一、序列化
序列化就是把结构化对象,转换成字节流序列或者其他数据传输协议以便于永久化存储和网络传输。反序列化是序列化的逆过程,即将收到的字节流序列、数据传输协议等,转换成结构化的对象。Hadoop中用于多节点间进程通信的是RPC(远程过程调用)。RPC序列化格式如下:
1、格式紧凑,节省资源,由于带宽和存储是数据中心中的最稀缺的资源,我们必须尽一切可能缩小传递信息的大小和存储量,提高网络带宽利用率
2、快速,分布式系统的骨架要求进程间通信尽可能地减少序列化与反序列化的性能开销。
3、可扩展,当前hadoop的序列化有多种选择可以满足新老客户单格式上的不同。
4、支持互操作,来满足不同语言所写的服务器与客户端之间的信息交互。
1、writrable接口
Hadoop使用的是自己的序列化格式Writable,它有节约资源、可重用对象、可扩展等特点。在集群中信息的传递主要就是靠这些序列化的字节序列来传递。
Hadoop中,Writable接口定义了两个方法:
void write(DataOutput out) throws IOException;用户将其状态写入二进制格式的DataOutput流。
void readFields(DataInput in) throws IOException;用于从二进制格式的DataInput流读取其状态。
2、writrable类
图3.1为Hadoop自带的I/O包中的Writable类的层次结构。
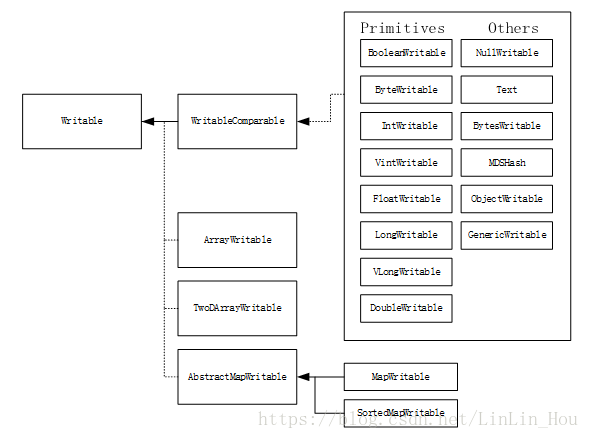
图3.1Writable类的层次结构
Java基本数据类型的Writable类如下面列表所示:
Java 基本数据类型 |
Writable实现 |
序列化大小(字节) |
boolean |
BooleanWritable |
1 |
byte |
ByteWritable |
1 |
int |
IntWritable VIntWritable |
4 1~5 |
float |
FloatWritable |
4 |
long |
LongWritable VLongWritable |
8 1~9 |
double |
DoubleWritable |
8 |
String |
Text |
* |
Array |
ArrayWritable |
* |
二、SequenceFile顺序文件
HDFS和MapReduce是专为大文件设计,为了在处理海量小文件时也能体现Hadoop的优势,我们可以使用SequenceFile作为小文件的容器,即将小文件包装成SequenceFile类型的文件,来提高存储和处理的效率。
1、SequenceFile格式
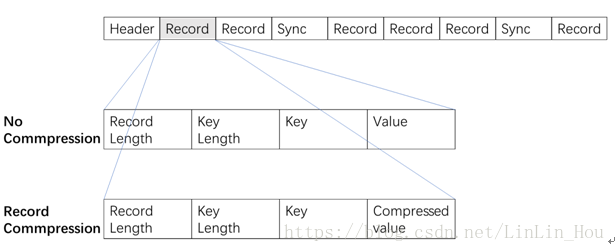
图3.2SequenceFile结构
在存储结构上,SequenceFile主要由一个Header、多条Record以及位界定标识符组成。记录与记录之间穿插位界定标识符,可实现从文件任意位置读取数据。Header主要包括键类型、值类型、压缩算法以及用户自定义元数据等。而每条record以键/值对方式进行存储,包括记录长度、键长度、键、值。SequenceFile有三种模式,分别为:1、无压缩模式;2、记录压缩模式;3、块压缩模式。记录压缩模式与无压缩模式差别不大,主要去区别在于value将被压缩,而key不做任何处理,图解如图3.2所示。而块压缩则是将一系列记录合并到一起,统一压缩成一个数据块,如下图所示。数据压缩有利于数据存储与网络传输,但是不利于直接读取。具体如图3.3所示。
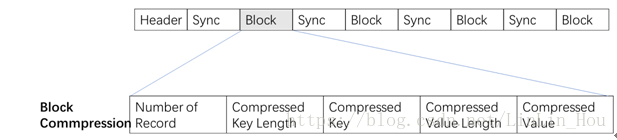
图3.3SequenceFile块压缩格式
2、SequenceFile的读写操作
SequenceFile是Hadoop平台下的一种二进制文件,用来将key/value序列化为二进制文件,通常用于小文件合并的容器。Sequence.writer和SequenceFile.reader是它的两个主要内部类。
对于SequenceFile的写操作,可通过createWriter()方法创建SequenceFile对象。该方法有多个重载版本,其中,fs、conf、keyClass、valueClass为必选参数,fs指配置文件系统,conf指相应配置,keyClass为键类型,value为值类型。可选参数包括compressionType、codec、metadata,compressionType指压缩类型,codec指压缩代码,metadata指文件元数据。SequenceFile的kay、value并不一定是Writable类型,也可以是其他类型,只要能被序列化与反序列化。Progressable()用来向控制台显示目前进度,append()用来向文件末尾添加键值对,close()用来关闭数据流。
对于SequenceFile的读操作,可以通过reader()实例化用调用next()反复读取。若序列化框架为Writable类型,next()方法可以读取下一条键值对,若成功,则返回true,失败则返回false。若序列化框架为其他类型,可以采用以下两种方法:
public Object next( Object key ) throwsIOException
public Object getCurrentValue(Obiect val) throws IOException
若返回值非null,则可以继续读取数据。否则,表示文件已读取到末尾。
三、FileInputFormat类
FileInputFormat继承InputFormat,主要用于:一、指定任务的输入文件路径;二、实现输入文件生成分片。把Split分割成record的任务由其子类实现。下图所示为InputFormat类的层次结构。
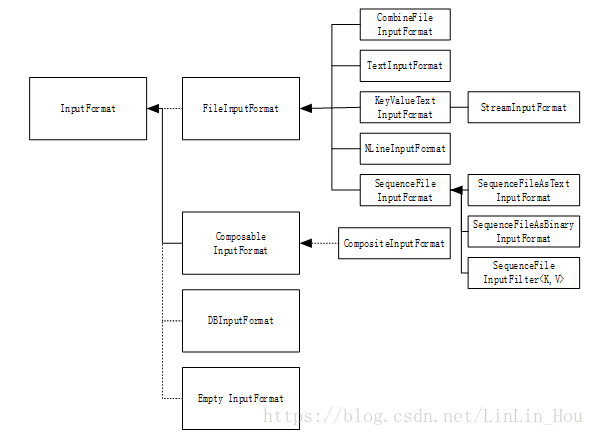
图3.4InputFormat类的层次结构
四、OutputFormat
1、OutputFormat方法
OutputFormat主要用来描述MapReduce作业的输出规范,如检查输出目录是否已经存在,也可通过RecordWriter来写出作业的输出文件,该输出文件存储在FileSystem中。
OutputFormat主要有三个类,分别为:
public RecordWriter<K,V>getRecordWriter(TaskAttemptContext context)
public void checkOutputSpecs(JobContext context)
public OutputCommittergetOutputCommitter(TaskAttemptContext context)
getRecordWriter()用于获取给定的RecordWriter,而RecordWriter用于将输出键值对写入输出文件,再将作业输出写入文件系统。
checkOutputSpecs()用于检查作业输出规范是否有效,通常再作业提交时验证,若输出路径已经存在将报错。由于Hadoop平台处理的都是大规模数据,若将输出路径覆盖,则原先已处理的结果将丢失,这个损失不可估量。所以提交作业时,输出路径必须是不存在的。
getOutputCommitter()用于获取输出格式的输出提交者,来负责确保输出提交正确。关于OutputCommitter类详见下一节的解释。
其中,JobConf是一个重要的参数,主要用来向Hadoop框架描述MapReduce作业执行的主要界面。Hadoop将按JobConference来执行工作,但是一些已标记为final的配置参数将无法更改。
JobConf通常指定要使用的Mapper,组合器(如果有),Partitioner,Reducer,InputFormat和OutputFormat实现等。JobConf也可用于指定作业的其他高级构面,如要使用的比较器,要放入DistributedCache的文件,是否要压缩中间和/或作业输出(以及如何),通过用户提供的可调试性脚本(setMapDebugScript(String)/ setReduceDebugScript(String)),用于在stdout,stderr,syslog上进行后期处理。等等。
2、OutputCommitter
Hadoop使用一个提交协议来确认任务成功完成或完成失败。这个确认机制通过对任务使用OutputCommitter来实现,通过OutputFormat的getOutputCommitter()来设置。
OutputCommitter有如下几个常用API:
public abstract voidsetupJob(JobContext jobContext) throwsIOException
public voidcleanupJob(JobContext jobContext)throws IOException
public voidcommitJob(JobContext jobContext) throwsIOException
public voidabortJob(JobContext jobContext, int status)throws IOException
MapReduce依赖于OutputCommitter工作:
1、在初始化过程中,通过setupJob()设置作业来执行初始化操作。例如,在作业初始化期间创建作业的临时输出目录,并且为task输出创建一个临时工作空间。
2、工作成功处理后,调用commitJob()方法完成清理工作。系统默认中,它在作业完成后删除临时输出目录以告知作业成功完成,同时删除临时空间。
3、设置任务临时输出。
4、在作业提交时调用,用于检查任务是否需要提交。
5、将任务的临时输出提升至最终输出位置。如果needsTaskCommit(TaskAttemptContext)返回true,则将任务输出标记为完成。
6、从任务的进程调用,来清理尚未提交的单个任务的输出,对于同一个任务可能会被多次调用。
这几个方法可以从多个不同的进程和几个不同的上下文中调用。每一种方法都应在其文件中作相应的标记,但并不是所有的方法都保证只调用一次和一次。如果一个方法不能保证有这个属性,那么输出提交者需要适当地处理这个问题。只在极少数情况下,它们可能会被多次调用同一个任务。
3、多文件自定义输出
在hadoop中,reduce支持多个文件输出,其文件名通过MultipleOutputFormat类,重写generateFileNameForKey方法实现控制。如果只是想做到输出结果的文件名可控,实现自定义输出类型,通过设置OutputFormat,使用LogNameMultipleTextOutputFormat.class就可以了,但是这种方式只限于使用旧版本的hadoop api。本论文中,我们希望处理图像文件,以文件名为key,输出结果也是图片,需要重写MultipleOutputFormat。
首先构造多文件输出类MyMultipleOutputFormat类,然后自定义应该LineRecordWriter类,实现记录写入器LineRecordWriter类,自定义输出格式。