随着大数据、人工智能、云计算技术的日渐成熟和飞速发展,传统的运维技术和解决方案已经不能满足需求,智能运维已成为运维的热点领域。同时,为了满足大流量、用户高质量体验和用户分布地域广的互联网应用场景,大型分布式系统的部署方式也成为了高效运维的必然之选。如何提升运维的能力和效率,是保障业务高可用所面临的最大挑战。本篇文章以百度基于PaddlePaddle的新能源充电桩为切入点,深入介绍智能运维在电力行业的实际应用。

以下为演讲实录。
电力行业运维过程中的痛点与机遇
众所周知,典型电力行业包括发电、输电、配电、用电等多个阶段,而电力作为关系国计民生的重要资源,在各个阶段无论针对电网或是终端设备的运行维护都是保障电网安全稳定运行的重要手段。此外,目前中国已经建成全球范围内信息化程度最高的电网,而电网的工程师们仍在持续学习和引入新技术,大数据和深度学习是他们重点关注的方向。我们发现,针对电力运维,有三个典型的场景比较适合大数据与深度学习技术,包括:
1.电网设备维护:通过对电网电能质量分析系统、分布式监控系统产生的数据进行学习,实现故障提前预警,减少电网设备运维成本;
2.规划电网调度:通过对气象数据、用户行为数据等分析建模,实现用电管理,优化电网调度提升效率;
3.用电异常识别:通过对终端设备,如智能电表的数据分析,实现用电异常识别,降低用电损失提升效率。
基于电力行业四大特点,充电桩智能运维需要新的技术方案

图一:电力行业四大特点
电力行业有四大特点:
1.市场规模大:发改委在2015年颁布的《充电桩建设指南》指出,计划到2020年全国建成超过480万个充电桩,图中为根据指南及目前市场情况的测算,到2020年整个市场规模将达900亿。而2017年全国保有量为21.3万个,仅北京地区已超3万个,一方面鲜有保有量已经不小,此外从今年开始将是充电桩建设的高速爆发期;
2.强制性检测:国家电网要求存量市场充电桩每年必须定期检查并出具报告,新增充电桩全部联网并要求强制测试。如果没有运维保障,一旦出现问题就有可能带来车毁人亡的重大事故;
3.运维成本高:现场故障多,环境复杂,造成现场运维人力成本高;
4.行业痛点强:目前针对充电桩运维已经有技术方案,但传统厂商一般基于传统数据库搭建方案,一旦出现增量上网,很难应对大数据和扩容的挑战。此外由于缺乏数据挖掘的工具和知识,数据利用率不高。基于以上四个特点,充电桩智能运维需要新的技术方案。

图2:充电桩智能运维新方案
在此背景下,我们和博电电气联合提出了充电桩智能运维新方案。博电电气是行业领先的电力测试设备供应商,主要服务国家电网、南方电网和海外电网运营商。在这套新的方案中,我们通过一揽子技术方案包括底层的物联网设备接入、边缘计算,到中层的云计算平台,上层的大数据平台,解决设备管理复杂、扩容难等问题。同时,基于百度AI能力,我们搭建了多种运维模型,包括设备监测,到故障诊断,到预测性维保。以充电桩故障诊断为例,基于传统数据分析工具如matlab、labview和本地计算资源,已经达到95%的故障识别率。但我们通过PaddlePaddle的深度学习和分布式计算,比较容易的就将准确度再提升了4个点,并给客户带来了经济价值。
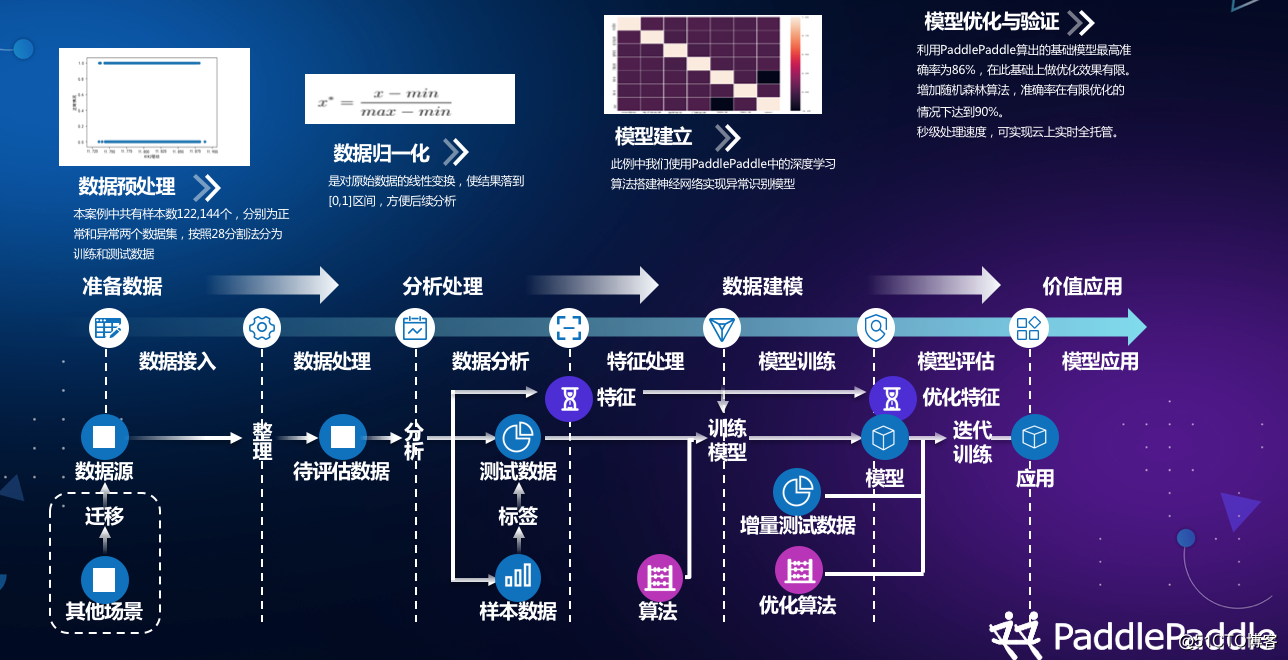
图三:基于PaddlePaddle的充电桩异常诊断建模
提问环节
提问:充电桩如何联网?
赵乔:本身充电桩是离线的,我们采取的是在充电桩上出一个加了硬件的枪头,这个硬件里面跑的是模型和功能等等,除模型外,上面还加了3G的模块,这个模块就是支持IOT标准的工业企业,这样就能联网了。
提问:数据如何上传到云端到服务器?
赵乔:数据会直接传上去。算法分别跑在本地和云端,其中会有一部分跑内部端,在算法要求高实时反馈的情况下,如闭环的反馈是在毫秒级,那算法就要跑在前端,这是不能特别复杂的模型。
提问:通信技术很复杂吗?
赵乔:不复杂,是一个标准的通信技术,跟4G一样的业界标准,且本身底层算法不需要开发。
提问:我们现在的算法要上传到服务器,是在云区,有没有什么解决方法。
赵乔:我们之前的算法在海上信号不好,但是有专用的工业wifi,可能距离是15米,但软件会比较麻烦。比如先缓存,等联网了再断,这样很麻烦。我觉得这个没有办法绕开,如果你的应用要求联网必须一直联,可能通过软件很难做,你只能通过考虑硬件,我们之前想专门用工业WIFI,功率很强。
提问:我在做LT的预算,利用RFID传感器,采集相当大的wifi信号数据,现在遇到的几个问题,第一个问题是调用的人工智能的算法,对硬件的算力要求比较高,想问老师是怎么看这个问题?
赵乔:跟你跑的模型有关系,需要运行的是引擎,比如百度的ERE,需要知道部署地方的环境,会占资源,百度的占十兆资源,还有的不用考虑,编译好的直接下去。
提问:一部分是在本地,另一部分在云上?
赵乔:云上很少,云上的算力比较大,相当于是不断训练模型,但是在端上用,我们的部分是跑在AIM上,其实端不一定是嵌入式,也可以是牵扯硬件,如笔记本。
提问:百度云平台对IOT开放吗?
赵乔:可以,你可以在上面搜百度云天工。
提问:我想问规划处理,你们有非数值类型的数据吗?是一串字符串。
嘉宾女:我们处理这个,只涉及到数值类的,非数值的就是词项量,你算一些方法尝试一下。
提问:非数值类型的怎么处理?
嘉宾女:变成向量。
提问:如果这个字符串不是固定的,有可能是千变万化的。
嘉宾女:你规划的目的是什么?
提问:不会像词向量那样,词可能是约定好的一万个,可能有很多种,无法做到词向量。
嘉宾女:还是要回归到解决问题是什么,你的目标是想看一下训练数据的多样性,你就可以用数据统计的方法设计一些。
提问:我的场景是日志分析,有很多信息,如用户名、用户名的操作方法,这样会产生很长的字符串,也有很短,那这部分数据怎么处理。
嘉宾女:给大家分享我们在公司内做项目或者做To B的项目遇到这些问题的思考路径,上述问题是两个方向,一个方向是怎样使得数据更干净,让我确定这个数据对我是否有价值;另外一个问题,这些数据拿到了怎样去应用。第一个问题,百度的已有数据用的是统一的格式,所以做一些标准和定义。第二个问题,这些数据怎么用,要想好你要解决的目的是什么,目标是什么,用我们掌握的技术和经验去变通找到方法。
提问:比如说95%提升到99%,提升了4%,提升的那4%具体体现的是什么?
赵乔:我们和客户合作是通过大量已有的功能仿生出来,在模型里跑。4%怎么算出来的,传统的是95%,我们拿着这4%,实际上就是0%。无法检测的数据拿过来,在这上面我们最后做到86%,所以综合下就是提升4%。
提问:诊断之后,故障的维护也是我们这边直接去完成?
赵乔:不是,我们做预警或者提前一天或者提前半天预警,但维护还是要人力做的。
提问:那我们现在这个诊断系统,同时可以处理多少个设备的诊断?
赵乔:目前因为我们在合作的客户实际上是负责了国家电网超过一半的充电桩,所以如果是说后续要增加的话,需要买更多的资源扩容,之所以是分布式系统,这是比传统系统的优势。
提问:我们现在存在多个设备需要诊断的话,诊断也是并发性的了?
赵乔:没错,刚才所说的这些模型很多是跑在端上的,对于云上的资源的依赖度没有那么大,只不过是把处理出来的数据在云上做监测,理论上来讲所有东西都跑在这里,所以对这一部分的压力不算很大。我们做一款硬件,实际上有类似于设备标签,如果用过MPD的话就专门针对这种标签进行设计的。
提问:这个产品已经在实际用了是吗?
赵乔:我们2月份在做,今年7月份在百度开发者大会上公布出来,因为这是个典型的To B的产品,不是To C的产品,不是天猫上可以卖,所以有To B的流程。我们给国家电网报了3万份的报备量,但是这里面还有一些没有解决的问题。之前提到的模型,我们现在只做了其中一部分,真实使用还有很多东西需要去做。
提问:在建模过程中,建模和深度学习的关系,是串联还是并联。
赵乔:我们当时做了两个算法比较,想看深度学习PaddlePaddle的结果,最终比较验证,这是并联关系,不是串联。
实录结束
赵乔,百度大数据部高级产品经理,负责百度工业大数据产品规划及项目落地。曾在华为、美国国家仪器从事产品、技术、销售工作,服务新能源、国防军工、汽车等典型制造业企业。