
Mean item complexity = 1.7
Test of the hypothesis that 2 components are sufficient.
The root mean square of the residuals (RMSR) is 0.05
Fit based upon off diagonal values = 0.99
从代码清单14-2中的PC1和PC2栏可以看到,第一主成分解释了身体测量指标58%的方差,而第二主成分解释了22%,两者总共解释了81%的方差。对于高度变量,两者则共解释了其88%的方差。
荷载阵解释了成分和因子的含义。第一主成分与每个身体测量指标都正相关,看起来似乎是一个一般性的衡量因子;第二主成分与前四个变量(height、arm.span、forearm和lower.leg)负相关,与后四个变量正相关,因此看起来似乎是一个长度-容量因子。但理念上的东西都不容易构建,当提取了多个成分时,对它们进行旋转可使结果更具解释性。
3.5 主成分旋转丨R
旋转是一系列将成分载荷阵变得更容易解释的数学方法,它们尽可能地对成分去噪。旋转方法有两种:使选择的成分保持不相关(正交旋转),和让它们变得相关(斜交旋转)。旋转方法也会依据去噪定义的不同而不同。最流行的正交旋转是方差极大旋转,它试图对载荷阵的列进行去噪,使得每个成分只由一组有限的变量来解释(即载荷阵每列只由少数几个很大的载荷,其他都是很小的载荷)。对身体测量数据使用方差极大旋转,你可以得到如代码清单14-3所示的结果。
代码清单14-3 方差极大旋转的主成分分析
> rc <- principal(Harman23.corKaTeX parse error: Expected 'EOF', got '&' at position 38: …e = "varimax")
&̲gt; rc
Principa…cov, nfactors = 2, rotate = “varimax”)
Standardized loadings (pattern matrix) based upon correlation matrix
RC1 RC2 h2 u2 com
height 0.90 0.25 0.88 0.123 1.2
arm.span 0.93 0.19 0.90 0.097 1.1
forearm 0.92 0.16 0.87 0.128 1.1
lower.leg 0.90 0.22 0.86 0.139 1.1
weight 0.26 0.88 0.85 0.150 1.2
bitro.diameter 0.19 0.84 0.74 0.261 1.1
chest.girth 0.11 0.84 0.72 0.283 1.0
chest.width 0.26 0.75 0.62 0.375 1.2
RC1 RC2
SS loadings 3.52 2.92
Proportion Var 0.44 0.37
Cumulative Var 0.44 0.81
Proportion Explained 0.55 0.45
Cumulative Proportion 0.55 1.00
Mean item complexity = 1.1
Test of the hypothesis that 2 components are sufficient.
The root mean square of the residuals (RMSR) is 0.05
Fit based upon off diagonal values = 0.99
列的名字都从PC变成了RC,以表示成分被旋转。观察RC1栏的载荷,你可以发现第一主成分主要由前四个变量来解释(长度变量)。RC2栏的载荷表示第二主成分主要由变量5到变量8来解释(容量变量)。注意两个主成分仍不相关,对变量的解释性不变,这是因为变量的群组没有发生变化。另外,两个主成分旋转后的累积方差解释性没有发生变化(81%),变的只是各个主成分对方差的解释度。
3.6 获取主成分得分丨R
在美国法官评分例子中,我们根据原始数据中的11个评分变量提取了一个主成分。利用principal()函数,你很容易获得每个调查对象在该主成分上的得分:
代码清单14-4 从原始数据中获取成分得分
> library(psych)
> pc <- principal(USJudgeRatings[,-1],nfactors = 1,score=T)
> head(pcKaTeX parse error: Expected 'EOF', got '&' at position 367: …"><span></span>&̲gt; cor(USJudge…CONT,pcKaTeX parse error: Expected group after '^' at position 112: …可能会有不一样的结果,开个玩笑^̲_^)</p><p> 当主成分…cov,nfactors = 2,rotate = “varimax”)
> round(unclass(rcKaTeX parse error: Expected 'EOF', got '&' at position 853: …"><span></span>&̲gt; library(psy…weights),3)
PC1 PC2 PC3
x1 0.534 0.091 -0.242
x2 0.526 -0.271 0.059
x3 0.067 0.865 -0.273
x4 0.124 0.292 0.939
显然,从结果上看,两者的数据结果都一致。
4 R与SPSS使用的比较
******************************************************************************************
第二、因子分析丨SPSS
背景:许多实际问题不仅涉及的变量众多,而且各个变量之间可能存在在错综复杂的相关关系,这时最好能从中提取少数的综合变量,使其能够包含原变量提供的大部分信息,还要求这些综合变量尽可能地彼此不相关。因子分析就是解决这一问题而提出的统计分析方法。
因子分析方法能把多个观测变量转换为少数几个不相关的综合指标,这些综合指标往往不是能直接观测到的,但有时却更能反映事物的特点和本质。因此,分析在医学、生物学、经济学等诸多领域都得到了广泛的应用。
1、概述丨SPSS
1.1 基本概念
因子分析是一种通过显在变量,通过具体指标评测抽象因子的分析方法,最早是由心理学家Chales Spearman 在1904年提出的。
因子分析的基本目的是用少数几个因子去描述多个变量之间的关系,被描述的变量一般都是能实际观测到的随机变量,而那些因子是不可观测的潜在变量。
因子分析的基本思想是根据相关性的大小把变量分组,使得同组内的变量相关性较高,而不同组内的变量相关性较低。每组变量代表一个基本结构,这些基本结构够成为一个公共因子。对于所研究的问题就可以试图用最少数的不可观测的公共因子的线性函数与特殊因子之和来描述原来观测的每一个分量。
因子分析可以分为两类,一类为探索性因子分析(Exploratory factor analysis),另一类为确定性因子分析(confirmatory factor analysis)。探索性因子分析通常称为因子分析,主要应用在数据分析的初期阶段,其主要目的是探讨可观测变量的特征、性质及内部的关联性,并揭示有哪些主要的潜在因子肯呢个影响这些观测变量,它要求所找出的潜在因子之间相互独立及有实际意义,并且这些潜在因子尽可能多地表达原可观测变量的信息。确定性因子分析是在探索性因子分析的基础上进行的,当已经找到可观测变量可能被哪些潜在因子影响,而进一步确定每一个潜在因子对可观测变量的影响程度,以及这些潜在因子之间的关联程度时,则可进行确定性因子分析。该分析不要求所找出的这些潜在因子之间相互独立,其目的是明确潜在因子之间的关联性,它是将多个指标之间的关联性研究简化为对较少几个潜在因子之间的关联性研究,其分析结果需进行统计检验,确定性因子分析是结构方程模型分析的第一步。
1.2 原理和方法
因子分析的出发点是用较少的相互独立的因子变量代替原来变量的大部分信息,可以用下面的数学模型来表示:
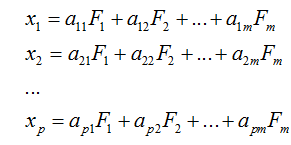
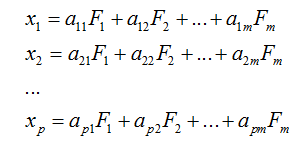
式中,x1,x2,…,xp为p个原有变量,是均值为0、标准差为1的标准化变量,F1,F2,…,Fm为m个因子变量,m小于p,表示成矩阵形式为:
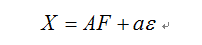
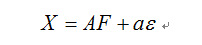
式中,F为公共因子,可以理解为高维空间中相互垂直的m个坐标轴;A为因子载荷矩阵,是第i个原有变量在第j个因子变量上的负荷。
1.3 因子分析中的几个相关概念
(1)因子载荷aij
因子载荷aij为第i个变量与第j个公共因子上的相关系数,反映了第i个变量在第j个公共因子的相对重要性。
(2)变量共同度
变量共同度,也称公共方差,反映全部公共因子对原有变量xi的总方差的解释性说明比例。原有变量xi的共同度为因子载荷矩阵A中第i行元素的平方和,即:
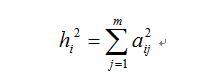
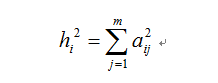
越接近1(原有变量
在标准化前提下,总方差为1),说明公共因子解释原有变量的信息越多。
(3)公共因子 的方差贡献
公共因子 的方差贡献定义为因子载荷矩阵A中第
列各元素的平方和,即:
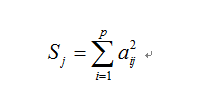
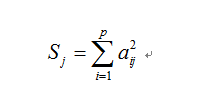
可见,公共因子 的方差贡献反映了因子
对原有变量总方差的解释能力,其值越高,说明因子的重要程度越高。
1.4 因子分析的基本步骤
因子分析的核心问题有两个:一个是如何构造因子变量;二是如何对因子变量的命名解释。因此因子分析的基本步骤和解决思路就是围绕这两个核心问题展开的。
基本步骤:
- 确定待分析的原有若干变量是否适合做因子分析。
- 构造因子变量。
- 利用旋转方法使因子变量更具有可解释性。
- 计算因子得分。
2 实例与操作
2.1 实例
(具体数据不再展示)
2.2 操作过程
(具体操作不再展示)
2.3 结果解读
(1)KMO和Bartlett的检验结果如下图所示:


KMO统计量为0.585,大于最低标准0.5,适合做因子分析。Bartlett球形检验,拒绝单位相关阵的原假设,P<0.001,适合做因子分析。
(2)主成分列表如下图所示:
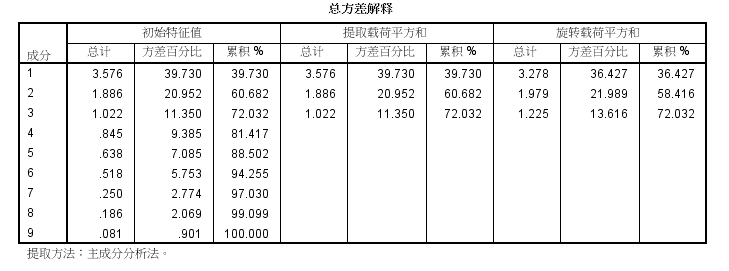
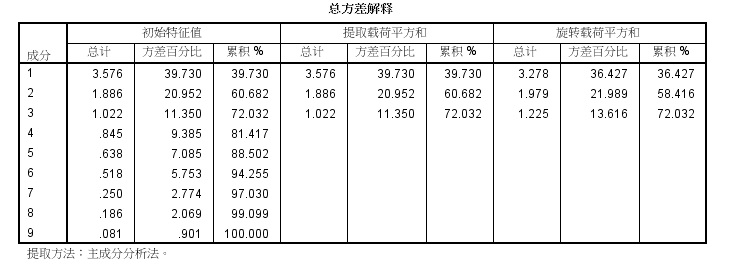
结果显示前3个主成分的特征值大于1,它们的累计贡献率达到了72%,故选取前3个公共因子。
(3)公因子方差结果如下图所示:
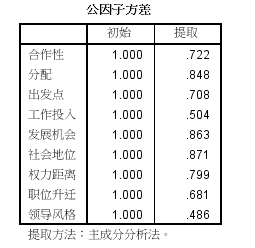
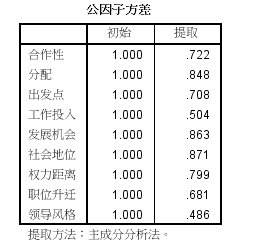
结果显示,每一个指标变量的共性方差大部分在0.5以上,且大多数接近或超过0.7,说明这3个公因子能够较好地反应原始各项指标变量的大部分信息。
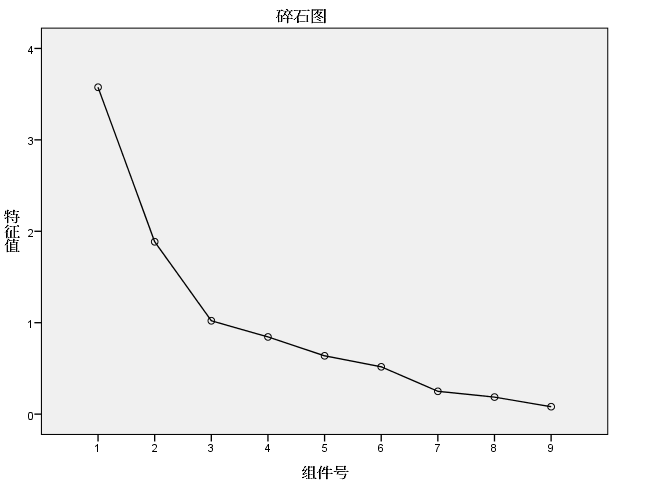
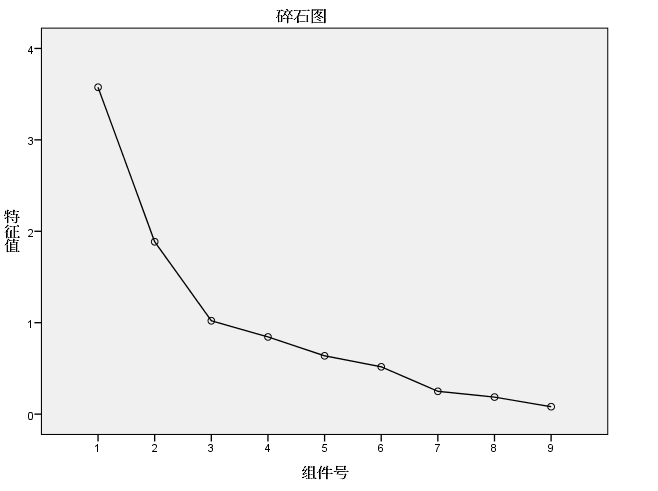
(4)碎石图如下图所示,结合特征根曲线的拐点及特征值,从图上可以看出,前3个主成分折现坡度较陡,而后面的趋于平缓,该图侧面说明了取前3个主成分为宜。
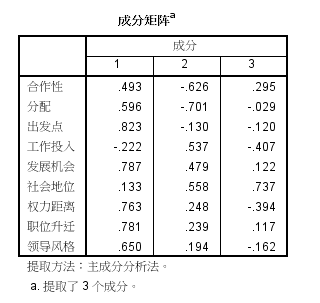
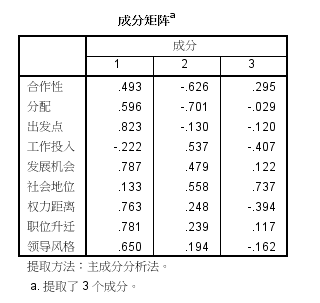
(5)旋转前的因子载荷如下图所示。根据0.5原则,各项指标在各类因子上的解释不明显,为了更好解释各项因子的意义,需要进行旋转。
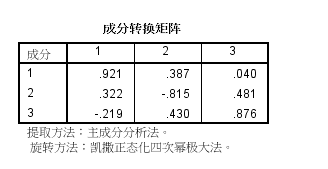
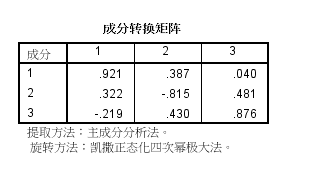
(6)正交旋转矩阵如图所示。该结果是通过4次方最大旋转得到的正交变换矩阵。
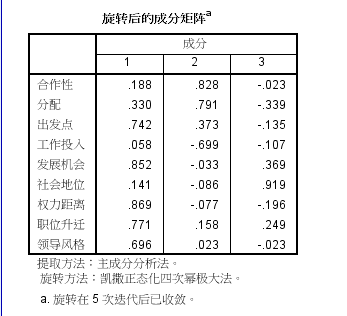
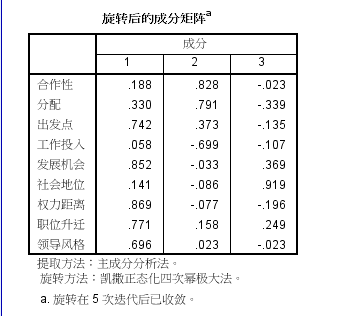
(7)旋转后的因子载荷如下图所示,经过旋转后,指标出发点、发展机会、权利距离、职位升迁、领导风格在因子1上由较大载荷。指标合作性、分配、工作投入在因子2上有较大载荷。指标社会地位在因子3上有较大载荷。故因子1可称为发展潜力因子,因子2可称为协作能力因子,因子3是单指标因子,可称为社会地位因子。
******************************************************************************************
三 主成分分析与因子分析的区别与联系丨SPSS


2 条评论
谢谢!