该文章参考 https://blog.csdn.net/keketrtr/article/details/78802571
redis主从模式
主从模式指的是使用一个redis实例作为主机,其余的实例作为备份机。主机和从机的数据完全一致,主机支持数据的写入和读取等各项操作,而从机则只支持与主机数据的同步和读取,也就是说,客户端可以将数据写入到主机,由主机自动将数据的写入操作同步到从机。主从模式很好的解决了数据备份问题,并且由于主从服务数据几乎是一致的,因而可以将写入数据的命令发送给主机执行,而读取数据的命令发送给不同的从机执行,从而达到读写分离的目的。
主从模式其实也是多个redis实例组成的,因而redis主从模式的配置可以理解为多个不同的redis实例通过一定的配置告知其相互之间的主从关系。主从模式的配置(redis.conf)主要的配置点有两个:当前实例端口号和当前实例是主机还是从机,是从机的话其主机的ip和端口是什么。
主从模式存在的问题:主从模式下可以将读写操作分配给不同的实例进行从而达到提高系统吞吐量的目的,但也正是因为这种方式造成了使用上的不便,因为每个客户端连接redis实例的时候都是指定了ip和端口号的,如果所连接的redis实例因为故障下线了,而主从模式也没有提供一定的手段通知客户端另外可连接的客户端地址,因而需要手动更改客户端配置重新连接。另外,主从模式下,如果主节点由于故障下线了,那么从节点因为没有主节点而同步中断,因而需要人工进行故障转移工作。
redis中sentinel(哨兵)配置
为了解决这两个问题,在2.8版本之后redis正式提供了sentinel(哨兵)架构。关于sentinel,这里需要说明几个概念:
| 名词 | 逻辑结构 | 物理结构 |
| 主节点 | redis主服务/数据库 | 一个独立的redis进程 |
| 从节点 | redis从服务/数据库 | 一个独立的redis进程 |
| sentinel节点 | 监控redis数据节点 | 一个独立的sentinel进程 |
| sentinel节点集合 | 若干sentinel节点的抽象集合 | 若干sentinel节点进程 |
| 应用方 | 泛指一个或多个客户端 | 一个或多个客户端线程或进程 |
每个sentinel节点其实就是一个redis实例,与主从节点不同的是sentinel节点作用是用于监控redis数据节点的,而sentinel节点集合则表示监控一组主从redis实例多个sentinel监控节点的集合,比如有主节点master和从节点slave-1、slave-2,为了监控这三个主从节点,这里配置N个sentinel节点sentinel-1,sentinel-2,...,sentinel-N。如下图是sentinel监控主从节点的示例图:
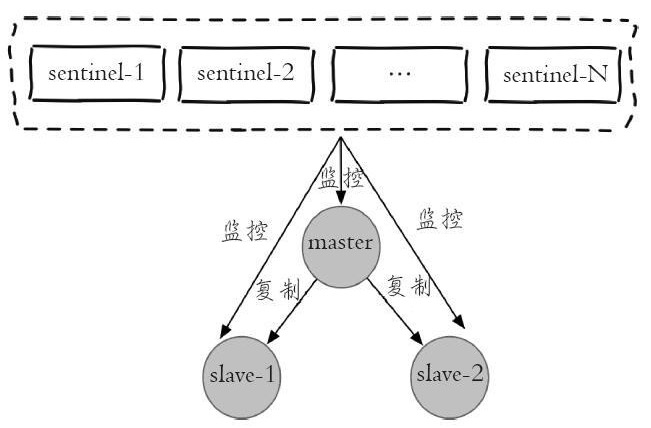
从图中可以看出,对于一组主从节点,sentinel只是在其外部额外添加的一组用于监控作用的redis实例。在主从节点和sentinel节点集合配置好之后,sentinel节点之间会相互发送消息,以检测其余sentinel节点是否正常工作,并且sentinel节点也会向主从节点发送消息,以检测监控的主从节点是否正常工作。前面讲到,sentinel架构的主要作用是解决主从模式下主节点的故障转移工作的。这里如果主节点因为故障下线,那么某个sentinel节点发送检测消息给主节点时,如果在指定时间内收不到回复,那么该sentinel就会主观的判断该主节点已经下线,那么其会发送消息给其余的sentinel节点,询问其是否“认为”该主节点已下线,其余的sentinel收到消息后也会发送检测消息给主节点,如果其认为该主节点已经下线,那么其会回复向其询问的sentinel节点,告知其也认为主节点已经下线,当该sentinel节点最先收到超过指定数目(配置文件中配置的数目和当前sentinel节点集合数的一半,这里两个数目的较大值)的sentinel节点回复说当前主节点已下线,那么其就会对主节点进行故障转移工作,故障转移的基本思路是在从节点中选取某个从节点向其发送slaveof no one(假设选取的从节点为127.0.0.1:6380),使其称为独立的节点(也就是新的主节点),然后sentinel向其余的从节点发送slaveof 127.0.0.1 6380命令使它们重新成为新的主节点的从节点。重新分配之后sentinel节点集合还会继续监控已经下线的主节点(假设为127.0.0.1:6379),如果其重新上线,那么sentinel会向其发送slaveof命令,使其成为新的主机点的从节点,如此故障转移工作完成。
redis集群的配置
redis集群是在redis 3.0版本推出的一个功能,其有效的解决了redis在分布式方面的需求。当遇到单机内存,并发和流量瓶颈等问题时,可采用Cluster方案达到负载均衡的目的。并且从另一方面讲,redis中sentinel有效的解决了故障转移的问题,也解决了主节点下线客户端无法识别新的可用节点的问题,但是如果是从节点下线了,sentinel是不会对其进行故障转移的,并且连接从节点的客户端也无法获取到新的可用从节点,而这些问题在Cluster中都得到了有效的解决。
redis集群中数据是和槽(slot)挂钩的,其总共定义了16384个槽,所有的数据根据一致哈希算法会被映射到这16384个槽中的某个槽中;另一方面,这16384个槽是按照设置被分配到不同的redis节点上的,比如启动了三个redis实例:cluster-A,cluster-B和cluster-C,这里将0-5460号槽分配给cluster-A,将5461-10922号槽分配给cluster-B,将10923-16383号槽分配给cluster-C(总共有16384个槽,但是其标号类似数组下标,是从0到16383)。也就是说数据的存储只和槽有关,并且槽的数量是一定的,由于一致hash算法是一定的,因而将这16384个槽分配给无论多少个redis实例,对于确认的数据其都将被分配到确定的槽位上。redis集群通过这种方式来达到redis的高效和高可用性目的。
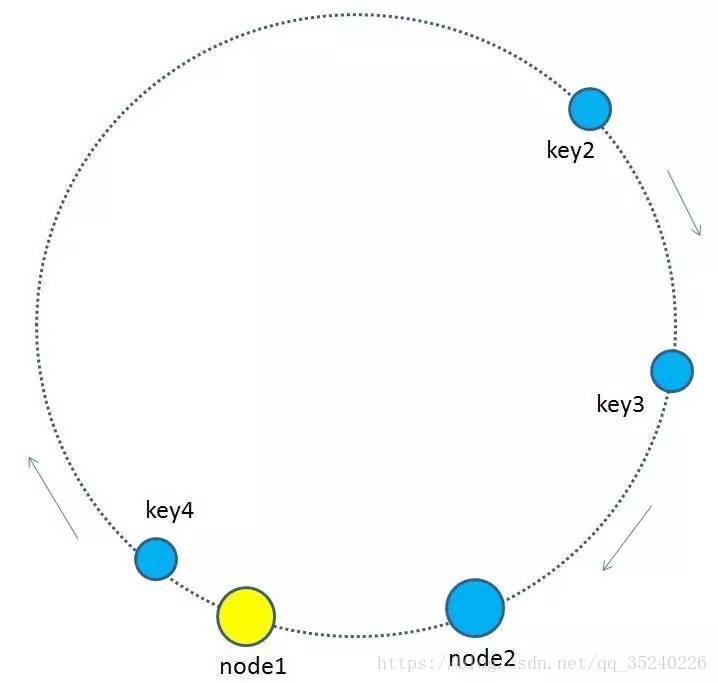
这里需要进行说明的一点是,一致哈希算法根据数据的key值计算映射位置时和所使用的节点数量有非常大的关系。一致哈希分区的实现思路是为系统中每个节点分配一个token,范围一般在0~2^32,这些token构成一个哈希环,数据读写执行节点查找操作时,先根据key计算hash值,然后顺时针找到第一个大于等于该hash值的token节点,需要操作的数据就保存在该节点上。通过分析可以发现,一致哈希分区存在如下问题:
- 加减节点会造成哈希环中部分数据无法命中,需要手动处理或忽略这部分数据;
- 当使用少量节点时,节点变化将大范围影响环中数据映射,因此这种方式不适合少量节点的分布式方案;
- 普通的一致性哈希分区在增减节点时需要增加一倍或减去一半节点才能保证数据和负载的平衡。
正是由于一致哈希分区的这些问题,redis使用了虚拟槽来处理分区时节点变化的问题,也即将所有的数据映射到16384个虚拟槽位上,当redis节点变化时数据映射的槽位将不会变化,并且这也是redis进行节点扩张的基础。
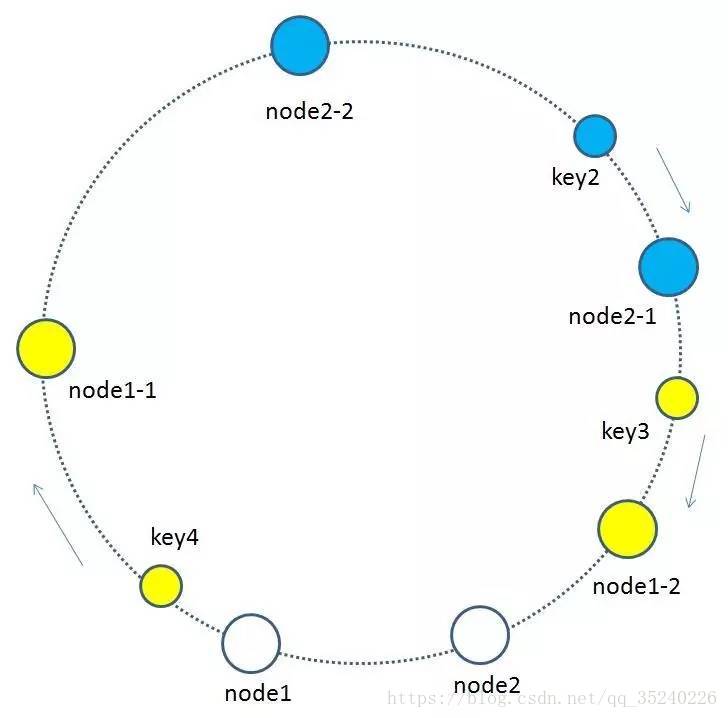
于是提出虚拟节点的概念:
基于原来物理节点,映射出出多个子节点,最后把子节点映射到环形空间。
,假如node1的ip是192.168.1.109,那么原node1节点在环形空间的位置就是hash(“192.168.1.109”)。
我们基于node1构建两个虚拟节点,node1-1 和 node1-2,虚拟节点在环形空间的位置可以利用(IP+后缀)计算,例如:
hash(“192.168.1.109#1”),hash(“192.168.1.109#2”)
此时,环形空间中不再有物理节点node1,node2,只有虚拟节点node1-1,node1-2,node2-1,node2-2。由于虚拟节点数量较多,缓存key与虚拟节点的映射关系也变得相对均衡了。