文章目录
一、DELETED
1-1 业务背景、业务场景、业务模式
背景: 为了更好的做到个性化服务、用户体验提升、智能分析、风险控制,在大数据离线(批)处理之外,搭建实时(流式)处理平台迫在眉睫。比如说对实时性要求较高。。。。。。
[批流统一,业界暂时还没有成熟方案以及技术。]
场景:
模式:
1-2 数据峰值、需求
暂略
二、难点
2-1 数据孤岛
。。。。。。各部门的数据保存在不同的业务库当中,跨部门数据共享非常困难的问题。
2-2 不同数据的定制化数据抽取方案
解决各业务抽取自己所需要的数据,抽取时间不同,互相拿到的数据版本不一致的问题。
2-3 数据完整性、安全性
如何保证数据总线获取各业务数据不丢失、不重复,并且安全。
2-4 单点故障
物理环境、系统、实时处理平台、网络、应用等任何一个环节的不稳定,最终都可能对整体可用性造成影响。

2-5 其他
三、架构(粗略)
3-1 架构图总览
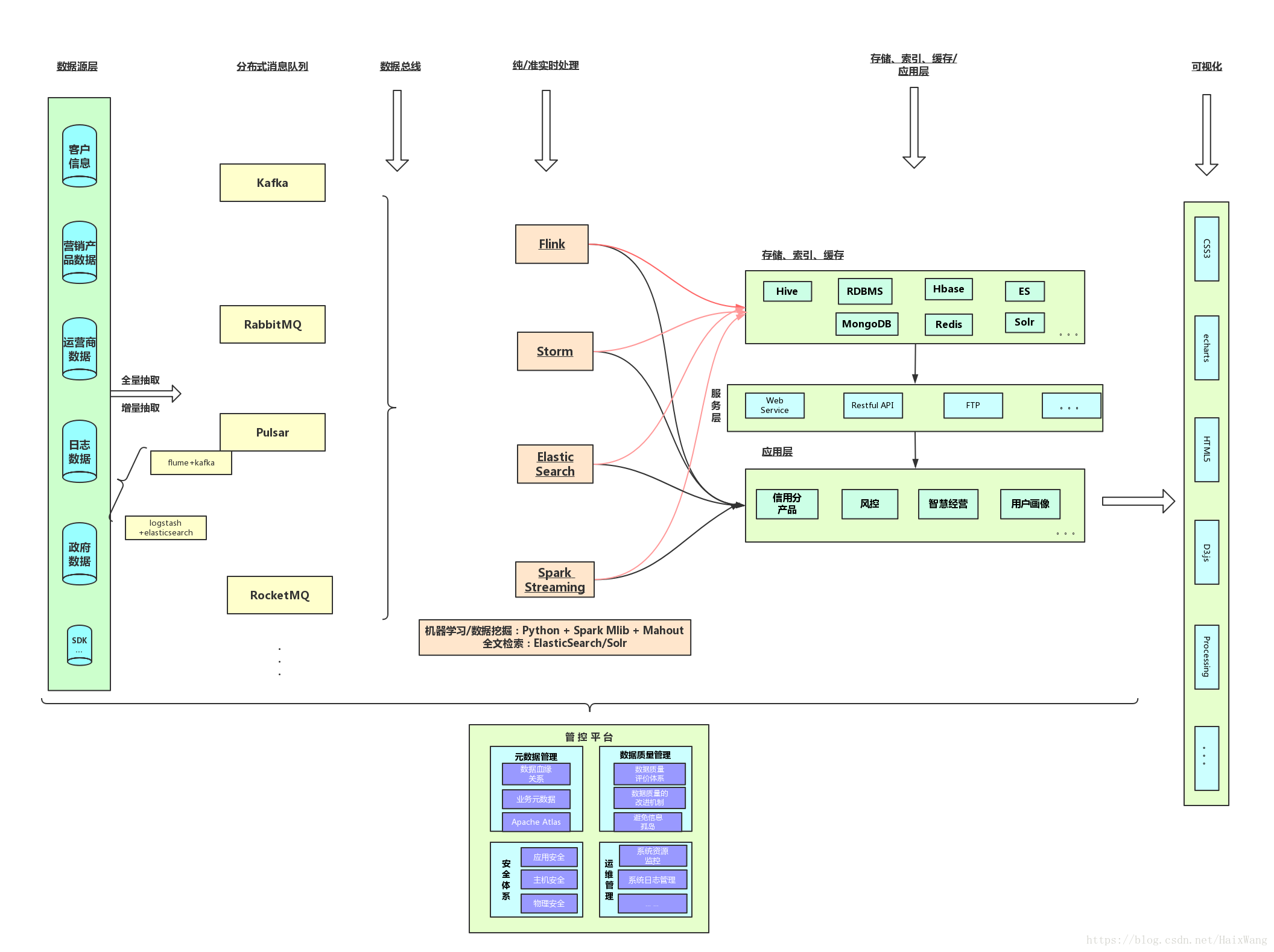
3-2 数据采集
数据采集作为大数据系统体系的第一环节尤为重要。有效的正确的收集数据才能最大限度的避免信息孤岛,让数据产出更多的价值。
相关图片已删除
我行的数据极其的多样化,首先得建立一套标准的数据采集方案,面向各个业务场景的埋点规范;建立一套高性能、高可靠性的传输系统,将数据从生产业务端传输到大数据系统;数据可以增量同步也可全量同步。
3-2-1 分布式消息队列
消息队列的两种模式:
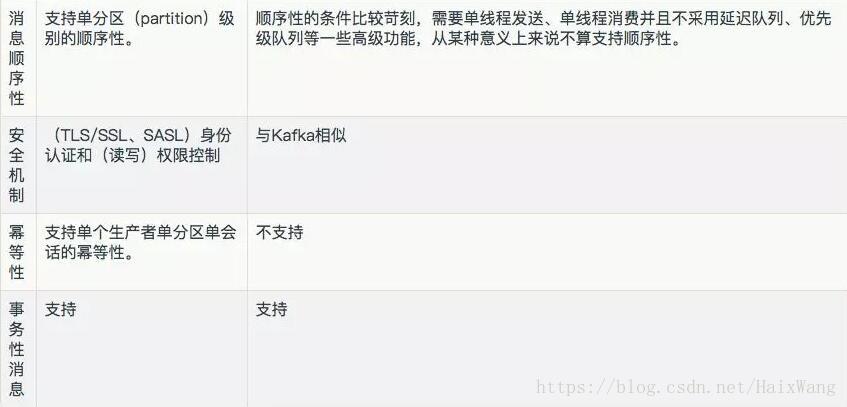
| \ | 点对点-Queue | 发布/订阅:Topic |
|---|---|---|
| 概念 | 消息生产者生产消息发送到queue中,然后消息消费者从queue中取出并且消费消息 | 消息生产者(发布)将消息发布到topic中,同时有多个消息消费者(订阅)消费该消息 |
| 最主要区别 | 消息被消费以后,queue中不再有存储,所以消息消费者不可能消费到已经被消费的消息。 | 和点对点方式不同,发布到topic的消息会可以被多个订阅者消费。(可持久化——解耦消息的发送者和消费者;kafka中,可以通过参数配置保留期限) |
Kafka
稳定版本:2.0.0 2018年7月28
1.简介
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统(还有一种消息中间件是点对点),它可以处理消费者规模的网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Hadoop的一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消息。
2.使用的公司
[见参考3]
- 应用场景:
-
考虑数据丢失。比如我们从某个数据源接受数据,但是数据从数据源流出的速度大于我们接受数据组件的处理速度,那么这种情况,就很有可能出现数据丢失;还有就是网络阻塞,机器宕机,也可能会造成数据丢失。而kafka处理数据的策略可以很好的解决这个问题
-
多订阅数据分发,kafka的消费者组,kafka的某个主题,可以让多个组件去订阅。比如我们某个系统出来的数据,可能多个子系统都会使用这些数据,那么使用kafka是个很不错的选择【比如对于同一份数据,我们需要有不同的动作,比如对该数据进行数据清洗挖掘信息,或者将该数据发往别的界面进行展示,等等。】(Kafka支持多个消费者从一个消息流上读取数据,而且消费者之间直不影响)
-
实时处理:收集处理流式数据(我们可以把数据库的更新发布到 Kafka 上,应用程序通过监控事件流来接收数据库的实时更新。)
-
日志收集: kafka可将多个日志服务器的数据聚合到一起,比如说文件服务器,hdfs。之后再对这些日志数据进行离线分析,或者放入全文检索系统中进行数据挖掘
-
应用程序指标,跟踪 CPU 使用率和应用性能等指标
-
行为跟踪:跟踪用户浏览页面、搜索及其他行为,以发布-订阅的模式实时记录到对应的topic里。那么这些结果被订阅者拿到后,就可以做进一步的实时处理,或实时监控,或放到hadoop/离线数据仓库里处理。(在领英,Kafka 最初的使用场景是跟踪用户的活动。这样一来就可以生成报告,为机器学习系统提供数据,更新搜索结果等)
RabbitMQ
稳定版本:3.7.7 2018年6月20日
1.简介
RabbitMQ是使用Erlang语言开发的开源消息队列系统,基于AMQP协议(Advanced Message Queue,高级消息队列协议)来实现。AMQP的主要特征是面向消息、队列、路由(包括点对点和发布/订阅)、可靠性、安全。AMQP协议更多用在企业系统内,对数据一致性、稳定性和可靠性要求很高的场景,对性能和吞吐量的要求还在其次。
RabbitMQ 最初起源于金融系统。
2.使用RabbitMQ的公司
[见参考4]

RocketMQ
【RocketMQ社区活跃度,我感觉远不如前两位】
稳定版本:4.3.1 2018年8月29日
1.简介
RocketMQ是阿里开源的消息中间件,它是纯Java开发,具有高吞吐量、高可用性、适合大规模分布式系统应用的特点。RocketMQ思路起源于Kafka,但并不是Kafka的一个Copy,它对消息的可靠传输及事务性做了优化,目前在阿里集团被广泛应用于交易、充值、流计算、消息推送、日志流式处理、binglog分发等场景。
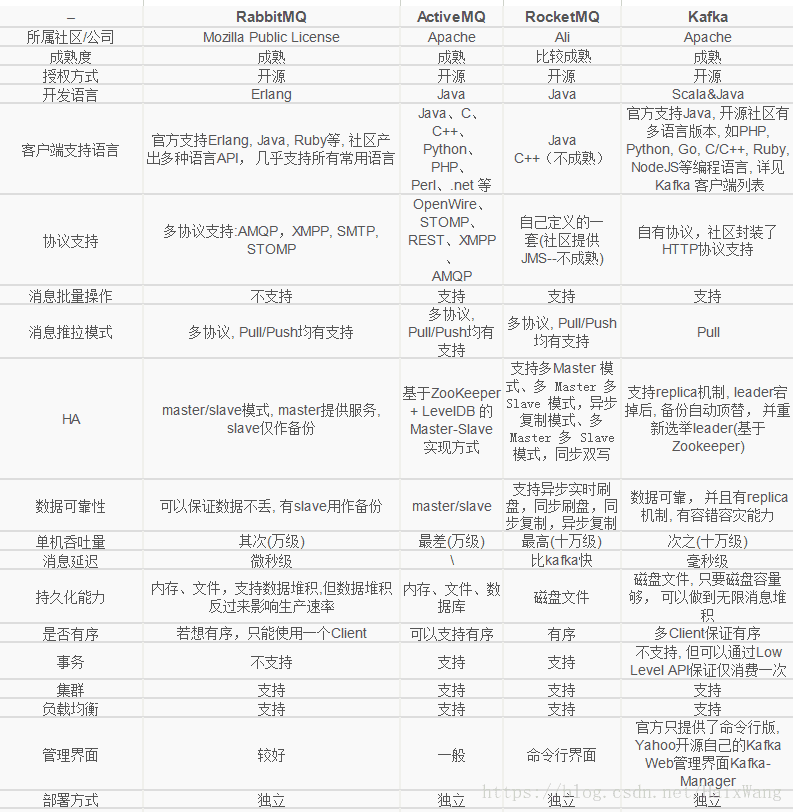
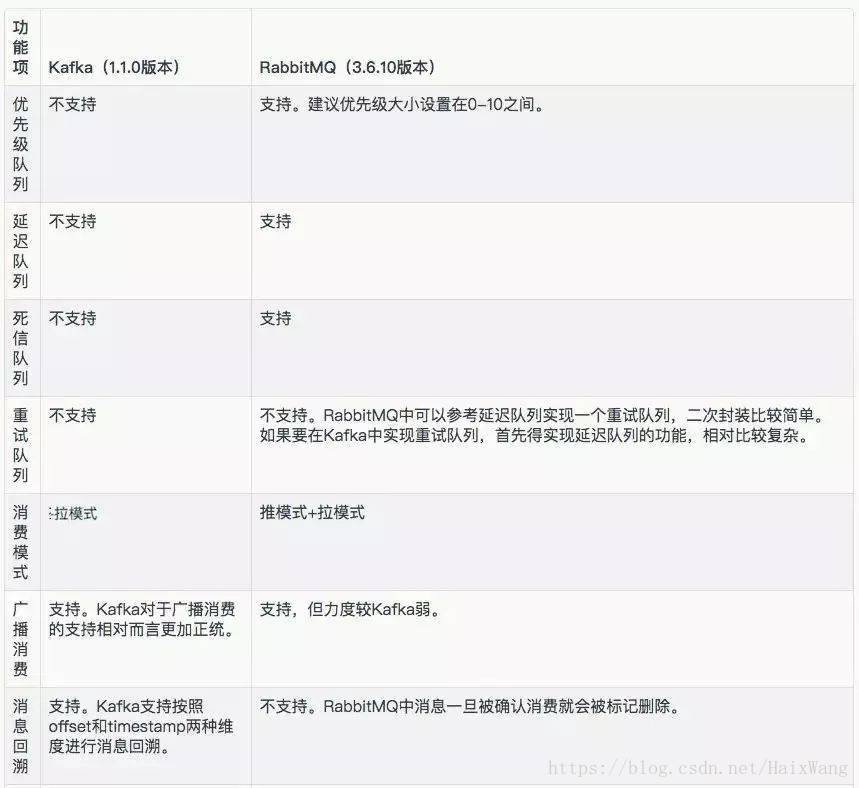
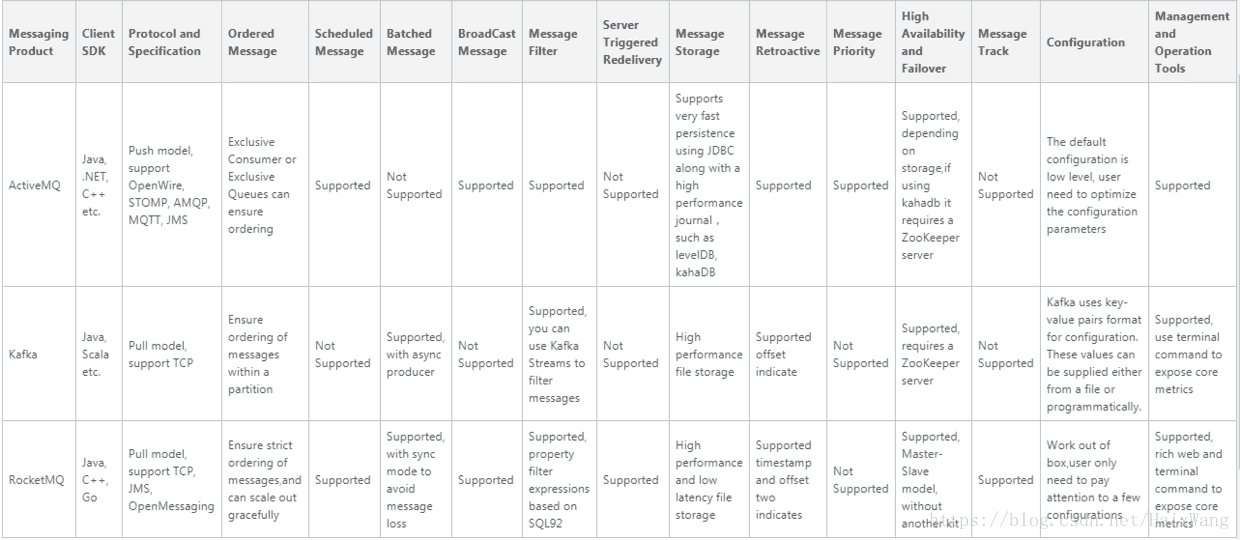
几种消息中间件的比较
[参考1]

3-2-2 日志收集
flume + kafka
1.flume简介
稳定版本:1.8.0 2017年8月4日
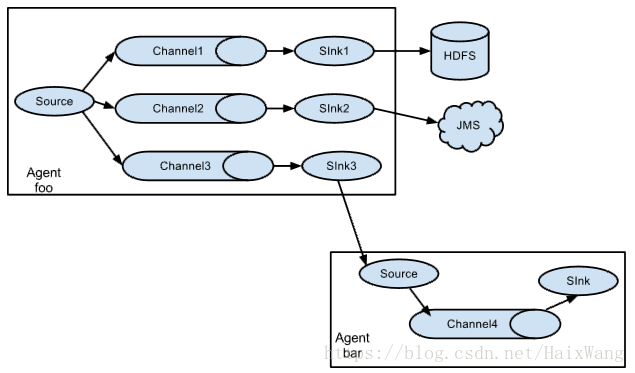
flume是一个高效的实时的分布式文件收集框架,也是apache的一个顶级项目,最初由Cloudera开发,生产中主要用来收集存入文件中的日志数据,数据源源不断的来,源源不断的处理。与kafka、Spark streaming、Storm联系比较紧密。三大组件,Source、Chanael、Sink。它的分布式不是传统的主从架构,而是说,它的分布式概念是说,它可以收集多台机器上的日志数据,每一台机器上,都可以部署一个flume客户端进行数据收集。收集数据后聚集数据、移动数据。Flume也是java编写的。服务器的数据,经过每一个Flume-agent收集数据到Source(从源端拿数据),封装到Event中,Event是Flume数据传输的基本单元。然后将数据放到Chanael(管道队列)的,然后数据放入Slink中,Sink再将数据写入到HDFS中。Sink+Channel起到一个缓冲的作用,避免数据在传输的过程中丢失(传输端大于接收端速率)。一个channel可以连接多个Sources,但是只可以连接一个Sink。
Event是Header+byte array组成。Header携带一些参数信息,比如怎样收集数据,比如在Header中传递时间,以时间为单位处理数据,Header中的信息是key-value对的形式存在。Header可以在上下文路由中使用扩展。Flume也可以进行一些数据过滤。
Source的数据是主动Push到Channel中的,而Channel数据到Sink,是Sink向Channel拉去数据。就像kafka,生产者的数据 push到topic,消费者再去pull。
2.常见Channel、Sink
- Channel
| 类型 | 说明 |
|---|---|
| Memory Channel | Event数据存储在内存中。 |
| JDBC Channel | Event数据存储在持久化存储中,当前Flume Channel内置支持Derby。 |
| Kafka Channel | Event数据存储在Kafka Topic中。 |
| File Channel | Event数据存储在磁盘文件中。 |
| Spillable Memory Channel | Event数据存储在内存中和磁盘上,当内存队列满了,会持久化到磁盘文件(当前试验性的,不建议生产环境使用)。 |
| Pseudo Transaction Channel | 单元测试用。 |
| Custom Channel | 自定义Channel实现。 |
- Sink

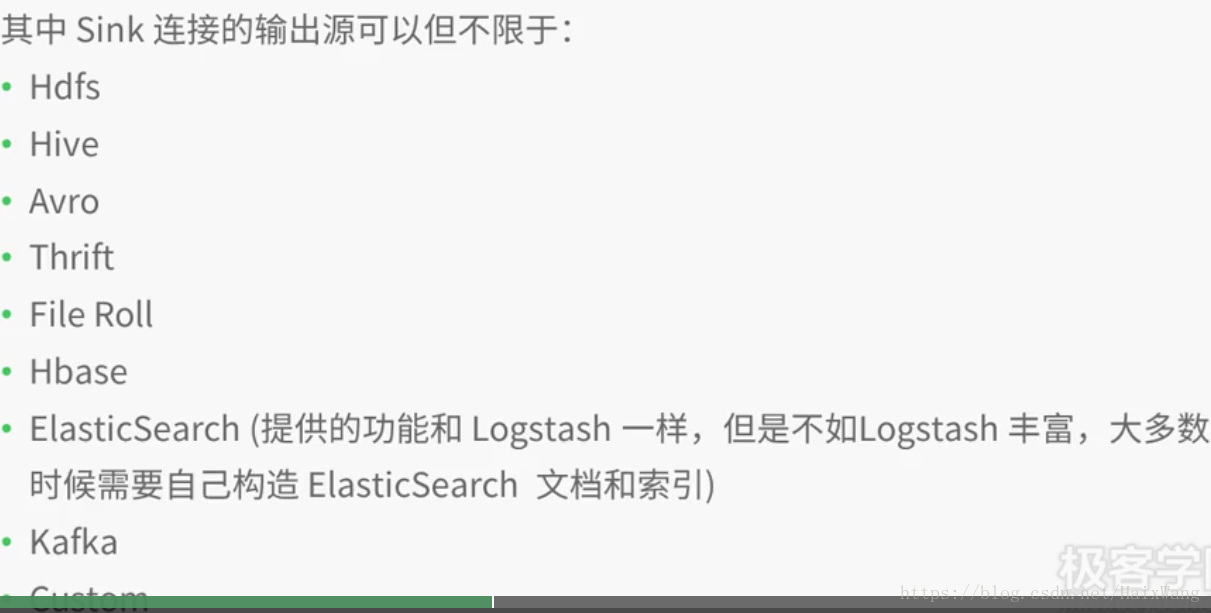
3.输入源、输出源
-
输入源
-
输出源

logstash + elasticsearch
截至今日,elastic凭借其丰富的工具、组件以及与hadoop系技术的很好的“融合”,使得ELK Stack在大数据处理生态技术中已经有不小地位。

1.logstash简介
Logstash 是一个接收,处理,转发日志的工具。支持系统日志,webserver 日志,错误日志,应用日志,总之包括所有可以抛出来的日志类型。
在一个典型的使用场景下(ELK):用 Elasticsearch【不仅es,还支持很多存储方式】 作为后台数据的存储,kibana用来前端的报表展示。
Logstash 在其过程中担任搬运工的角色,它为数据存储,报表查询和日志解析创建了一个功能强大的管道链。
Logstash 支持各种输入选择 ,可以在同一时间从众多常用来源捕捉事件。能够以连续的流式传输方式,轻松地从您的日志、指标、Web 应用、数据存储以及各种 AWS 服务采集数据。
Logstash 提供了多种多样的 input,filters,codecs 和 output 组件,让使用者轻松实现强大的功能。
2.支持的输入(几种常见的)
| input 1 | input 2 | input 3 | input … |
|---|---|---|---|
| elasticsearch | exec | http | jdbc |
| jms | kafka | rabbitmq | redis |
| stdin | tcp | udp | websocket |
3.支持的输出(几种常见的)
| output 1 | output 2 | output 3 | output … |
|---|---|---|---|
| csv | elasticsearch | exec | http |
| kafka | mongodb | rabbitmq | redis |
| zabbix | tcp | udp | websocket |
3-3 现代化数据仓库
Cloudera Data Warehouse
Cloudera数据仓库
一个现代数据仓库,提供专为自助服务分析而设计的企业级混合云解决方案。
传统的数据仓库不足以满足不断增长的业务所面临的规模和分析需求。Cloudera数据仓库功能强大,可扩展且价格合理,能够通过大型企业所需的安全性,治理和可用性,在数千个用户之间共享数PB的数据。
cases:
- Credit card transactions are handled safely. True – millions of credit card transactions are processed within minutes for consistency, fraud and compliance, using petabytes of historical transactions as reference data
- Banks know more about their customers today. It is a reality – leading banks perform hundreds of analytical experiments every day on their massive data sets to find the next bit of information about their customers
- Thousands of cyber threats against businesses are thwarted every day. It goes unnoticed but cyber threats are routinely hunted down by correlating hundreds of attributes from disparate data sources – even as data types and formats evolve
- Leading insurers are underwriting policies with lower risks. Data teams in these insurance firms are leading the charge in rebuilding entire business models around data and analytics
评价:
Nevertheless, we do recognize the maturity in features developed around Traditional Data Warehouses that are still very relevant, such as, data modeling, governance, security, and workload System Level Agreements. Our solution offers a new generation of tools to tackle them more effectively. To enable our customers, we have also forged strong partnerships with the industry-leading Independent Software and Hardware Vendors, Cloud Platform Providers, and System Integrators and have added emerging Independent Software Vendors to our ecosystem.
A new era of data warehousing is upon us – that of modern data warehousing. Cloudera is at the forefront with thousands of production deployments across the globe, actively supporting mission-critical workloads. We are just about getting started, but we are already being noticed – recently Gartner customers recognized our solution as one of the best Data Warehouse solutions of 2018.
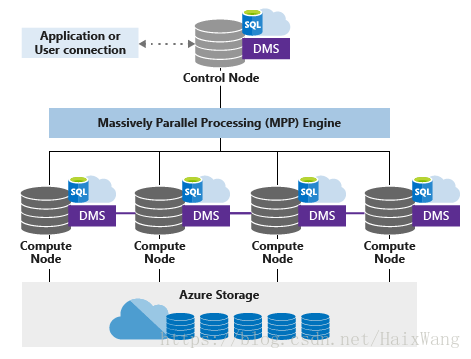
Azure SQL数据仓库

SQL Data Warehouse是一个基于云的企业数据仓库(EDW),它利用大规模并行处理(MPP)可在数PB的数据上快速执行复杂查询。
SQL Data Warehouse将数据存储到具有列存储的关系表中,使用简单的PolyBase T-SQL查询将大数据导入SQL数据仓库,然后使用MPP的强大功能运行高性能分析。
- Amazon Redshift
Amazon Redshift 是一个快速、可扩展的数据仓库,可以简单、经济高效地分析数据仓库和数据湖中的所有数据。Redshift 通过在高性能磁盘上使用机器学习、大规模并行查询执行和列式存储可提供比其他数据仓库快十倍的性能。您可以在几分钟内设置和部署新的数据仓库,并在 Redshift 数据仓库中对 PB 级数据,以及对在 Amazon S3 上构建的数据湖中的 EB 级数据运行查询。您可以从每小时 0.25 USD 的小规模开始,扩展到每年每 TB 250 USD,不到其他解决方案成本的十分之一。
3-4 纯/准实时处理
追求实时的环境下,Spark Streaming与Storm和Flink是不能相比的,由于其底层的架构(基于批处理做流处理)依然是batch,batch的数据是有边界的,不是真正意义的流式处理。
加入准实时处理,只是为了加入Spark Streaming的探讨罢了,与elatic一样,Spark有着丰富的生态:Spark Core、Spark mlib、Spark SQL、Spark graphX。数据在这里,通常可以pipline走完流程。
但是后面所说的第三代流式架构Flink的发展目标,往大了说:批流同意,对标Spark(主要指机器学习)。[见参考7]
实时计算的一致性语义
-
(最多交付一次)at-most-once:即fire and forget,我们通常写一个java的应用,不去考虑源头的offset管理,也不去考虑下游的幂等性的话,就是简单的at-most-once,数据来了,不管中间状态怎样,写数据的状态怎样,也没有ack机制。
这种交付结构最为简单,往往都是在那种数据安全性要求并不高,并且不要求所有数据都需要被处理的情况。 -
(至少交付一次)at-least-once: 重发机制,重发数据保证每条数据至少处理一次,从处理全量数据的角度来看最为可靠。 at-most-once与exactly-once的平衡点。
-
(恰好交付一次)exactly-once: 使用粗Checkpoint粒度控制来实现exactly-once,我们讲的exactly-once大多数指计算引擎内的exactly-once,即每一步的operator内部的状态是否可以重放;上一次的job如果挂了,能否从上一次的状态顺利恢复,没有涉及到输出到sink的幂等性概念。对于金融等高风险行业来说,这一种交付方式尤为重要。
-
at-least-one + idempotent = exactly-one:如果我们能保证说下游有幂等性的操作,比如基于mysql实现 update on duplicate key;或者你用es, cassandra之类的话,可以通过主键key去实现upset的语义, 保证at-least-once的同时,再加上幂等性就是exactly-once。
Flink
最新版本:1.5.3 2018年8月21日
这几年Flink发展势头迅猛,在国内先是阿里巴巴在17年逐渐将实时处理转移至Flink,然后大量修改并回馈源码,阿里巴巴内部将Flink改为Blink。

蒋晓伟认为Flink新的发展方向有两个,第一个是在传统数据处理领域:包括批流统一、机器学习、以及如何把AI workload融合进来;第二个是Flink和微服务的技术融合创新,从而为在线服务领域带来新的变革。这使得Flink在生态上,也会拥有大的想象空间。 [引至参考7]
在2017年,我们在实时计算架构上进行了全面的升级,从Storm迁移到Blink,并且在新技术架构上进行了非常多的优化,实时峰值处理能力提高了2倍以上,平稳的处理能力更是提高5倍以。 [引至参考8]
然后是饿了么,饿了么早期都是使用Storm,16年之前还是Storm,17年才开始用Sparkstreaming,现在转向Flink[见参考9]
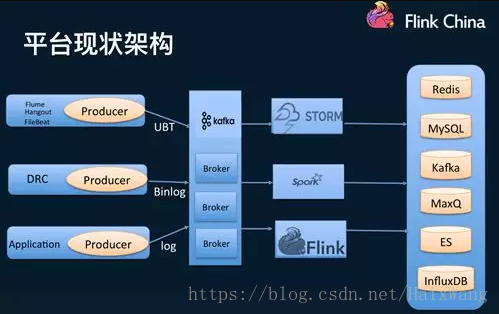
美团也在大量使用Flink。
1.简介
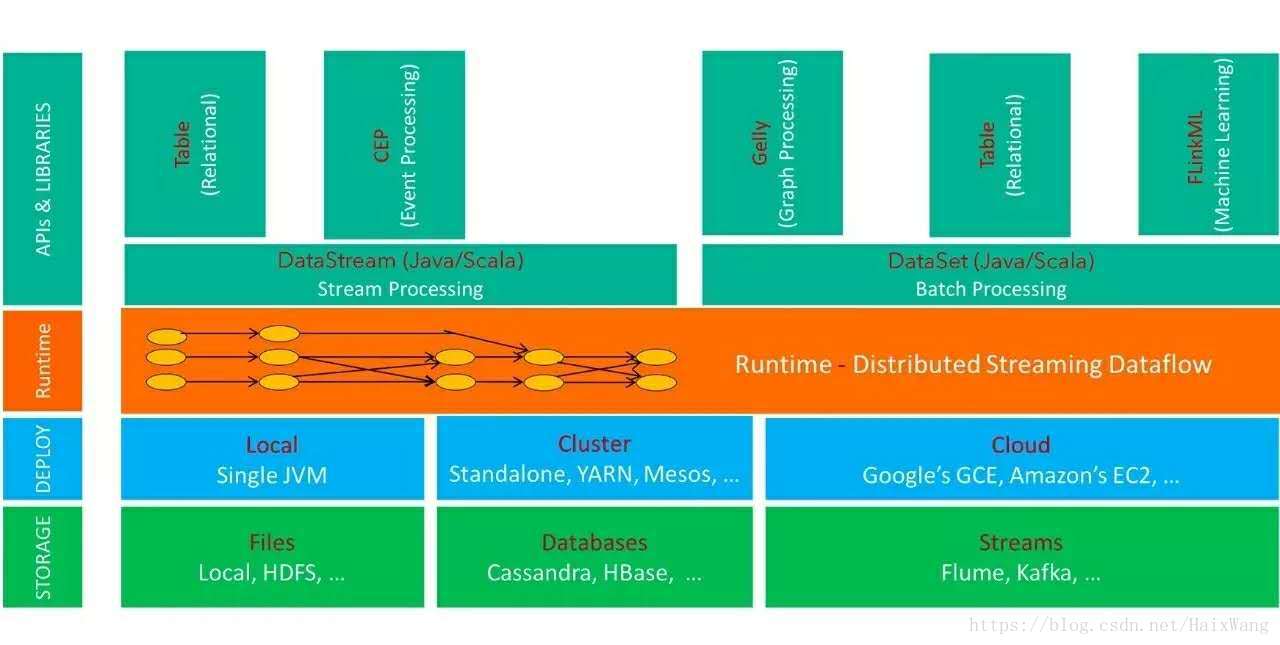
Flink是一款分布式、高性能、高可用、高精确的为数据流应用而生的开源流式处理框架。Flink的核心是在数据流上提供数据分发、通信、具备容错的分布式计算。同时,Flink在流处理引擎上提供了批流融合计算能力,以及SQL表达能力。
2.使用场景(不全面)
- Is stateful and fault-tolerant and can seamlessly recover from failures while maintaining exactly-once application state
- Performs at large scale, running on thousands of nodes with very good throughput and latency characteristics
- Provides fault-tolerant state management
- Accuracy, even with late or out of order data
- Flexible windowing for computing accurate results on unbounded data sets
- Stateful, providing a summary of data that has been processed over time,
Checkpointing mechanism in event of a failure.
3.Flink生态
Storm
始于11年9月
最新版本:1.2.2 2018年5月18日
1.简介
Storm has many use cases: realtime analytics, online machine learning, continuous computation, distributed RPC, ETL, and more. Storm is fast: a benchmark clocked it at over a million tuples processed per second per node. It is scalable, fault-tolerant, guarantees your data will be processed, and is easy to set up and operate.[见参考10]
2.应用场景(不全面)
- real time analytics,
- online machine learning
- continuous computation
- distributed RPC, ETL, and more
Spark Streaming
Spark Streaming接收流数据,并根据一定的时间间隔拆分成一批批batch数据,用抽象接口DStream表示(DStream可以看成是一组RDD序列,每个batch对应一个RDD),然后通过Spark Engine处理这些batch数据,最终得到处理后的一批批结果数据。
Spark2.0提出了Structured Streaming以及连续应用程序的概念:
Structured Streaming是Spark2提出的新的实时流框架(2.0和2.1是实验版本,从Spark2.2开始为稳定版本),Spark2 将流式计算也统一到DataFrame里去。
Structured Streaming 的意义到底何在?
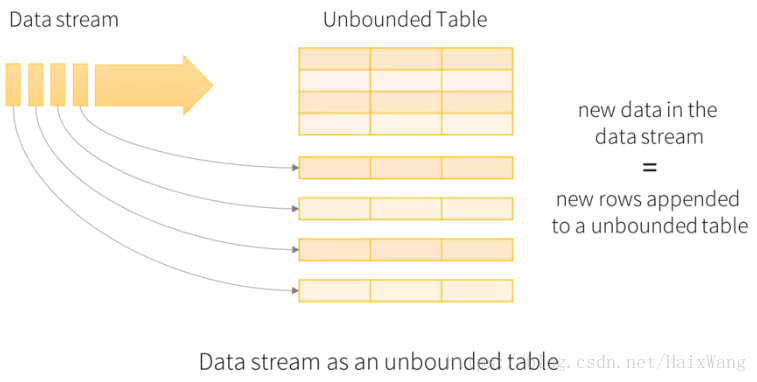
- 重新抽象了流式计算
- 易于实现数据的exactly-once(2.0之前的Spark Streaming 只能做到at-least once)
- 解决了Spark Streaming存在的代码升级,DAG图变化引起的任务失败,无法断点续传的问题
- API简化
1.优势
i) Spark生态和SparkSQL: 技术栈是统一的,SQL,图计算,machine learning的包都是可以互调的。因为它先做的是批处理,和Flink不一样,所以它天然的实时和离线的api是统一的。
ii) 高吞吐: 因为它是Micro-batch的方式,吞吐也是比较高的。
2.劣势
延迟是秒级别。
ElasticSearch
ElasticSearch是Solr的对标产物,但是影响力前两年已经超过Solr,两者都是基于
Lucen的封装。
主要用于全文检索,底层是倒排索引,允许用户近实时地存储、搜索和分析数据。
有的公司也用其做数据分析,以及使用kibana做数据可视化
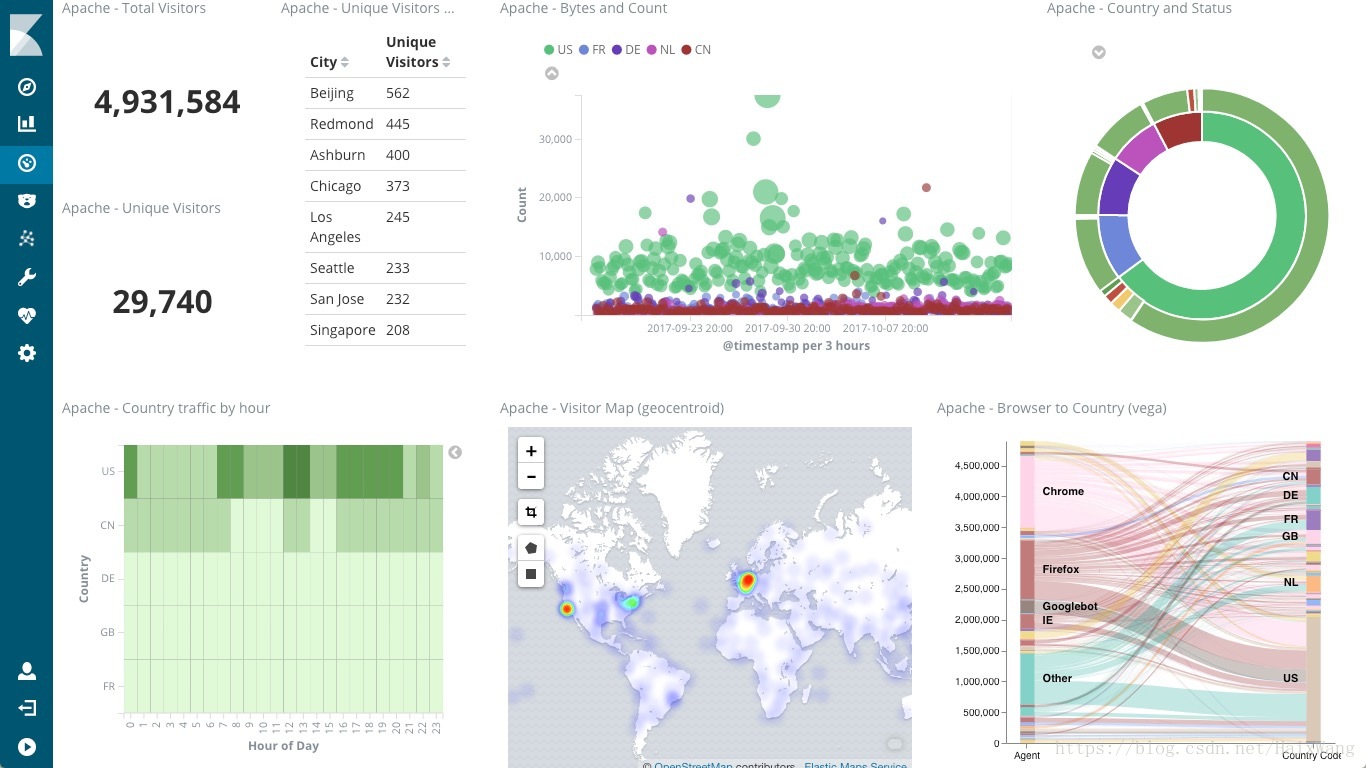
Flink VS Storm
[图片来自参考12]
[以下文字引自参考14]
在开源大数据生态中,Storm是第一代流式计算框架的代表,但它不支持状态管理,即Storm中的状态数据需要用户自己存储在外部存储系统中,数据的持久化和一致性都需要用户自己保证,这会给应用带来一定复杂度。
后续出现的Samza是支持状态管理的第二代流计算技术,内部利用leveldb和kafka来存储数据,但samza只能保证at least once不丢数据,但无法保证exactly once的强一致性,这在一些严格的场景下是有局限性的。近几年火爆的Spark也很快推出了配套的Spark Streaming技术,但其本质上是通过连续不间断的Mini Batch来实现流式处理的,不是纯粹的流式计算思想,时效性上也有一定局限性。
只有最新一代的Flink是相对最为纯粹和完善的流计算技术,在理论模型上具备了一切流计算的特质,也是支持Apache Beam最好的Runner,给我们启动Blink项目带来了非常有价值的启发,因此下面我将介绍下Flink这个Apache开源流计算项目。
[引自参考16]

其他
- 出于吞吐量的考虑,系统并不会在每增加一条消息就采集一次。一般是按照数据大小限制或者时间阈值限制。
- 去重指标
- 事务处理
- 数据模型设计是贯穿整个数据处理过程的,流式数据处理也一样,需要对数据流建模分层[参考20的p80-p84]
3-5 各组件运行情况实时监控
暂略
3-6 容灾、解决单点故障
暂略
3-7 其他技术组件(与实时关联不大)
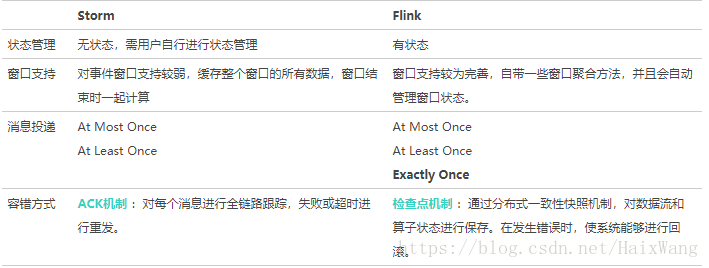
1.kudu
Kudu的设计,就是试图在OLAP与OLTP之间,寻求一个最佳的结合点,从而在一个系统的一份数据中,既能支持OLTP型实时读写能力又能支持OLAP型分析。另外一个初衷,在Cloudera发布的《Kudu: New Apache Hadoop Storage for Fast Analytics on Fast Data》一文中有提及,Kudu作为一个新的分布式存储系统期望有效提升CPU的使用率,而低CPU使用率恰是HBase/Cassandra等系统的最大问题。下面的章节中,主要从论文所揭示的内容来解读Kudu的设计原理。
Kudu提供了与如下一些系统的对接:
- MapReduce: 提供针对Kudu用户表的Input以及Output任务对接。
- Spark: 提供与Spark SQL以及DataFrames的对接。
- Impala: Kudu自身未提供Shell以及SQL Parser,所以,它的SQL能力源自与Impala的集成。在这些集成中,能够很好的感知Kudu表数据的本地性信息,能够充分利用Kudu所提供的过滤器对查询进行优化,同时,Impala本身的DDL/DML语法针对Kudu也做了一些扩展。可以想象,Cloudera在Impala与Kudu的集成上,一定会有更多的发力点。
2.beam
star 数量:2150;贡献者:326
最新稳定版本:2.6.0 2018年8月9日
简介:
通过定义Runner的方式,将批数据或者流数据发送到Spark、Flink等执行任务。
whether the input is a finite data set from a batch data source, or an infinite data set from a streaming data source
Using one of the open source Beam SDKs, you build a program that defines the pipeline. The pipeline is then executed by one of Beam’s supported distributed processing back-ends, which include Apache Apex, Apache Flink, Apache Spark, and Google Cloud Dataflow.
Apache Beam Pipeline Runners:

3.pulsar
简介
[见参考]
Apache Pulsar是一个企业级的分布式消息系统,最初由Yahoo开发并在2016年开源,目前正在Apache基金会下孵化。Plusar已经在Yahoo的生产环境使用了三年多,主要服务于Mail、Finance、Sports、 Flickr、 the Gemini Ads platform、 Sherpa以及Yahoo的KV存储。
Pulsar之所以能够称为下一代消息队列,主要是因为以下特性:
- 线性扩展。能够丝滑的扩容到成百上千个节点(Kafka扩容需要占用很多系统资源在节点间拷贝数据,而Plusar完全不用)
- 高吞吐。已经在Yahoo的生产环境中经受了考验,每秒数百万消息
- 低延迟。在大规模的消息量下依然能够保持低延迟(< 5ms)
- 持久化机制。Plusar的持久化机制构建在Apache BookKeeper之上,提供了写与读之前的IO隔离
- 基于地理位置的复制。Plusar将多地域/可用区的复制作为首要特性支持。用户只需配置好可用区,消息就会被源源不断的复制到其他可用区。当某一个可用区挂掉或者发生网络分区,plusar会在之后不断的重试。
- 部署方式的多样化。既可以运行在裸机,也支持目前例如Docker、K8S的一些容器化方案以及不同的云厂商,同时在本地开发时也只需要一行命令即可启动整个环境。
4.impala
简介:
Cloudera开发,相比Hive,Impala的最大特点也是最大卖点就是它的快速,所以Impala更适合交互式查询。它参考了Google的Dremel系统(Dremel是Google的交互式数据分析系统,它构建于Google的GFS等系统之上,支撑了Google的数据分析服务BigQuery等诸多服务)。
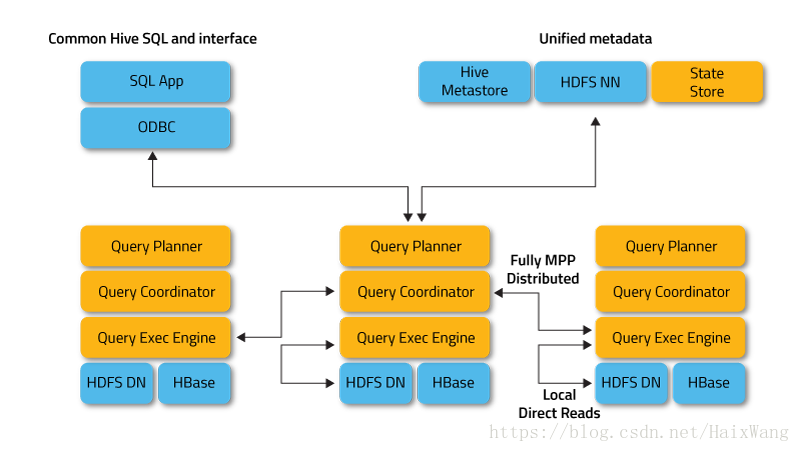
Impala和Hive共享元数据和存储数据,使得Hive和SparkSQL生成的数据可以在Impala里刷新后直接查询,这一点非常重要,因为目前业内广泛采用Hive和SparkSQL做数据的ETL,ETL后数据只要简单刷新就可以在Impala里做交互式查询,为网站,APP等客户端直接提供及时的数据服务。
Impala提高了Apache Hadoop上SQL查询性能的标准,同时保留了熟悉的用户体验。使用Impala,您可以实时查询数据,无论是存储在HDFS还是Apache HBase中 - 包括SELECT,JOIN和聚合函数。此外,Impala使用与Apache Hive相同的元数据,SQL语法(Hive SQL),ODBC驱动程序和用户界面(Hue Beeswax),为面向批处理或实时查询提供熟悉且统一的平台。(因此,Hive用户可以在很少的设置开销下使用Impala。)[引自参考24]
Impala VS Hive:
以下内容大都参考自 Impala vs Hive – Difference Between Hive and Impala
文章很不错,文章从不同的角度比较了Impala与Hive的性能,并讨论为什么Impala比Hive更快,何时使用Impala 、 hive。
- Impala可以直接操作HBase上的数据,对于Hive,我们需要多一步的整合。
- 查询处理
对于Hive,查询都是冷启动的(从批处理的角度理解的?)
Impala避免了启动开销,为了执行查询任务,Impala守护进程在Impala启动时启动,空间换时间 - 中间结果
Hive大多时候将中间结果持久化,这样一来扩展性和容错性更佳,但是会减慢数据处理速度。
Impala大致相反,executors间的处理结果是流式的。 - 复杂类型
Impala并不支持Hive所支持桶的概念(Impala支持分区)。 - 。。。。。。
四、参考
[1.] 消息中间件部署及比较:rabbitMQ、activeMQ、zeroMQ、rocketMQ、Kafka、redis
[2.] 消息队列之 RabbitMQ
[3.] wiki:kafka
[4.] 哪些公司使用RabbitMQ
[5.] logstash input
[6.] logstash output
[7.] 阿里技术:Flink 的新方向在哪里?这场顶级盛会给出了答案
[8.] 阿里技术:如何扛住1.8亿/秒的双11数据洪峰?阿里流计算技术全揭秘
[10.] Storm
[11.] Open Source Stream Processing: Flink vs Spark vs Storm vs Kafka
[12.] 美团技术团队:流计算框架 Flink 与 Storm 的性能对比
[13.] 宜信技术研发中心高级架构师王东:实时敏捷大数据在宜信的实践
[14.] 阿里技术:权威详解 | 阿里新一代实时计算引擎 Blink,每秒支持数十亿次计算
[15.] Architecture of Flink’s Streaming Runtime
[16.] Hadoop技术博文:Flink在唯品会的实践
[17.] Kudu设计原理初探
[18.] 下一代分布式消息队列Apache Pulsar
[19.] Apache Beam Overview
[20.] 《大数据之路——阿里巴巴大数据实践》中国工信出版集团
[21.] Cloudera Data Warehouse:
[22.] The Future of Cloud Data Warehouse: Where is it going?
[23.] 大数据分析查询引擎Impala
[24.] Apache Impala