##1.scrapy项目结合selenium抓取动态复杂js网站
#scrapy项目本身不大支持动态网站抓取,结合selenium可以解决项目中很多问题,selenium的使用主要是在middlewares中间件中使用,原理大概是spider传递过来的request不通过下载器直接下载而是通过下载中间件中selenium直接处理返回response给spider进行解析
#scrapy和selenium的结合使用需要spider中用start_request方法,并且使用meta参数,这个meta参数就是连接中间件selenium的关键,下面看代码
####spier文件
# -*- coding: utf-8 -*-
import scrapy
from dangdang.items import DangdangItem
class DdSpider(scrapy.Spider):
name = 'dd'
allowed_domains = ['dangdang.com']
# start_urls = ['http://search.dangdang.com/?key=python&act=input']
def start_requests(self):
meta={"nihao":"dawang"}
url="http://search.dangdang.com/?key=python&act=input"
yield scrapy.Request(url=url,callback=self.parse,meta=meta)
def parse(self, response):
meta = {"nihao": "dawang"}
urls=response.xpath('//ul[@class="bigimg"]/li/a/@href').extract()
for product_url in urls:
# print(url)
yield scrapy.Request(url=product_url,callback=self.new_parse,meta=meta)
def new_parse(self,response):
item=DangdangItem()
item["link"]=response.url
item["name"]=response.xpath('//*[@id="product_info"]/div[1]/h2/span[1]/text()').extract()
item['price']=response.xpath('//*[@id="dd-price"]/text()').extract()
yield item
####middlewares文件
from scrapy import signals
from selenium import webdriver
from scrapy.http import HtmlResponse
class DangdangDownloaderMiddleware(object):
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the downloader middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_request(self, request, spider):
if request.meta["nihao"] =="dawang" :
driver=webdriver.Chrome()
driver.get(request.url)
content=driver.page_source.encode("utf-8")
driver.quit()
return HtmlResponse(request.url,encoding="utf-8",body=content,request=request)
##2.scrapyd部署scrapy
1.scrapy-client安装,这主要是进行上传scrapy项目,打包上传到scrapyd服务上去
首先进入到scrapy项目根目录,命令行scrapyd-deploy服务,然后scrapyd-deploy dang -p dangdang,然后运行scrapyd服务,最后在scrapyd命令部署运行curl http://localhost:6800/schedule.json -d project=dangdang -d spider=dd
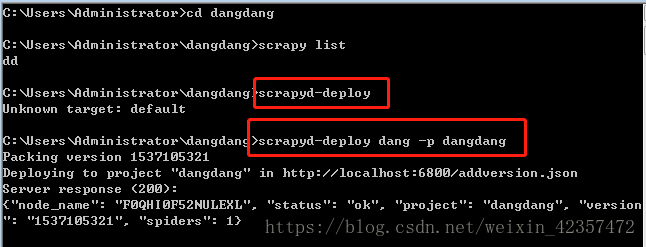
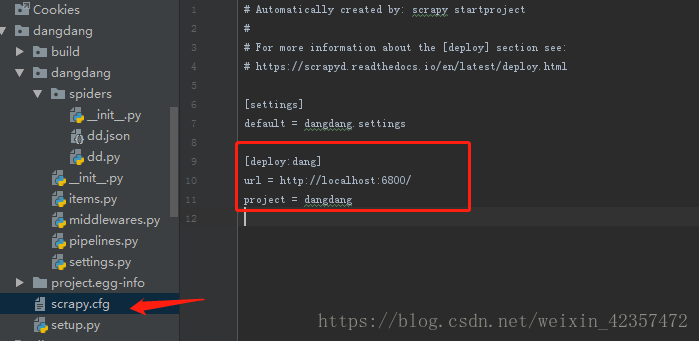
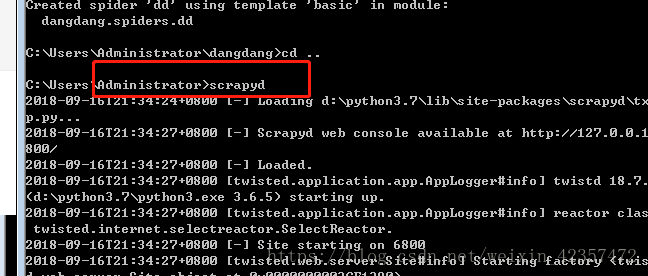

最后这是在scrapyd web可视化界面看到爬虫运行的状态