理论:
很多查找算法是通过利用关于项在集合中相对余彼此存储的位置的信息,改进搜索算法
建立一个可以在O(1)时间内被搜索的数据结构--> Hash查找
哈希表是以一种容易找到它们的方式存储项的集合,哈希表的每个位置,通常称为一个槽,可以容纳一个项,并且由从0开始的整数值命名,例如有名为0的槽,名为1的槽......,最初,哈希表不包含项,因此每个槽为空,我们可以通过一个列表来实现哈希表每个元素初始化为none
项和该项在散列表中所属的槽之间的映射被称为hash函数。hash函数将接受集合中的任何项,并在槽名范围内(0~m-1之间)返回一个整数
hash函数:
余数法:只需要一个项并将其除以表大小,返回剩余部分作为其散列值(h(item) = item % 11(槽的大小)) 结果必在槽名的范围内
一旦计算了哈希值,我们可以将每个项插入到指定位置的哈希表中
给定项的集合,将每个项映射到唯一槽的散列函数被称为完美散列函数,总是具有完美散列函数的一种方式就是增加散列表的大小,使得可以容纳项范围中的每个可能值
很多扩展简单余数法:
1、分组求和法
2、平方取中法
3、基于字符的项创建哈希函数 如:ord('c') == 99
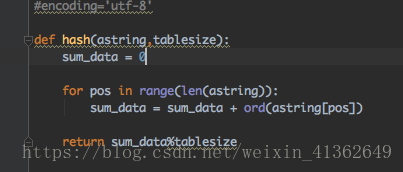
哈希函数必须是高效的,以便它不会成为存储和搜索过程的主要部分;如果哈希函数太复杂,则计算槽名称的程序要比顺序查找和二分查找更耗时时,将打破散列的目的。
哈希冲突
当两个项散列到同一个槽时,我们必须用一个系统的方法将第二项放在散列表中,这个过程称为冲突解决
1、解决冲突的一种方法是查找散列表,尝试查找另一个空槽以保存导致冲突的项,一个简单的方法是从原始哈西值位置开始,然后以顺序方式移动槽,直到遇到第一个空槽。我们可能回到第一个槽来查找整个散列表(循环),这种冲突解决的过程被称为开放寻址,因为他试图在三列表中找到下一个空槽或地址。通过系统地一次访问每个槽,我们执行称为线性探测的开放寻址技术
在冲突之后寻找另一个槽的过程叫重新散列,使用简单的线性探测,reshape函数是newhashvalue = rehash(oldhashvalue),一般来说reshape(pos) = (pos + skip)%sizeoftable 注意:skip跳过的大小必须使得表中的所有槽最终都被访问,否则,表的一部分将不被使用,通常建议表大小是素数
2、用于处理冲突问题的替代放大是允许每个槽保持对项的集合(或链)的引用
哈希查找代码实现:
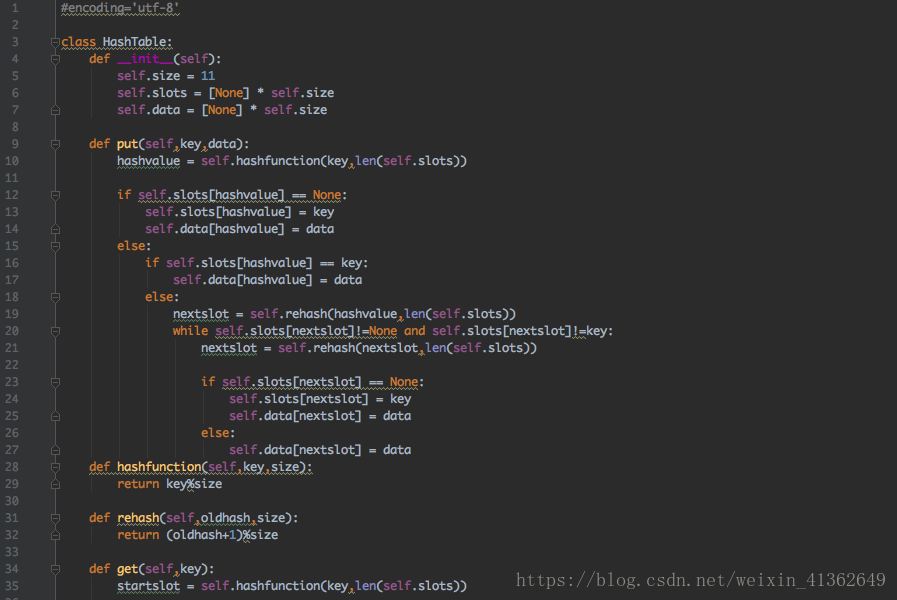
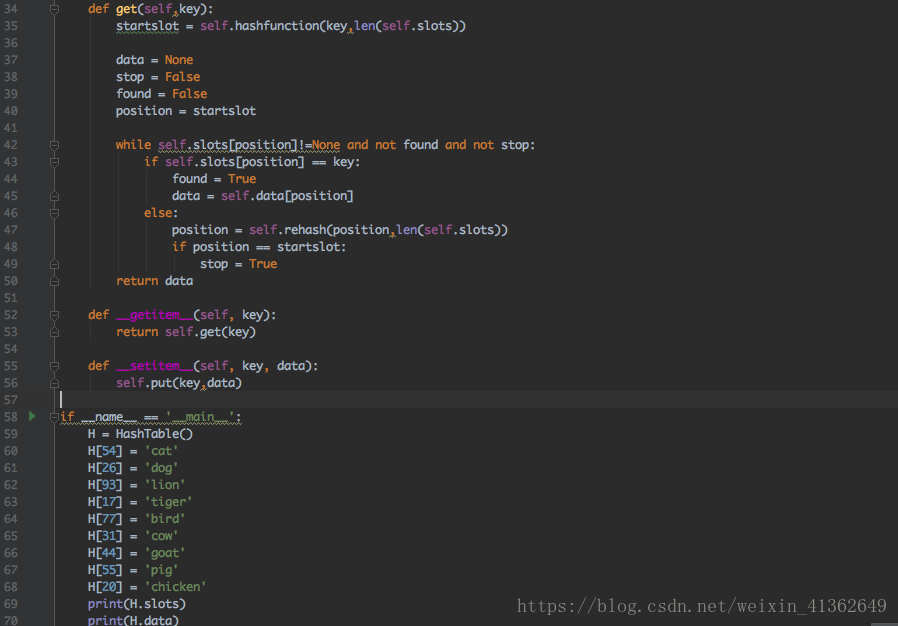
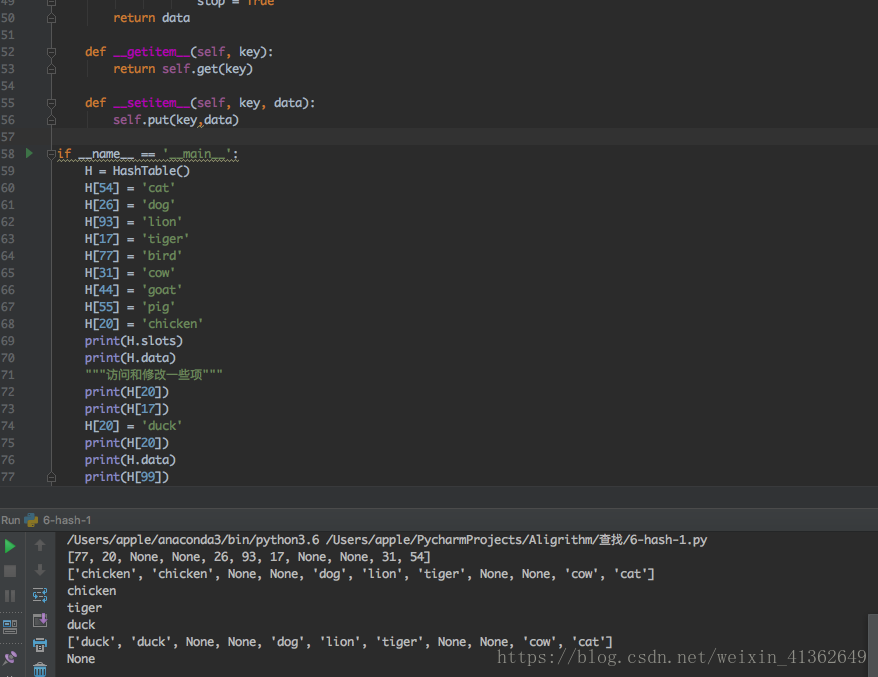
最好的情况下,散列将提供O(1),恒定时间搜索,但是,由于冲突,往往分析比较复杂