1.什么是Avro
- Avro设计用于支持大批量数据交换的应用
- Avro可以将数据结构或者对象转换成便于存储或者传输的格式。
- 为了hadoop的前途考虑,DougCutting主导开发的一套新的序列化系统,与09年加入hadoop项目家族中。
2.为什么要有Avro
我们通讯过程中,需要序列化,但是网上有那么多成熟的序列化框架,为啥还要这个序列化工具呢?这个主要是为了hadoop的发展考虑,因为其他的序列化工具多多少少有一些不合理的地方,比如protobuff需要定义数据结构,但是当数据源多的时候,或者传输的数据格式缺少的时候就会出问题,还比如java的序列化只能java使用,还有其他的会有版本要求

Avro是一种RPC通讯框架,依赖于json格式。(json好处:可以换成字符串,便于其他的处理)
Avro的模式是什么?
模式理解为java中的类,
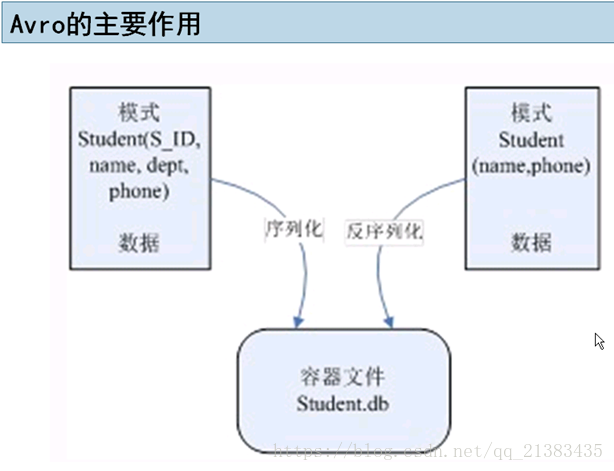
字段读取的时候,即使不匹配也能读取,相当于数据库了,只不过把模式(字段)存在Student.db文件头部。
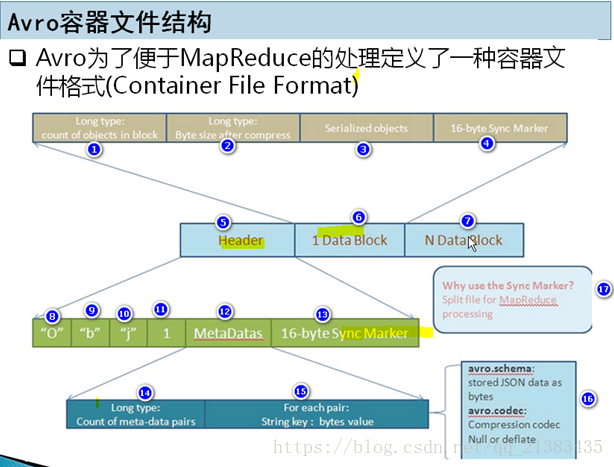
为了方便hdfs的处理,这里Avro就定义了这么一种数据格式。
5 6 7 可以看到一个文件头,多个块数据,每个块与块之间都有一个同步标记(13)
13 主要是map-reduce分割文件的时候,便于分割。
8 9 10 11 是存储标记信息
12 元数据的信息(包括 模式(14)格式是key-type格式,字段名称-字段类别)
15 是该字段压缩的信息
1 块中对象的数量
2 压缩后的大小
3 序列化后的对象,占用最多内存
4 同步标记
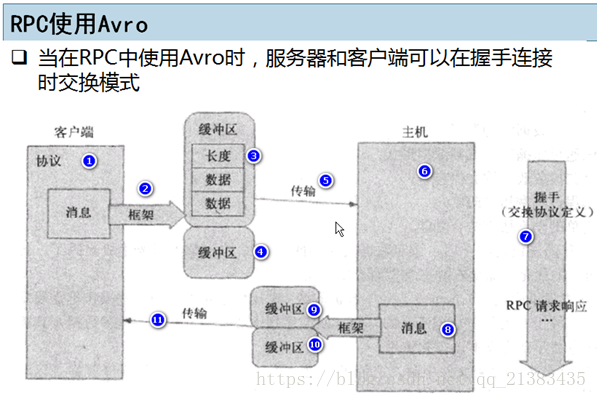
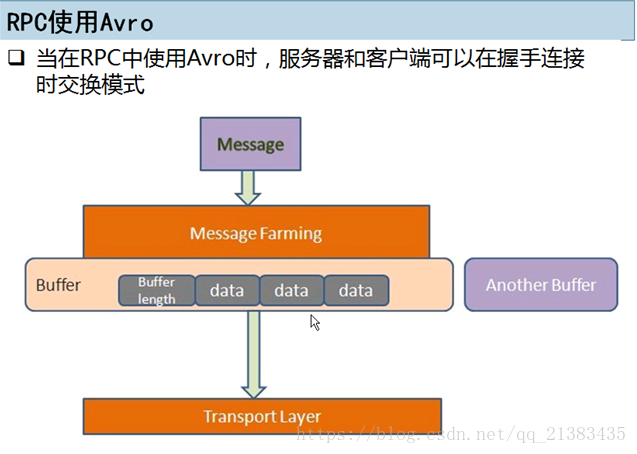
紫色是一个空的buffer,这样设计的好处是可以每个Buffer一个数据源的数据。
TransportLayer传输层使用的是Http协议。POST方式。
