版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_25343557/article/details/82431408
此次完成抓取今日头条动漫图片,并将图片保存在本地。最后结果如下:
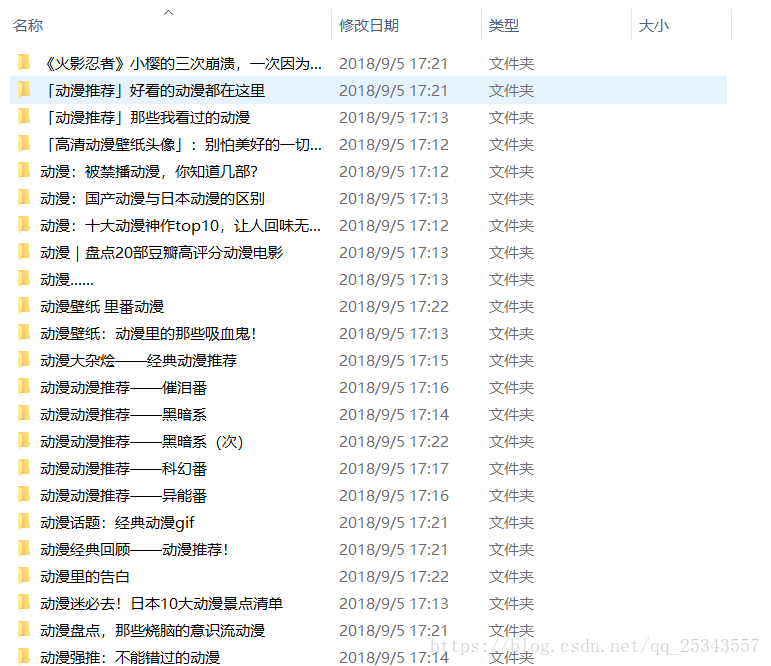
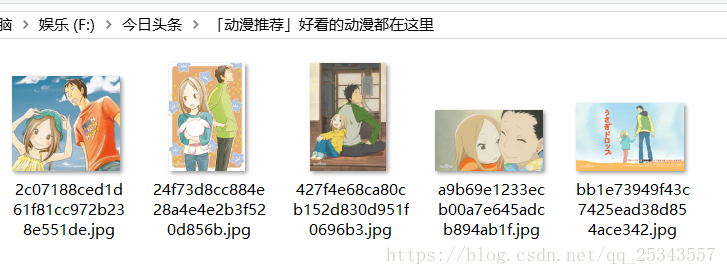
分析
打开今日头条首页搜索“动漫”,查看源代码我们会发现只包含少量的HTML,所以可以判断页面是AJAX加载的。打开开发者工具查看AJAX请求:

可以发现首次加载时的接口为:
https://www.toutiao.com/search_content/?offset=0&format=json&keyword=动漫&autoload=true&count=20&cur_tab=1&from=search_tab滚动触发AJAX请求,第二次加载时的接口为:
https://www.toutiao.com/search_content/?offset=20&format=json&keyword=动漫&autoload=true&count=20&cur_tab=1&from=search_tab可以发现规律,每次加载都是增加offset的值,步长为20。
查看加载的json数据可以获得标题信息和详情页地址。
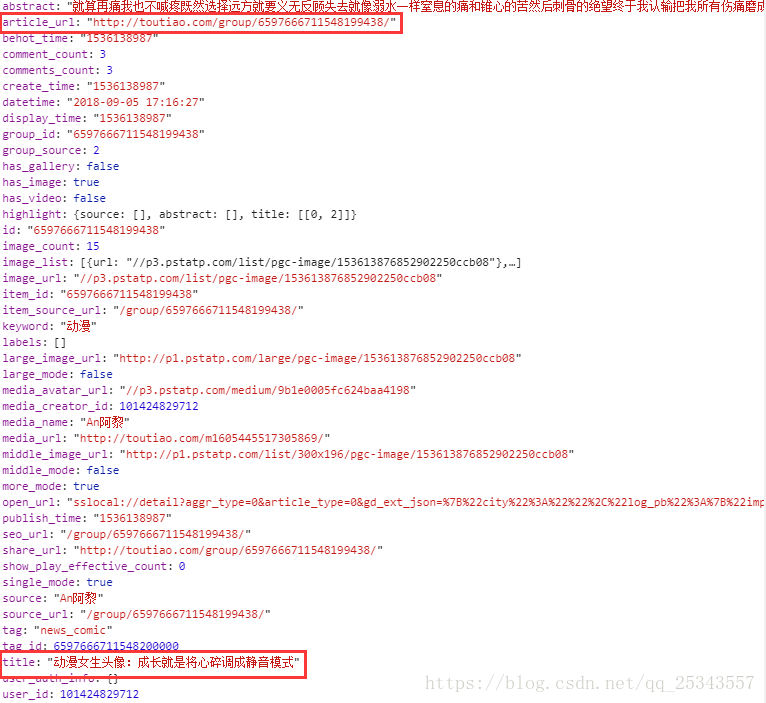
我们获得详情页链接后再次发送请求进而获得每张图片的地址。
在详情页中不是通过AJAX加载的。我们查看源代码可以发现关于页面信息的蛛丝马迹。我们直接获取源代码后再通过正则匹配即可。

代码实现
from urllib.parse import urlencode
from hashlib import md5
import requests
import re
import os
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.118 Safari/537.36'} # 伪装成浏览器
def get_summary_data(url):
'''
根据url获取json数据
:param url: 请求地址
:return: json形式数据
'''
try:
resp = requests.get(url,headers=headers)
if resp.status_code == 200:
print('获取到索引页数据')
return resp.json()
except requests.RequestException as e:
print('获取索引页数据失败')
def get_details_data(url):
'''
获取图片源地址
:param url: 文章链接
:return:
'''
try:
response = requests.get(url,headers=headers)
if response.status_code == 200:
html = response.text
return parse_details_data(html)
except requests.RequestException as e:
print('抓取失败')
def parse_data(json):
'''
解析json数据
:param json: json数据
:return: 生成器
'''
if json:
items = json.get('data')#获取所有加载的数据
for item in items:
title = item.get('title')#获取标题
if title==None:
continue
article_url = item.get('article_url')#获取文章链接
picUrl = get_details_data(article_url)
if picUrl !=None:
data = {}
data['title'] = title
data['imgs'] = picUrl
yield data
def is_link(link):
return link.startswith('http')
def parse_details_data(html):
pat = '<script>var BASE_DATA = .*?articleInfo:.*?content:(.*?)groupId.*?;</script>'
match = re.search(pat,html,re.S)
if match!=None:
img_lists = list(filter(is_link,re.compile('"(.*?)"').findall(match.group(1))))#使用该正则会匹配到其他值,所有进行过滤
return img_lists
def save_img(path,datas):
'''
将图片保存到文件夹中
'''
for data in datas:
title = data.get('title')
print('正在下载==='+title)
if not os.path.exists(path):
os.mkdir(path)
if not os.path.exists(path+title):
os.mkdir(path+title)
for url in data.get('imgs'):
if url ==None:
continue
resp = requests.get(url)
if resp.status_code == 200:
pic_path = '{0}/{1}.{2}'.format(path+title,md5(resp.content).hexdigest(),'jpg')
if not os.path.exists(pic_path):
with open(pic_path,'wb') as file:
file.write(resp.content)
else:
print('已下载!')
print('=================下载完成!=============')
def main(keyword,offset):
params = {
'offset':offset,
'format':'json',
'keyword':keyword,
'autoload':'true',
'count':20,
'cur_tab':1
}
url = 'https://www.toutiao.com/search_content/?'+urlencode(params)
data = get_summary_data(url)
data = parse_data(data)
save_img('F:/今日头条/',data)
if __name__=='__main__':
for offset in range(80,100,20):
print('=================================正在爬取,offset=%s'%offset)
main('动漫',offset)
print('=========================================================')今日头条的爬取大概是这样的了,爬美女图片也是类似的。分析分析吧!