HashMap底层原理实现源码分析
最近面试了几次不管是笔试还是面试发现都出现了大量的集合和多线程,集合里尤其是HashMap每次闭问,所以这里做一个学习总结
概述
HashMap基于Map接口实现,元素以键值对的方式存储,并且允许使用null 建和null值因为key不允许重复,因此只能有一个键为null,另外HashMap不能保证放入元素的顺序,它是无序的,和放入的顺序并不能相同。HashMap是线程不安全的
HashMap的存储结构
JDK 7及以前版本:HashMap是数组+链表结构(即为链地址法) ,每个节点是 Entry[] 对象
JDK 8版本发布以后:HashMap是数组+链表+红黑树实现。 每个节点是 Node对象

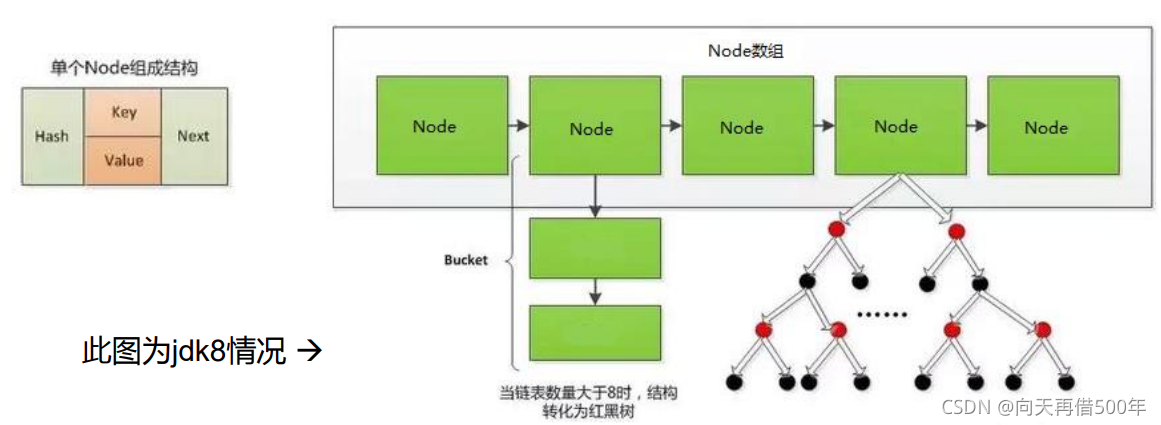
HashMap源码中的重要常量
DEFAULT_INITIAL_CAPACITY : HashMap的默认容量,16
MAXIMUM_CAPACITY : HashMap的最大支持容量,2^30
DEFAULT_LOAD_FACTOR:HashMap的默认加载因子
TREEIFY_THRESHOLD:Bucket中链表长度大于该默认值,转化为红黑树
UNTREEIFY_THRESHOLD:Bucket中红黑树存储的Node小于该默认值,转化为链表
MIN_TREEIFY_CAPACITY:桶中的Node被树化时最小的hash表容量。(当桶中Node的数量大到需要变红黑树时,若hash表容量小于MIN_TREEIFY_CAPACITY时,此时应执行resize扩容操作这MIN_TREEIFY_CAPACITY的值至少是TREEIFY_THRESHOLD的4倍。)
table:存储元素的数组,总是2的n次幂
entrySet:存储具体元素的集
size:HashMap中存储的键值对的数量
modCount:HashMap扩容和结构改变的次数。
threshold:扩容的临界值,=容量*填充因子
loadFactor:填充因子
//默认的初始化容量为16,必须是2的n次幂
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // 16
//最大容量为 2^30,一个很大的数
static final int MAXIMUM_CAPACITY = 1 << 30;
//默认的加载因子0.75,乘以数组容量得到的值,用来表示元素个数达到多少时,需要扩容。
//为什么设置 0.75 这个值呢,简单来说就是时间和空间的权衡。
//若小于0.5,则数组长度达到一半大小就需要扩容,空间使用率大大降低,
//若大于0.5如1,则会增大hash冲突的概率,影响查询效率。
static final float DEFAULT_LOAD_FACTOR = 0.75f;
//刚才提到了当链表长度过长时,会有一个阈值,超过这个阈值8就会转化为红黑树
static final int TREEIFY_THRESHOLD = 8;
//当红黑树上的元素个数,减少到6个时,就退化为链表
static final int UNTREEIFY_THRESHOLD = 6;
//链表转化为红黑树,除了有阈值的限制,还有另外一个限制,需要数组容量至少达到64,才会树化。
//这是为了避免,数组扩容和树化阈值之间的冲突。
static final int MIN_TREEIFY_CAPACITY = 64;
//存放所有Node节点的数组,主数组
transient Node<K,V>[] table;
//存放所有的键值对
transient Set<Map.Entry<K,V>> entrySet;
//map中的实际键值对个数,即数组中元素个数
transient int size;
//数组扩容阈值
int threshold;
//加载因子
final float loadFactor;
继承关系
public class HashMap<K,V>extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable
其实这里有一点有意识的是,这里的继承关系有点多余,在HashMap的父类AbstractMap中是实现了Map接口的,结果在HashMap中又实现了一遍Map接口,重复了,这一点可以和面试官谈一谈
构造器
//默认无参构造,指定一个默认的加载因子
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR;
}
//可指定容量的有参构造,但是需要注意当前我们指定的容量并不一定就是实际的容量
public HashMap(int initialCapacity) {
//同样使用默认加载因子
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
//可指定容量和加载因子,但是笔者不建议自己手动指定非0.75的加载因子
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
//这里就是把我们指定的容量改为一个大于它的的最小的2次幂值,如传过来的容量是28,则返回32
//注意这里,按理说返回的值应该赋值给 capacity,即保证数组容量总是2的n次幂
this.threshold = tableSizeFor(initialCapacity);
}
//可传入一个已有的map
public HashMap(Map<? extends K, ? extends V> m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);
}
HashMap装填因子,负载因子,加载因子为什么是0.75
装填因子设置为1:空间利用率得到了很大的满足,很容易碰撞,产生链表,导致查询效率低
装填因子设置为0.5: 碰撞的概率低,扩容,产生链表的几率低,查询效率高,空间利用率低
HashMap的长度为什么必须为2^n
- h&(length-1)等效 h%length 操作,等效的前提是:length必须是2的整数倍
- 防止哈希冲突,位置冲突
HashMap JDK7和JDK8的不同
1.JDK8中 HashMap map = new HashMap();//默认情况下,先不创建长度为16的数组
2.当首次调用map.put()时,再创建长度为16的数组,JDK7是直接创建的
3.JDK8数组为Node类型,在jdk7中称为Entry类型
4.形成链表结构时,新添加的key-value对在链表的尾部(七上八下),JDK7是头插法,JDK8是尾插法
5.当数组指定索引位置的链表长度>8时,且map中的数组的长度> 64时,此索引位置上的所有key-value对使用红黑树进行存储。