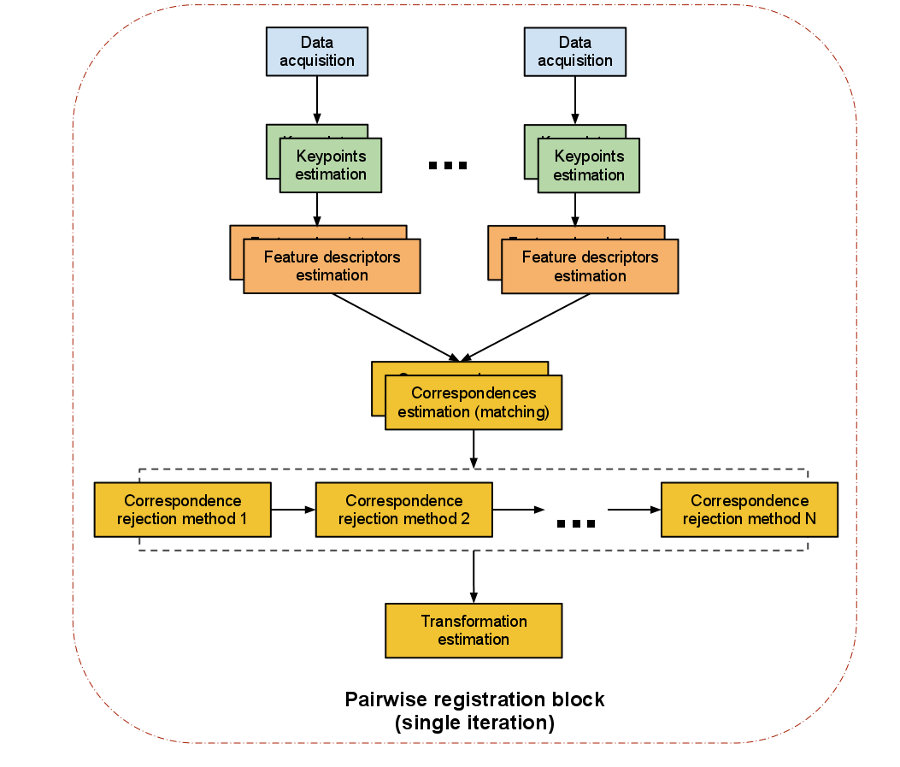
The computational steps for two datasets are straightforward:
- from a set of points, identify interest points (i.e., keypoints) that best represent the scene in both datasets;
- at each keypoint, compute a feature descriptor;
- from the set of feature descriptors together with their XYZ positions in the two datasets, estimate a set of correspondences, based on the similarities between features and positions;
- given that the data is assumed to be noisy, not all correspondences are valid, so reject those bad correspondences that contribute negatively to the registration process;
- from the remaining set of good correspondences, estimate a motion transformation.