版权声明:本文为博主原创文章,未经博主允许不得转载。博客地址:http://www.fanlegefan.com/ https://blog.csdn.net/woloqun/article/details/81902605
公司现有的hadoop集群空间快用完了,预计不久文件数将超过一个namenode支持上限(namenode支持的文件数和namenode内存大小有关,1G内存大约支持100w个文件),所以公司搭建了一套新的集群,采用Frederation架构来支持hadoop集群的水平扩展,原理上就是将hdfs元数据信息存储在多个namenode上,可以理解为分片,每个namenode分片又做了HA,集群拓扑图如下
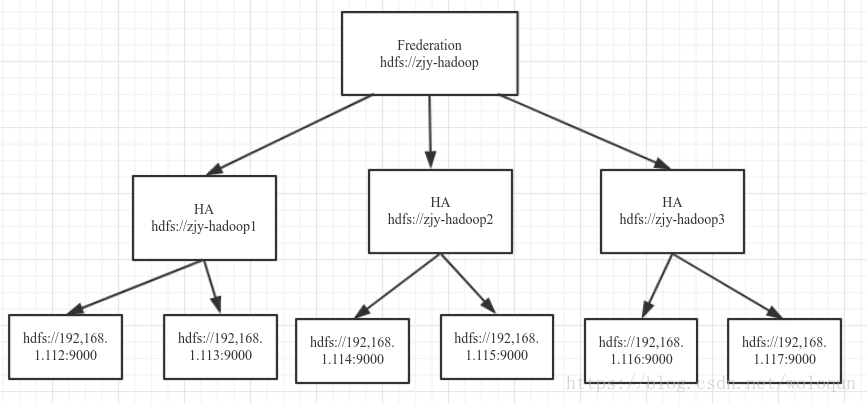
因为集群的迁移,所以之前搭建的hive仓库也要迁移;
仓库的迁移步骤:hdfs文件的迁移,元数据迁移,HADOOP_HOME变更,hiveserver和metastore重启
hdfs文件迁移
hdfs文件的迁移,方案很多,这里我们要求的是新旧集群的文件路径要求一致,例如:旧集群仓库地址hdfs://c3-hadoop/user/bigdata/warehouse,新集群的地址:hdfs://zjy-hadoop/user/bigdata/warehouse,这样做的主要目的是为了方便元数据修改
元数据迁移
大部分hive数据仓库的元数据都会保存在mysql中,这里的元数据,可以理解为hive表的描述信息,例如:表字段,序列化方式,文件存储路径;
元数据的迁移,其实就是修改之前hive表的文件存储路径(字段,序列化等信息不会变),以及hive 库的路径,修改也倒是很简单
update SDS set LOCATION =replace(LOCATION,'c3-hadoop','zjy-hadoop');
update DBS set DB_LOCATION_URI =replace(DB_LOCATION_URI,'c3-hadoop','zjy-hadoop');HADOOP_HOME变更
hive依赖HADOOP_HOME环境,所以HADOOP_HOME需要从c3-hadoop切换到zjy-hadoop
hiveserver && hivemetastore重启
重启这两个服务,仓库切换就完成了