python–半自动爬取Leetcode上面的所有题目并转成word打印
写在前面
最近想做下算法题目,补补基础,在手机上面或者电脑上面做的不是那么的爽,就想着打印下来,然后在每道题目下面写下草稿,后面再用电脑写代码。
但是找了半天都没有整理版的题目,要不然就是有答案的,要不然就是英文的,要不然就是按分类来的,要不然就是不全的。
所以就打算自己写一个,现在的版本是按照难度来划分的,然后后面的连接是整理好的文本。已经分栏分好了。纸张的利用率也是比较高。
话不多说,看下代码吧。
代码逻辑
代码结构:
---leetcode 文件夹
------leetcode.py 主要的代码
------python-leetcode.html 题目的html
------python-leetcode-easy.html 所有的简单题目
------python-leetcode-hard.html 所有的困难题目
------python-leetcode-m.html 所有的中等题目
------result1-200.txt 部分结果
<tbody class="reactable-data">代码流程
def run(self):
self.get_urls()
self.get_description_by_request()
self.save_problem()
这个是main函数的主要流程
- self.get_urls() 是根据python-leetcode.html读取所有的题目url,然后存到数组里面
- self.get_description_by_request() 获取详细的题目信息
- self.save_problem() 将题目信息存到文本里面
具体代码
leetcode.py
# -*- coding: UTF-8 -*-
from urllib import request
# 导入BeautifulSoup模块和re模块,re是python中正则表达式的模块. 涓€浜�-涓夊垎-鍦帮紝鐙鍙戝竷
# from BeautifulSoup import soup
import bs4
import re
import datetime
import aiohttp, asyncio
import requests, os, time
import random
def get_html(url): # 获取页面的源代码
page = request.urlopen(url)
html = page.read()
html = html.decode('utf-8')
return html
USER_AGENTS = [
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)",
"Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5",
"Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52",
]
# 随机生成user-agent
class RandomUAMiddleware(object):
def process_request(self, request, spider):
request.headers["User-Agent"]=random.choice(USER_AGENTS)
def request_url(url):
print("request_url")
response = requests.get(url)
response.encoding = 'utf-8'
if response.status_code == 200:
return response
else:
print("请求失败,errcode = %s" % response.status_code)
def request_url_read(url):
print("request_url_read")
headers = {'User-Agent': random.choice(USER_AGENTS)}
response = requests.get(url, headers=headers)
response.encoding = 'utf-8'
if response.status_code == 200:
return response
else:
print("请求失败,errcode = %s" % response.status_code)
return None
async def __get_content(link):
# print("__get_content")
async with aiohttp.ClientSession() as session:
response = await session.get(link)
content = await response.read()
return content
class AttrDisplay:
def gatherAttrs(self):
return " , ".join("{}={}"
.format(k, getattr(self, k))
for k in self.__dict__.keys())
# attrs = []
# for k in self.__dict__.keys():
# item = "{}={}".format(k, getattr(self, k))
# attrs.append(item)
# return attrs
# for k in self.__dict__.keys():
# attrs.append(str(k) + "=" + str(self.__dict__[k]))
# return ",".join(attrs) if len(attrs) else 'no attr'
def __str__(self):
return "[{}:{}]".format(self.__class__.__name__, self.gatherAttrs())
class Problem(AttrDisplay):
def __init__(self):
self.number = 0
self.title = ""
self.link = ""
self.description = ""
def format_to_file(self):
result = str(self.number) + "、" + self.title
result += "\n"
description_str = self.description.replace("\n\n", "\n")
description_str = description_str.replace(" ", " ")
description_str = description_str.replace("−", "-")
description_str = description_str.replace(""", "\"")
description_str = description_str.replace("'", "\'")
description_str = description_str.replace(">", ">")
description_str = description_str.replace("<", "<")
description_str = description_str.replace("≤", "<=")
description_str = description_str.replace("‘", "\'")
description_str = description_str.replace("’", "\'")
description_str = description_str.replace("⌊", " ")
description_str = description_str.replace("→", "→")
result += description_str
result += "\n"
result += "\n"
result += "\n"
result += "\n"
return result
class MySpider(object):
# 初始化
def __init__(self):
self.base_url = "https://leetcode-cn.com"
self.headers = {
'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) '
' AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1'
}
self.num = 1
print("MySpider init ")
self.problem_list = []
def get_urls(self):
# 打开一个文件
fo = open("python-leetcode.html", "r", encoding='UTF-8')
html_contont = fo.read()
soup = bs4.BeautifulSoup(html_contont, "html.parser")
# div_main = soup.html.body.find('tbody', {'class': 'reactable-data'})
tr_list = soup.html.body.find_all('tr')
for tr in tr_list:
problem = Problem()
for index, td in enumerate(tr.children):
print(index)
print(td)
if index == 1:
# print(td.string)
problem.number = td.string
if index == 2:
problem.link = self.base_url + td.div.a.attrs["href"]
problem.title = td.div.a.string
self.problem_list.append(problem)
def get_description_by_request(self):
for index, problem in enumerate(self.problem_list):
if index > -1:
print(problem.link)
response = request_url_read(problem.link)
if response is None:
print("response is None " + str(index))
continue
rep_html = response.text
soup = bs4.BeautifulSoup(rep_html, "html.parser")
# 获取题目内容
meta_description = soup.html.head.find('meta', {'name': 'description'})
description = meta_description.attrs["content"]
problem.description = description
time.sleep(1)
if index % 10 == 0:
time.sleep(4)
def save_problem(self):
for problem in self.problem_list:
fo = open("result.txt", "a", encoding='UTF-8') # a 打开一个文件用于追加。
fo.write(str(problem.format_to_file()))
fo.close()
def run(self):
self.get_urls()
self.get_description_by_request()
self.save_problem()
def main():
mySpider = MySpider()
# links = mySpider.get_page_links("http://m.sfv5.com/shaonv/2018/0425/5436.html")
# mySpider.download_by_links(links,'好')
mySpider.run()
if __name__ == "__main__":
main()
python-leetcode.html 部分
<!DOCTYPE html>
<html>
<head>
</head>
<body>
<tbody class="reactable-data"><tr><td label="[object Object]"></td><td label="[object Object]">899</td><td value="Orderly Queue" label="[object Object]"><div><a href="/problems/orderly-queue">有序队列</a> <span class="fa fa-info-circle title-tooltip" data-toggle="tooltip" data-placement="top" data-original-title="Orderly Queue" aria-hidden="true" style="cursor: pointer;"></span> <span class="badge badge-pill new-question-pill">新</span></div></td><td label="[object Object]"></td><td value="24.087591240875913" label="[object Object]">24.1%</td><td value="[object Object]" label="[object Object]"><span class="label label-danger round">困难</span></td></tr></tbody>
</body>
</html> result1-200.txt
1、两数之和
给定一个整数数组和一个目标值,找出数组中和为目标值的两个数。
你可以假设每个输入只对应一种答案,且同样的元素不能被重复利用。
示例:
给定 nums = [2, 7, 11, 15], target = 9
因为 nums[0] + nums[1] = 2 + 7 = 9
所以返回 [0, 1]
7、反转整数
给定一个 32 位有符号整数,将整数中的数字进行反转。
示例1:
输入: 123
输出: 321
示例 2:
输入: -123
输出: -321
示例 3:
输入: 120
输出: 21
注意:
假设我们的环境只能存储 32 位有符号整数,其数值范围是 [-231, 231- 1]。根据这个假设,如果反转后的整数溢出,则返回 0。
9、回文数
判断一个整数是否是回文数。回文数是指正序(从左向右)和倒序(从右向左)读都是一样的整数。
示例 1:
输入: 121
输出: true
示例2:
输入: -121
输出: false
解释: 从左向右读, 为 -121 。 从右向左读, 为 121- 。因此它不是一个回文数。
示例 3:
输入: 10
输出: false
解释: 从右向左读, 为 01 。因此它不是一个回文数。
进阶:
你能不将整数转为字符串来解决这个问题吗?
13、罗马数字转整数运行结果
result1-200.txt 各个题目中间会有空格
扫描二维码关注公众号,回复:
3428143 查看本文章

1、两数之和
给定一个整数数组和一个目标值,找出数组中和为目标值的两个数。
你可以假设每个输入只对应一种答案,且同样的元素不能被重复利用。
示例:
给定 nums = [2, 7, 11, 15], target = 9
因为 nums[0] + nums[1] = 2 + 7 = 9
所以返回 [0, 1]
7、反转整数
扩展
这个内容是半自动的,可以根据自己的需求,爬取不同的题目。
可以看到代码中的题目链接是根据python-leetcode.html中的标签内容进行获取的,所以这里是可以定制化的。
这个里面的内容登录https://leetcode-cn.com/problemset/all/,筛选自己的内容找到标签,整个复制并替换。然后重新运行代码就好了
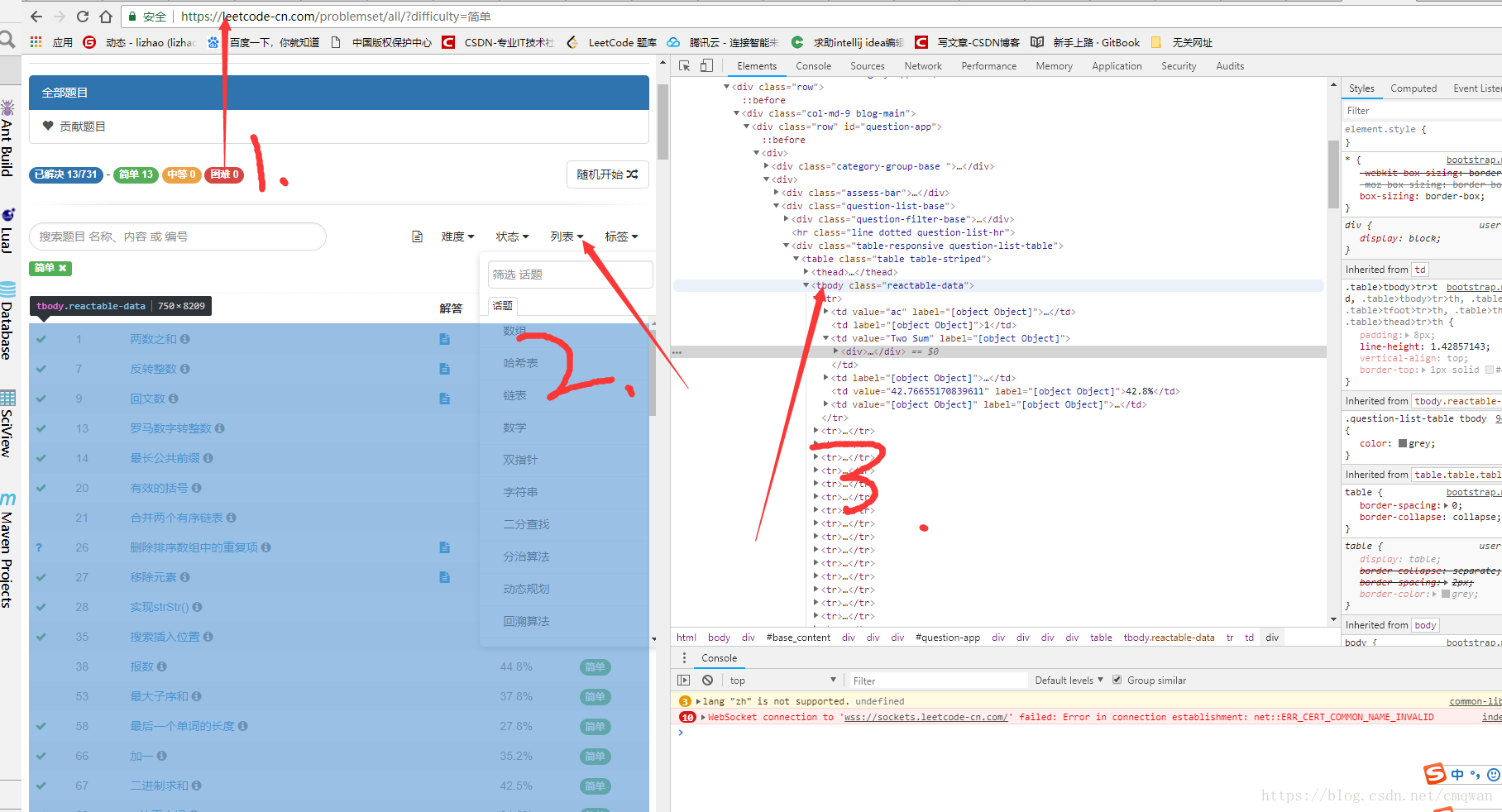
成品结果
有了文本,然后改到word里面,再排版下像这个样子:
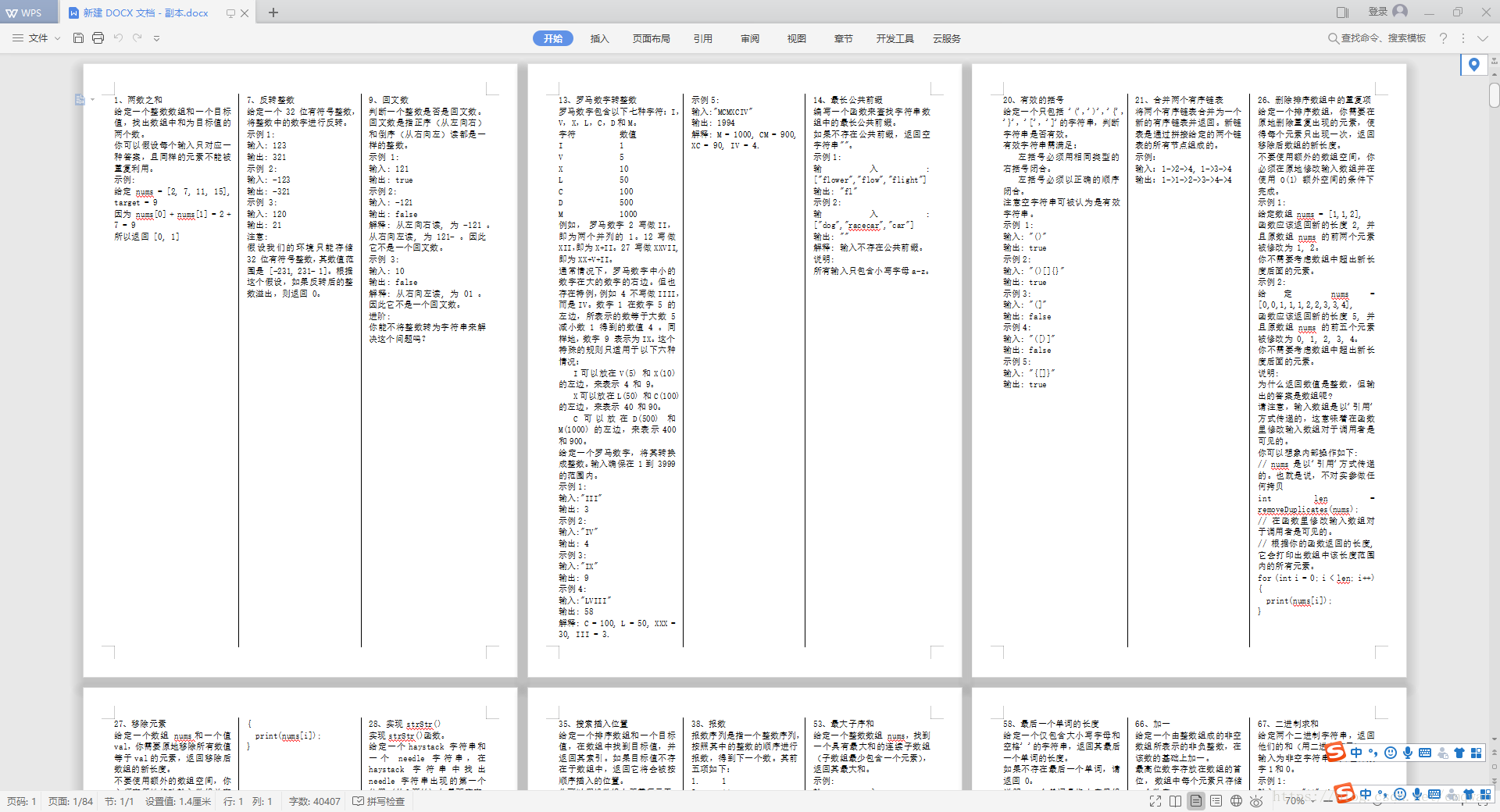
下载链接
代码链接:码云链接
成品下载链接:leetcode所有简单题目包括排版