版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_17249717/article/details/82597055
以爬取腾讯新闻App新闻评论为例。
将手机用数据线连接上电脑,打开调试。
首先通过Charles抓包分析请求链接和响应的内容。
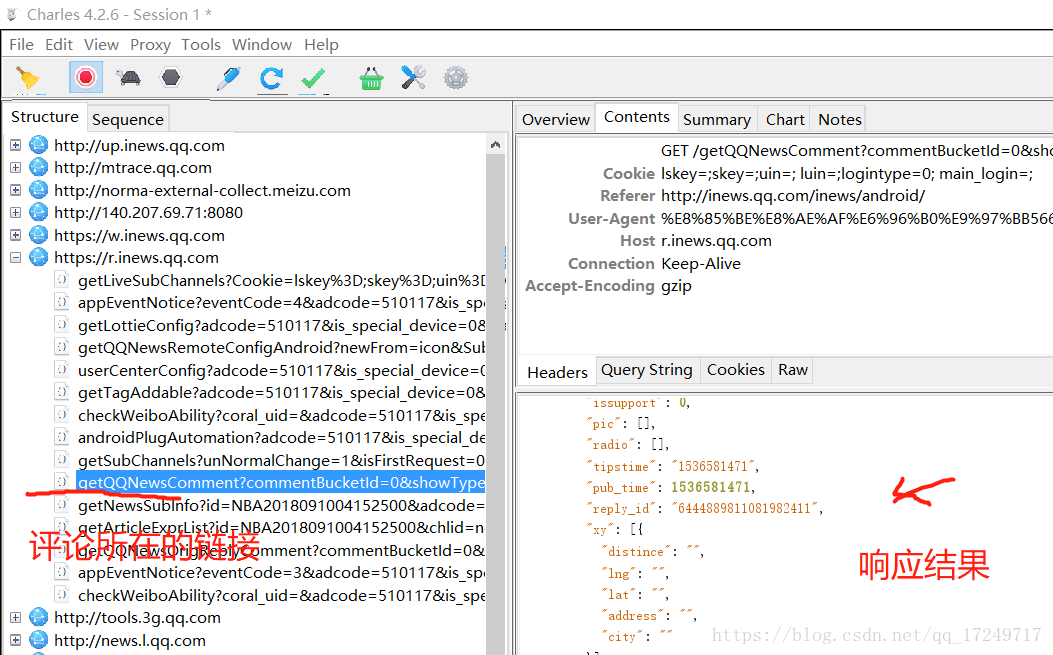
注意:腾讯新闻上的评论是嵌套字典的列表,我们需要进行处理,提取出列表中的字典。
代码展示
import time, json
def response(flow):
url = 'https://r.inews.qq.com/getQQNewsComment?' # 评论所在的链接(较完整)
if url in flow.request.url:
text = flow.response.text
data = json.loads(text)
# 从Charles中观测,data是个列表对象,列表对象是没有get()方法的,因此需提取出字典
data = data.get('comments').get('new')
if data: # 判断对象是否为空,data是评论集,包含多个评论
for item in data: # 处理每一条评论,此时item是列表
item = item[0] # 将列表转化为字典,从Charles中观测为嵌套字典的列表
# 获取评论的信息
nick = item.get('nick') # 昵称
agree = item.get('agree_count') # 点赞数
sex = item.get('sex') # 性别
reply_num = item.get('reply_num') # 互动数
city = item.get('province_city') # 所在城市
comment = item.get('reply_content') # 评论
# 时间戳的转换
date = time.strftime("%Y-%m-%d", time.localtime(item.get('pub_time')))
print(nick, agree, reply_num, sex, city, comment, date)
# 获取子评论
data = item.get('reply_list') # 嵌套字典的列表,包含多个子评论
if data: # 判断对象是否为空,data是子评论集,包含多个子评论
for item2 in data:
item2 = item2[0] # 提取出字典
reply_date = time.strftime("%Y-%m-%d", time.localtime(item2.get('pub_time')))
reply_nick = item2.get('nick')
reply_agree = item2.get('agree_count')
reply_sex = item2.get('sex')
reply_city = item2.get('province_city')
reply_comment = item2.get('reply_content')
print(reply_date, reply_nick, reply_agree, reply_sex, reply_city, reply_comment)在py文件所在的文件目录中,按住shift键,鼠标点击右键,选择“在此处打开shell窗口”。
输入mitmdump -s file.py,在App上不断地下滑,就会打印输出所需内容。