以前都是在网页上抓取数据,很少在手机App中抓取数据,那如何在抓取手机App中的数据呢?一般我们都是使用抓包工具来抓取数据.
常用的抓包工具有Fiddles与Charles,以及其它今天我这里主要说说Charles使用,相比于Fiddles,Charles功能更强大,而且更容易使用. 所以一般抓包我推荐使用Charles
下载与安装Charles
下载并安装Charles 再去破解Charles,这里附上文章教程,我就不多说啥了
https://www.cnblogs.com/rrl92/p/7928770.html
注意事项:
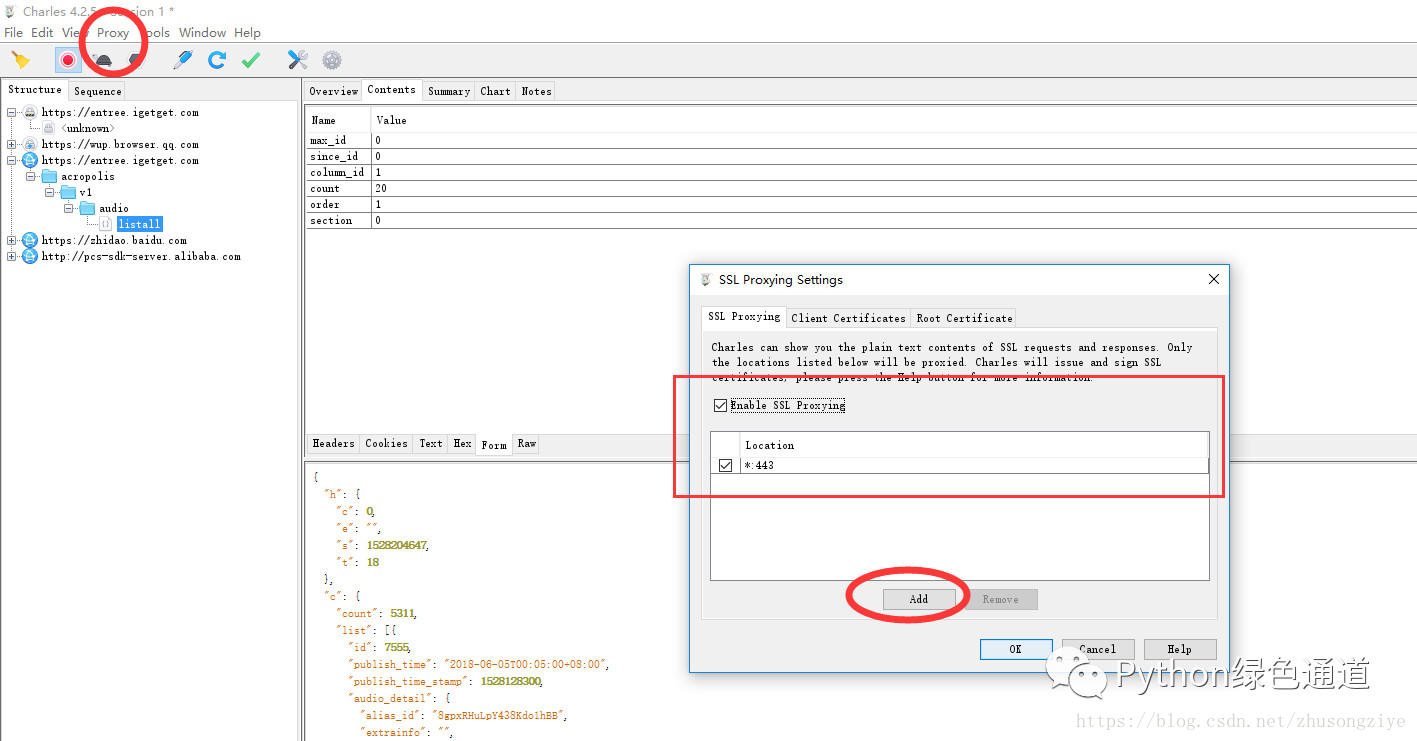
如果获取到的数据是乱码,你要设置一下连接SSL证书 在Charles中 菜单栏==>proxy==>SSL Proxying Settings ==>添加443,如上图所示. 然后当你在真正抓取数据的时候,记得把这个关掉,以免取不到数据
使用Charles
这里我直接放两张图让大家使用看看就明白了
我们一起来分析项目.
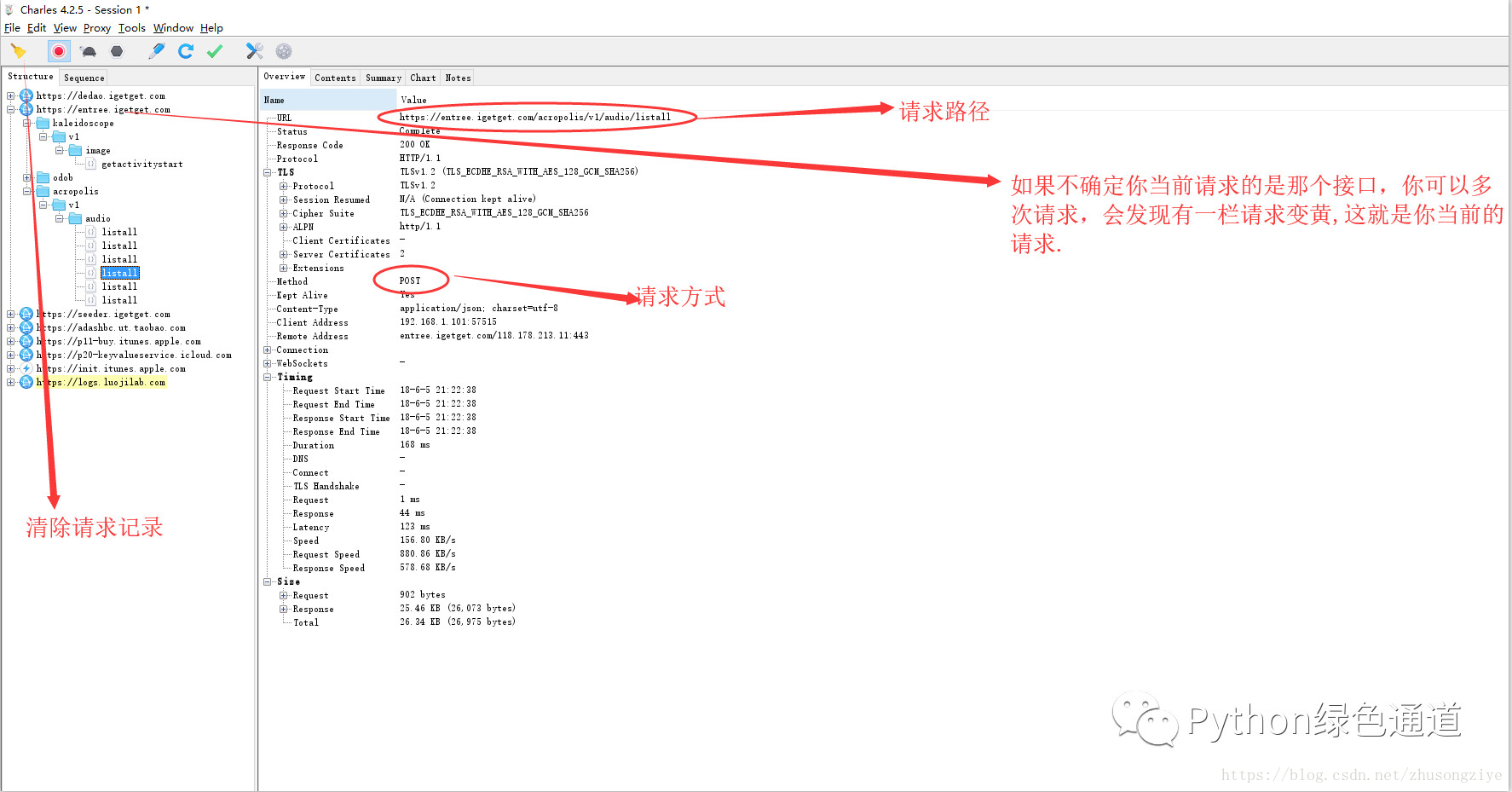
打开Charles 然后打开手机,得到App,进入逻辑思维栏目. 多次刷新App, 在Charles中 Structure中有变黄的一项就是我们当前的请求,
查看右边的Overview栏目,这里我们很容易发现我们的请求路径,状态,以及请求方式
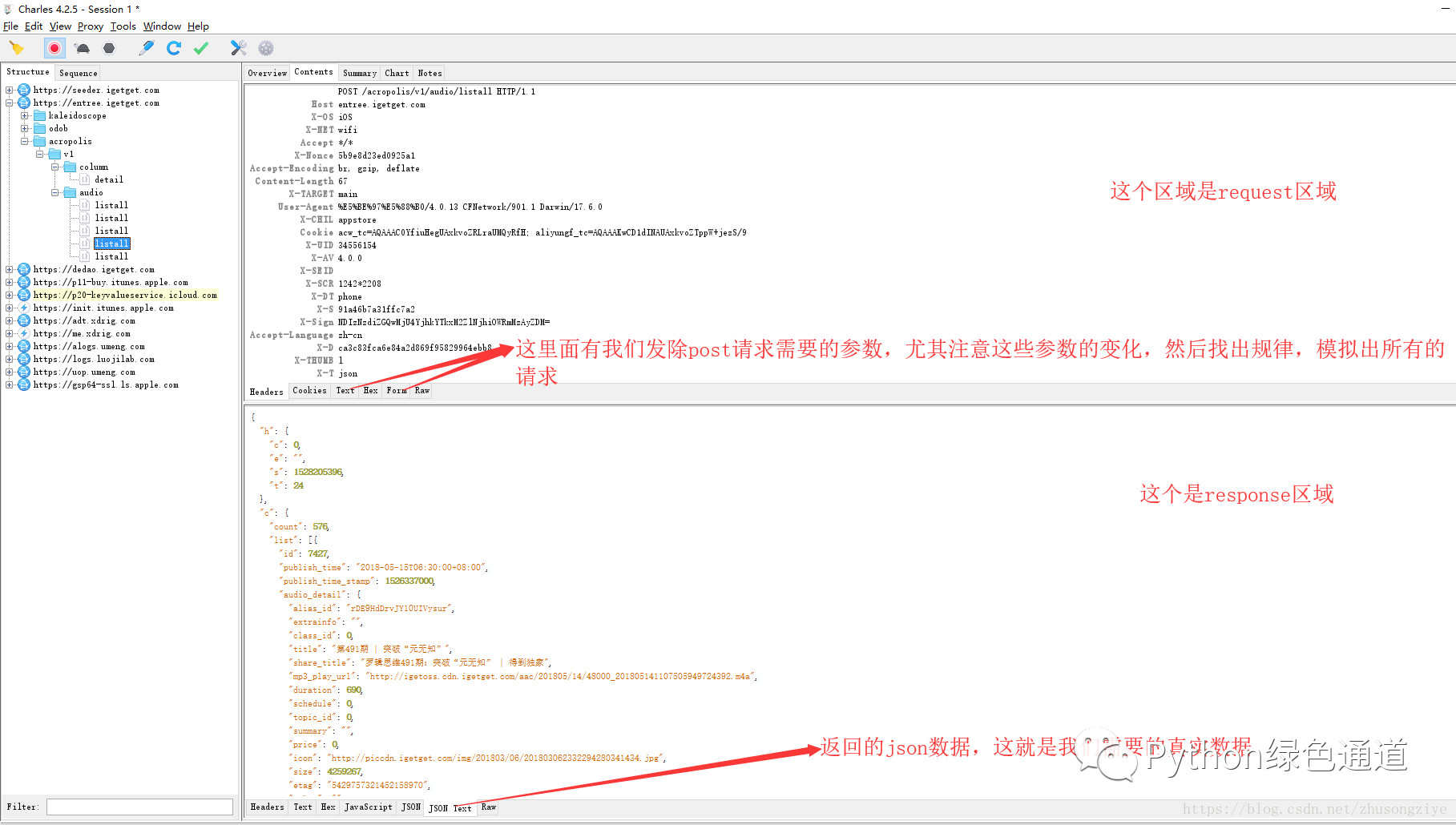
点击Contents栏目,上面是Requests区域,下面是Response区域. 可以看到上面的Headers 这里就是我们实际写代码时候要用到的Headers,** 注意构造Heaers时,不要出现了空格,我刚刚就犯了这个错误**
再看Form栏目,这里是我们构造Post请求需要的一些参数,我们在请求的时候,注意这里面的数据变化,来找出数据请求的规律.
这里我找到的数据请求规律就是通过改变时间戳来获取数据.
我打算把获取的数据存入到execl中,并下载相关的音频.
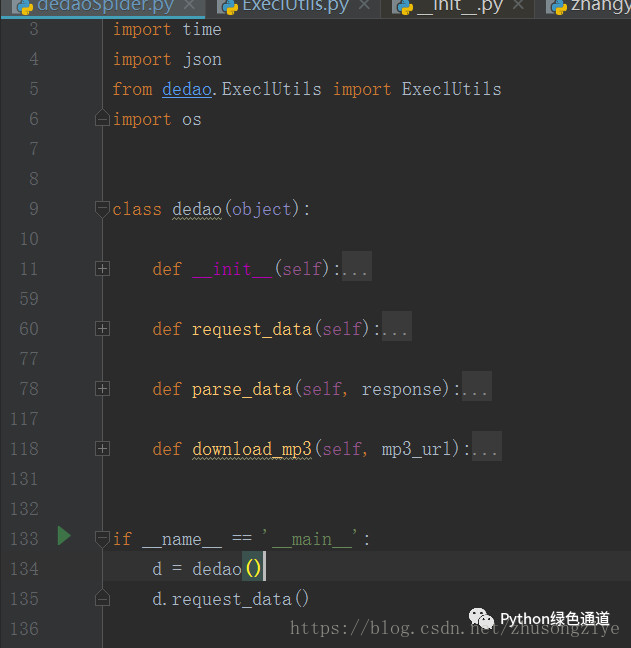
我们就开始来写代码. 定义一个
dedao类, 定义了三个方法request_data()parse_data()download_mp3()代码结构如下: 这里我强调一下,一定要先有大致的思路再去写代码,我这里定义了三个方法,我心中已经知道具体流程了.另外要注意一下,我能之前说了得到是通过时间戳来去请求下一页数据,那什么时候把数据请求完了呢,以及如何去请求下一页数据, 如果时间戳与我当前存的时间戳不一致,说明还有下一页数据,否则就是数据请求完了,具体代码如下:
# 这里有点递归的意味
max_id = datas[-1]['publish_time_stamp']
if self.max_id != max_id:
self.max_id = max_id
self.request_data()
else:
print('数据抓取完毕!')
完整代码:
import requests
import time
import json
from dedao.ExeclUtils import ExeclUtils
import os
class dedao(object):
def __init__(self):
# self.rows_title = [u'招聘标题', u'公司名称', u'公司地址', u'待遇', u'发布日期', u'招聘链接', u'招聘要求描述']
# sheet_name = u'51job_Python招聘'
self.rows_title = [u'来源目录', u'标题', u'图片', u'分享标题', u'mp3地址', u'音频时长', u'文件大小']
sheet_name = u'逻辑思维音频'
return_execl = ExeclUtils.create_execl(sheet_name, self.rows_title)
self.execl_f = return_execl[0]
self.sheet_table = return_execl[1]
self.audio_info = [] # 存放每一条数据中的各元素,
self.count = 0 # 数据插入从1开始的
self.base_url = 'https://entree.igetget.com/acropolis/v1/audio/listall'
self.max_id = 0
self.headers = {
'Host': 'entree.igetget.com',
'X-OS': 'iOS',
'X-NET': 'wifi',
'Accept': '*/*',
'X-Nonce': '779b79d1d51d43fa',
'Accept-Encoding': 'br, gzip, deflate',
# 'Content-Length': ' 67',
'X-TARGET': 'main',
'User-Agent': '%E5%BE%97%E5%88%B0/4.0.13 CFNetwork/901.1 Darwin/17.6.0',
'X-CHIL': 'appstore',
'Cookie ': 'acw_tc=AQAAAC0YfiuHegUAxkvoZRLraUMQyRfH; aliyungf_tc=AQAAAKwCD1dINAUAxkvoZTppW+jezS/9',
'X-UID': '34556154',
'X-AV ': '4.0.0',
'X-SEID ': '',
'X-SCR ': '1242*2208',
'X-DT': 'phone',
'X-S': '91a46b7a31ffc7a2',
'X-Sign': 'ZTBiZjQyNTI1OTU2MTgwZjYwMWRhMjc5ZjhmMGRlNGI=',
'Accept-Language': 'zh-cn',
'X-D': 'ca3c83fca6e84a2d869f95829964ebb8',
'X-THUMB': 'l',
'X-T': 'json',
'X-Timestamp': '1528195376',
'X-TS': '1528195376',
'X-U': '34556154',
'X-App-Key': 'ios-4.0.0',
'X-OV': '11.4',
'Connection': 'keep-alive',
'X-ADV': '1',
'Content-Type': 'application/x-www-form-urlencoded',
'X-V': '2',
'X-IS_JAILBREAK ': 'NO',
'X-DV': 'iPhone10,2',
}
def request_data(self):
try:
data = {
'max_id': self.max_id,
'since_id': 0,
'column_id': 2,
'count': 20,
'order': 1,
'section': 0
}
response = requests.post(self.base_url, headers=self.headers, data=data)
if 200 == response.status_code:
self.parse_data(response)
except Exception as e:
print(e)
time.sleep(2)
pass
def parse_data(self, response):
dict_json = json.loads(response.text)
datas = dict_json['c']['list'] # 这里取得数据列表
# print(datas)
for data in datas:
source_name = data['audio_detail']['source_name']
title = data['audio_detail']['title']
icon = data['audio_detail']['icon']
share_title = data['audio_detail']['share_title']
mp3_url = data['audio_detail']['mp3_play_url']
duction = str(data['audio_detail']['duration']) + '秒'
size = data['audio_detail']['size'] / (1000 * 1000)
size = '%.2fM' % size
self.download_mp3(mp3_url)
self.audio_info.append(source_name)
self.audio_info.append(title)
self.audio_info.append(icon)
self.audio_info.append(share_title)
self.audio_info.append(mp3_url)
self.audio_info.append(duction)
self.audio_info.append(size)
self.count = self.count + 1
ExeclUtils.write_execl(self.execl_f, self.sheet_table, self.count, self.audio_info, u'逻辑思维音频.xlsx')
print('采集了{}条数据'.format(self.count))
# 清空集合,为再次存放数据做准备
self.audio_info = []
time.sleep(3) # 不要请求太快, 小心查水表
max_id = datas[-1]['publish_time_stamp']
if self.max_id != max_id:
self.max_id = max_id
self.request_data()
else:
print('数据抓取完毕!')
pass
def download_mp3(self, mp3_url):
try:
# 补全文件目录
mp3_path = u'D:/store/mp3/{}'.format(mp3_url.split('/')[-1])
print(mp3_path)
# 判断文件是否存在。
if not os.path.exists(mp3_path):
# 注意这里是写入文件,要用二进制格式写入。
with open(mp3_path, 'wb') as f:
f.write(requests.get(mp3_url).content)
except Exception as e:
print(e)
if __name__ == '__main__':
d = dedao()
d.request_data()