数据挖掘的特点:
第一,数据挖掘的数据源必须是真实的。而不是为了进行数据分析而专门收集的数据。
第二,数据挖掘所处理的数据必须是海量的。
第三,查询一般是决策制定者(用户)提出的随机查询。
第四,挖掘出来的知识一般是不能预知的,数据挖掘发现的是潜在的、新颖的知识。
Knowledge Discovery from Database的简称是KDD,数据挖掘只是KDD的一个步骤。
KDD的主要步骤如下:
1.数据集成,指的将多种数据源组合在一起;
2.数据清洁,指的消除噪音或不一致的数据;
3.数据选择,指的从数据库中提取与分析认为相关的数据的过程;
4.数据转换,通过汇总,聚集,降低维数等数据转换方法将数据统一成合适的挖掘形式,减少数据量,降低数据的复杂性;
5.数据挖掘,先确定挖掘任务,然后选择合适的工具,进行挖掘知识的操作;
6.模式评估,根据用户提供的指标,对挖掘出来的模式进行评估的过程;
7.知识表示,指的是使用可视化和知识表示技术,向用户提供容易理解的挖掘到的知识。
传统的数据库工具属于操作性工具;数据挖掘属于分析型工具。
对于分类分析有决策树算法,贝叶斯算法,人工神经网络等。
数据挖掘算法都是由5个标准组件构成:模型或模式结构,数据挖掘任务,评分函数,搜索和优化方法,数据管理策略。
模型是对整个数据集的高层次,全局性的描述或总结。
模式是局部的,仅对一小部分数据做出描述。
挖掘任务分为模式挖掘,预测建模,描述建模等。
数据挖掘是从大量数据中发现潜在的知识,不需要用户提出确切的问题。OLAP是联机分析处理,它根据用户提出的问题,深入提取关于该问题的详细信息,并展示给用户。
分类和回归被称为预测建模,目的是建立一个模型,该模型允许人们根据已知的属性值来预测其他某个未知的属性值。当预测的属性是范畴型称为分类,是数量型时称为回归。
决策树分类属于判别模型,用于确定各个类别的决策区域,是一个分层的多叉树结构。
决策树分类分为两步,第一步利用训练集建立一颗决策树,得到一个决策树分类模型;第二步利用生成的决策树对输入数据进行分类。
不考虑任何输入辩论,任一样本需要的信息是:
info(T) = -∑pilog2(pi) 其中i是下标,∑的下标也是从i开始,求和。
如果输入某个变量x,任一样本所属类别需要的信息为:info(X,T)=∑Ti/Tinfo(Ti) 其中Ti表示任一样本所属的类别需要的信息,T是总数量。
计算信息增益为Gain(X,T)=Info(T) - Info(X,T);根据信息增益的大小对输入变量进行排序,优先使用信息增益量大的变量,也就是说熵的值越小,优先度越高。
1.决策树分类第一步:选择属性,作为树根;
2.剪枝阶段;主要分为两类先剪和后剪;
先剪:训练时间开销降低,测试时间开销降低;过拟合风险降低,欠拟合风险增加
• 后剪:训练时间开销增加,测试时间开销降低;过拟合风险降低,欠拟合风险基本不变
后剪 通常优于 先剪。
贝叶斯分类是一种典型的统计学分类方法,用来预测诸如某个样本属于某个分类的概率有多大。
贝叶斯公式P(B|A) = P(A|B) * P(B) / P(A)或P(B|A) = P(AB) / P(A)
用于机器学习。
应用场景如:拼写纠正,垃圾邮件过滤等。
若某个属性值在训练集中没有与某个类同时出现过,则直接计算会出现问题,因为概率连乘将“抹去”其他属性提供的信息。

其中先验概率的公式就是指贝叶斯公式
朴素贝叶斯分类法假定属性值之间是互相独立的。
朴素贝叶斯分类器的使用:
若对预测速度要求高,预计算所有概率估值,使用时“查表”
若数据更替频繁,不进行任何训练,收到预测请求时再估值;
若数据不断增加,基于现有估值,对新样本涉及的概率估值进行修正。

贝叶斯信念网络允许属性间存在依赖关系,用一个有向无环图来表示,每个结点代表一个随机变量(状态),每条弧代表一个概率依赖 (状态间的因果关系),每个状态只与它直接相连的状态有关,与间接相连的状态没有直接联系(但有间接相关性)。
支持向量机分类support vector machine 简称svm优点准确性高,模型描述简单;缺点是训练时间长。
支持向量机分类主要用来解决二元分类问题(数据最多只属于两个不同的类别)。
正平面:wx1 + b = 1;
负平面:wx2 + b = -1;
正平面和负平面的距离为M;
x1 = x2 + aw;
|x1 - x2| = m;
当原本的样本空间中无法找到一个最优的线性分类函数时,可以考虑利用非线性变化的方法,将原样本空间的非线性问题转化成另一个高维空间中的线性问题。
支持向量机比较适合于规模小的数据集,如果是大量数据集,一般先将问题分解成多个小的子问题,然后再应用支持向量机方法解决子问题。
神经网络有三个要素:拓扑结构、连接方式、学习规则。
人工神经网络由一组相连接的神经元组成。神经元可以看作是一个多输入,单输出的信息处理单元。神经元之间的每个连接都有一个权值与之相连。神经网络的学习就是通过迭代算法对权值逐步修改的优化过程。

最流行的基于神经网络的分类算法是80年代提出的后向传播算法。
后向传播算法分为如下几步:
1.初始化权;
2.向前传播输入 ;
3.向后传播误差。
神经网络模型中包括输入单元层,中间层(也称为隐藏层,可以为多层),输出单元层。
后向传播算法学习过程:迭代地处理一组训练样本,将每个样本的网络预测与实际的类标号比较。
每次迭代后,修改权值,使得网络预测和实际类之间的均方差最小。


初始化权
网络的权通常被初始化为很小的随机数(例如,范围从-1.0到1.0,或从-0.5到0.5)。
每个单元都设有一个偏置(bias),偏置也被初始化为小随机数。
卷积神经网络是一种多层神经网络,擅长处理图像特别是大图像的相关机器学习问题。
卷积网络通过一系列方法,成功将数据量庞大的图像识别问题不断降维,最终使其能够被训练。
由输入层、卷积层、激活函数、池化层、全连接层组成。其中卷积层与池化层配合,组成多个卷积组,逐层提取特征,最终通过若干个全连接层完成分类。
卷积:在原始的输入上进行特征的提取。
计算过程



第四步,滑动窗口2个步长,重复之前步骤进行计算
第五步,最终可以得到,在2个filter下,卷积后生成的深度为2的输出结果。
①为什么每次滑动是2个格子?
滑动的步长叫stride记为S。S越小,提取的特征越多,但是S一般不取1,主要考虑时间效率的问题。S也不能太大,否则会漏掉图像上的信息。
②由于filter的边长大于S,会造成每次移动滑窗后有交集部分,交集部分意味着多次提取特征,尤其表现在图像的中间区域提取次数较多,边缘部分提取次数较少,怎么办?
一般方法是在图像外围加一圈0,细心的同学可能已经注意到了,在演示案例中已经加上这一圈0了,即+pad 1。 +pad n表示加n圈0.

③一次卷积后的输出特征图的尺寸是多少呢?

聚类分析:根据数据的特征找出数据间的相似性,将相似的数据分成一个类。
数据矩阵经常被称为二模(two-mode)矩阵,而相异度矩阵被称为单模(one-mode)矩阵。这是因为前者的行和列代表不同的实体,而后者的行和列代表相同的实体。
许多聚类算法以相异度矩阵为基础。如果数据是用数据矩阵的形式表现的,在使用该类算法之前要将其转化为相异度矩阵。
为了实现度量值的标准化,一种方法是将原来的度量值转换为无单位的值。
对象间的相异度(或相似度)是基于对象间的距离来计算的 ,通常使用明考斯基距离
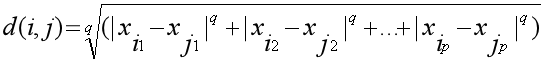
其中i = (xi1, xi2, …, xip) ,j = (xj1, xj2, …, xjp) 分别代表两个p-维的对象, q是一个正整数
q = 1的时候,d称为曼哈顿距离
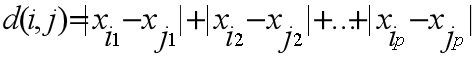
当q =2表示欧几里得距离
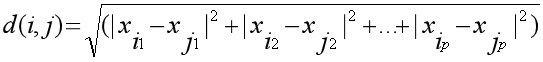
距离函数具有如下属性:
1.d(i,j)≥0:距离是一个非负的数值。
2.d(i,i)=0:一个对象与自身的距离是0。
3.d(i,j)= d(j,i):距离函数具有对称性。
4.d(i,j)≤ d(i,h)+d(h,j):从对象I到对象j的直接距离不会大于途径任何其他对象的距离。
二元变量只有两个状态:0或1
0表示该变量为空
1表示该变量存在
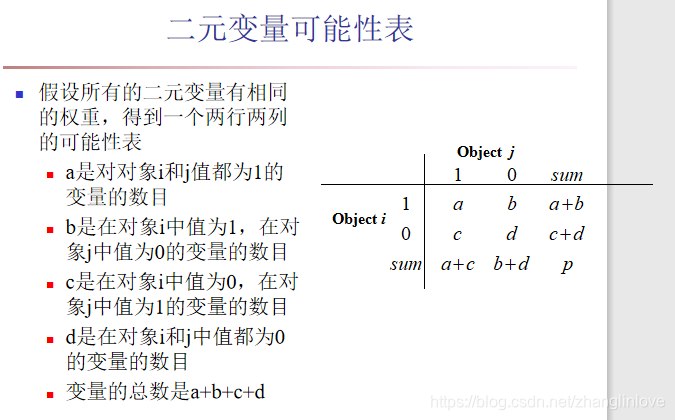
二元变量的两个状态有相同的权重, 那么该二元变量是对称的,也就是两个取值0或1没有优先权
两个对象i和j之间相异度的最著名的系数是简单匹配系数,其定义如下:
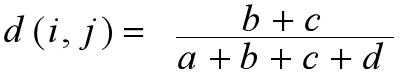
如果两个状态的输出不是同样重要,那么该二元变量是不对称的。我们将比较重要的输出结果,通常也是出现几率较小的结果编码为1,而将另一种结果编码为0,将两种都取0的状态忽略掉。
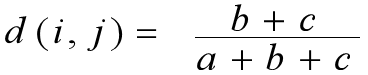
b表示i为1,j为0的个数 c表示i为0,j为1的个数 a表示i、j同为1的个数
设有X={1,0,0,0,1,0,1,1},Y={0,0,0,1,1,1,1,1},可以看到,两个元素第2、3、5、7和8个属性取值相同,而第1、4和6个取值不同,那么相异度可以标识为3/8=0.375。一般的,对于二元变量,相异度可用“取值不同的同位属性数/单个元素的属性位数”标识。
就是我们只关心两者都取1的情况,而认为两者都取0的属性并不意味着两者更相似。在这种情况下,改用“取值不同的同位属性数/(单个元素的属性位数-同取0的位数)”来标识相异度,这叫做非对称二元相异度。
标称变量是二元变量的推广,它可以具有多于两个的状态值。
假设一个标称变量的状态数目是M。这些状态可以用字母,符号,或者一组整数(如1,2,…,M)来表示。
两个对象i和j之间的相异度可以用简单匹配方法来计算:
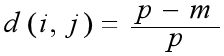
其中m是匹配的数目,即i和j取值相同的变量的数目;而 p是全部变量的数目。
聚类算法的优点:1.能够处理各种数据类型;2.处理各种形状的数据分布;3.不需要太多的输入参数;4.能够处理噪音数据;5.与数据的输入顺序无关;6.具有可解释性和使用性;7.具有可扩展性。
K-means算法
给定一个数据集合X和一个整数K(n),K-Means方法是将X分成K个聚类,就是通过计算不同样本间的距离来判断他们的相近关系的,相近的就会放到同一个类别中去。
K-Means聚类方法分为以下几步:
[1] 给K个cluster选择最初的中心点,称为K个Means。
[2] 计算每个对象和每个中心点之间的距离。
[3] 把每个对象分配给距它最近的中心点做属的cluster。
[4] 重新计算每个cluster的中心点。
[5] 重复2,3,4步,直到算法收敛。
