1、消息队列的类型
1.1 点对点
只有一个消费者做消费TopicA,其他消费者不能消费TopicA中的消息
1.2发布订阅
只要订阅了某个Topic的消费者都可以消费该Topic中的数据
对于TopicA,可以由多个消费者订阅 也可以由多多个消费者消费,同一个组中的消费者不能重复消费
eg:TopicA中有消息 M1 M2 M3 M4 M5 M6 6条消息
组G1、G2 G1下有消费者C1 C2 C3 G2下有消费者 C4 C5 C6
如果C1可以消费了M1 C2消费了M2 C3消费了M3 ,那么C4 C5 C6依然可以消费 M1 M2 M3 因为他们不属于同一个组
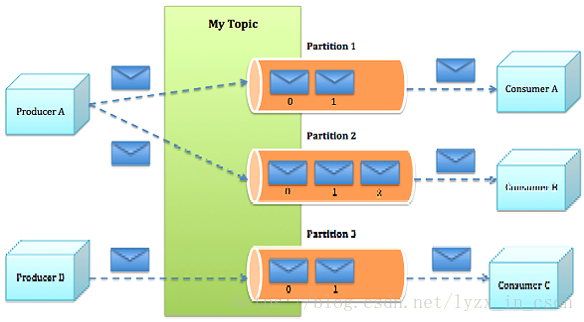
2、kafka分区
分区的目的
2.1、可以使多个同一个组的消费者消费不同分区的数据 这样可以做到并行消费 提升消费者的速率
2.2、便于log的分散 kafka基于Log追加的方式持久化消息 ,分区可以有效的分散日志文件
生产者可以指定发送到Topic的具体某个partition中
生产者异步发送,即不会每一条消息都发送一次 而是先积攒在生产者的内存中,达到一定量的时候一起发送,节省网络资源
3、borker
borker通过日志追加的方式持久化消息 每个分区一个独立的日志文件 kafka消息有序
为了减少磁盘写入的次数,broker会将消息暂时buffer起来,当消息的个数(或尺寸)达到一定阀值时,再flush到磁盘,这样减少了磁盘IO调用的次数
broker不保存消费者的状态 即不保存某个消费者消费到哪儿了,有消费者自己管理
而无状态的消息也使得消息删除也成了麻烦,kafka基于时间的SLA(服务水平保证)
4、Message
消息是kafka通信的单位 每个消息保存在一个Partition中
每条消息包含3个属性
1、offset
2、消息大小 MessageSize
3、data 消息的具体内容
5、kafka 持久化
kafka不同于传统的消息队列持久化,传统的持久化方式是把内存作为磁盘的buffer,而kafka开发者发现,线性的访问磁盘在很多时候比随机访问内存还要快,所以kafka直接把消息线性的写入磁盘
写的时候线性的写入即顺序写入亦即线性追加,读的时候直接读文件即可,这样做的好处是读写不互斥,消息的持久化不会影响消息的读取
持久化时每个Partition都有一个独立的文件,每个partition内部都是有序的,每条消息都会有一个唯一的id即offset偏移
6、稀疏索引
kafka内部建立的是洗漱索引,所谓的稀疏索引指的是每隔一定的字节数建立一条索引,这样做的好处是索引文件变小
稀疏索引图如下
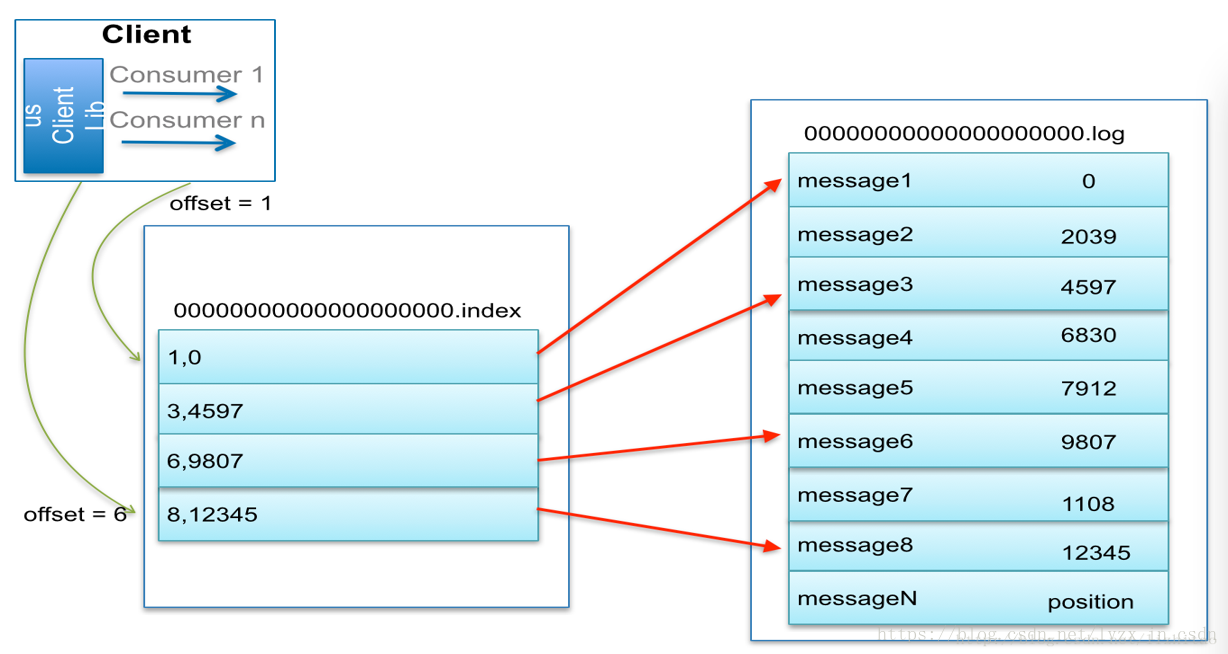
当需要按照offset查找某个消息,如果找到就直接返回,如果没找到就按照类似于二分法的方式查找
7、数据传输的事务定义
7.1、at most once:
最多一次,如果某个消费者C1消费了Topic T1中的某个数据,offset为保存但依然fetch不到该数据
7.2、at least once:
至少一次,如果fetch到某条数据后offset没有更改,此情况下依然能再次fetch到这条数据,推荐这种方式,毕竟多次消费数据比数据丢失要好得多