1、概述
Apache Kafka 是一个分布式高吞吐量的流消息系统,Kafka建立在ZooKeeper同步服务之上。它与Apache Storm和Spark完美集成,用于实时流数据分析,与其他消息传递系统相比,Kafka具有更好的吞吐量,内置分区,数据副本和高度容错功能,因此非常适合大型消息处理应用场景。
2、什么是消息系统
消息系统负责将数据从一个应用程序传输到另一个应用程序,完美的实现了两个应用之间的解耦,消息的传递模式分为两种:
(1)点对点(Point to Point)模式
在点对点系统中,消息被保存在一个队列中。多个消费者可以共同消费队列中的消息,但是一条消息只能被一个消费者消费
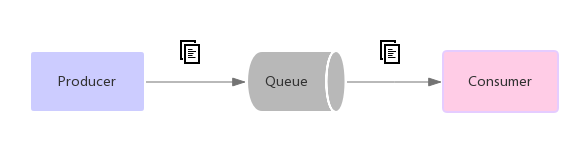
(2)发布订阅(pub-sub)模式
在发布 - 订阅系统中,消息被保存在一个主题(topic)中。消息发布者将消息发布到topic中,多个订阅topic的订阅者会同时收到该消息。在发布 - 订阅系统中,消息生产者称为发布者,消息消费者称为订阅者

3、Kafka特点
- 可靠性: Kafka是分布式的、可分区的、数据可备份的、高度容错的
- 可扩展性: 在无需停机的情况下实现轻松扩展
- 消息持久性: Kafka支持将消息持久化到本地磁盘
- 性能:Kafka的消息发布订阅具有很高的吞吐量,即便存储了TB级的消息,它依然能保持稳定的性能
4. Kafka架构组件
(1)Broker
一个独立的Kafka服务器被称为broker,broker 接收来自生产者的消息,为消息设置偏移量,并保存消息到磁盘中。 broker 为消费者提供服务,对读取分区的请求作出响应,返
回已经提交到磁盘上的消息。

(2)Topic
Kafka的消息通过Topic主题来分类,Topic类似于关系型数据库中的表,每个Topic包含一个或多(Partition)分区
注:一个Topic主题到底该设置多少分区合理呢?一般:分区数目 = Topic的吞吐量 / Consumer的吞吐量
(3)Partition
分区,一个Topic包含一个或多个Partition分区,多个分区会分布在Kafka集群的不同服务节点上,消息以追加的方式写入一个或多个分区中。
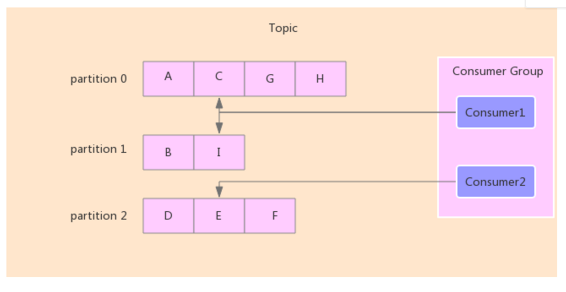
注:由于一个主题(Topic)一般包含多个(Partition)分区,因此无法在整个主题范围内保证消息的顺序,但可以保证消息在单个分区内的顺序,如将Topic分为3个区,向该Topic中发送消息分别为:A、B、C、D、E、F、G、H、I 共9条消息,那么当消息写入分区后可能为如下图

(4)Producer
消息的生产者,负责发布消息到Kafka broker,生产者在默认情况下把消息均衡地分布到主题的所有分区上,用户也可以自定义分区器来实现消息的分区路由。
(5)Consumer
消息的消费者,从Kafka broker读取消息的客户端,消费者把每个分区最后读取的悄息偏移量保存在 Zookeeper 或 Kafka 上,如果悄费者关闭或重启,它的读取状态不会丢失。
(6)Consumer Group
每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group),一个或多个Consumer组成的群组可以共同消费一个Topic中的消息,但每个分区只能被群组中的一个消费者操作,如下图,Consumer1对应操作分区0与分区1,Consumer2对应操作分区2
5、Kafka的副本机制
每个分区可以指定n个副本,那么它可以承受n-1个节点故障,一个分区中的多个副本中有一个副本为leader,其余的为follow
注:zookeeper最多可以承受(n-1)/2个节点故障
副本模型:
(1)同步复制
procudure从zk中找到分区副本的leader,并发送message消息,leader收到消息后立即写入本地log,然后follow开始pull消息,每个follow将pull到的消息也写入本地log后,向leader发送消息确认回执,leader在收到所有的follow确认回执后,再向procudure发送确认回执。
(2)异步复制
leader的本地log写入完成立即向procudure发送确认回执