We are going to explain how join works in MR , we will focus on reduce side join and map side join.
Reduce Side Join
Assuming we have 2 datasets , one is user information(id, name...) , the other is comments made by users(user id, content, date...). We want to join the 2 datasets to select the username and comment they posted. So, this is a typical join example. You can implement all types of join including innter join/outer join/full outer join... As the name indicates, the join is done in reducer.
- We use 2/n mappers for each dataset(table in RDBMS). So, we set this with code below.
1 MultipleInputs.addInputPath(job,filePath,TextInputFormat.class,UserMapper.class) 2 MultipleInputs.addInputPath(job,filePath,TextInputFormat.class,CommentsMapper.class)
3 ....
4 MultipleInputs.addInputPath(job,filePath,TextInputFormat.class,OtherMapper.class)
.... - In each mapper, we just need to output the key/value pairs as the job is most done in reducer. In reduce function, when it iterators the values for a given key, reduce function needs to know the value is from which dataset to perform the join. Reducer itself may not be able to distinguish which value is from which mapper(UserMapper or CommentsMapper) for a given key. So, in the map function, we have a chance to mark the value like prefix the value with the mapper name something like that.
1 outkey.set(userId); 2 //mark this value so reduce function knows 3 outvalue.set("UserMapper"+value.toString); 4 context.write(outkey,outvalue)
- In reducer, we get the join type from configuration, perform the join. there can be multiple reducers and with multiple threads.
1 public void setup(Context context){ 2 joinType = context.getConfiguration().get("joinType"); 3 } 5 public void reduce(Text text, Iterable<Text> values, Context context) 6 throws Exception { 7 listUser.clear(); 8 listComments.clear(); 9 for (Text t: values){ 10 if(isFromUserMapper(t)){ 11 listUser.add(realContent(t)); 12 }else if (isFromCommentsMapper(t)){ 13 listUser.add(realContent(t)); 14 } 15 } 16 doJoin(context); 17 } 19 private void doJoin(Context context) throws Exception{ 20 if (joinType.equals("inner")){ 21 if(both are not empty){ 22 for (Text user:listUser){ 23 for (Text comm: listComments){ 24 context.write(user,comm); 25 } 26 } 27 } 29 }else if (){ 30 }..... 31 }
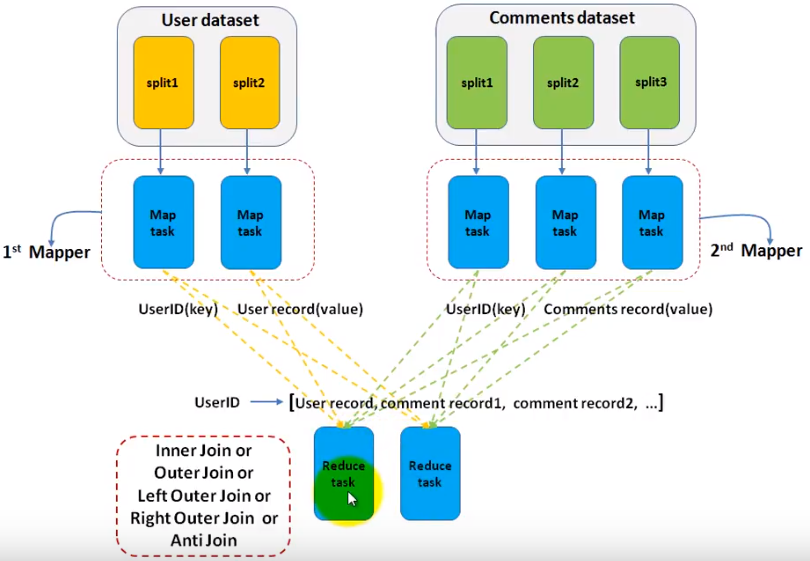
In reducer side join, all data will be sent to reducer side, so, the overall network bandwith is required.
Map Side Join/Replicated Join
As the name indicates , the join operation is done in map side . So, there is no reducer. It is very suitable for join datasets which has only 1 large dataset and others are small dataset and can be read into small memory in a single machine. It is faster than reduce side join (as no reduce phase, no intermediate output, no network transfer)
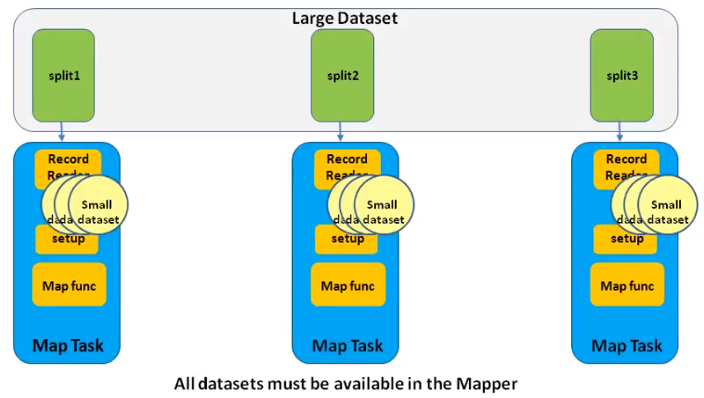
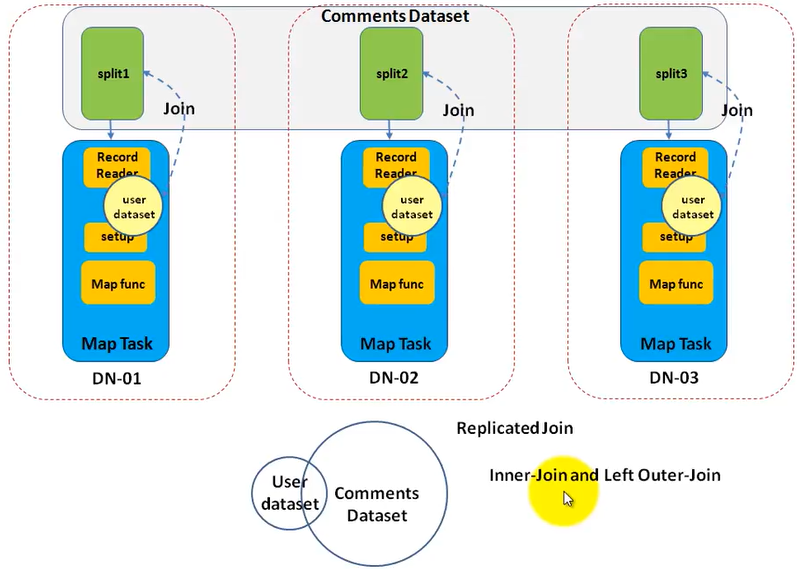
We still use the sample example that is to join user(small) and comments(large) datasets. How to implement it?
- Set the number of reduce to 0.
job.setNumReduceTasks(0);
- Add the small datasets to hadoop distribute cache.The first one is deprecated.
1 DistributedCache.addCacheFile(new Path(args[0]).toUri(),job.getConfiguration) 2 job.addCacheFile(new Path(filename).toUri());
- In mapper setup function, get the cache by code below. The first one is deprecated. Read the file and put the the key / value in an instance variable like HashMap. This is single thread, so it is safe.
Path[] localPaths = context.getLocalCacheFiles();
URI[] uris = context.getCacheFiles()
- In the mapper function, since, you have the entire user data set in the HashMap, you can try to get the key(comes from the split of comment dataset) from the HashMap. If it exists, you get a match. Because only one split of comments dataset goes into each mapper task, you can only perform an inner join or a left outer join.
What is Hadoop Distributed Cache?
"DistributedCache is a facility provided by the Map-Reduce framework to cache files needed by applications. Once you cache a file for your job, hadoop framework will make it available on(or broadcast to) each and every data nodes (in file system, not in memory) where you map/reduce tasks are running. Then you can access the cache file as local file in your Mapper Or Reducer job. Now you can easily read the cache file and populate some collection (e.g Array, Hashmap etc.) in your code" The cache will be removed once the job is done as they are temporary files.
The size of the cache can be configured in mapred-site.xml.
How to use Distributed Cache(the API has changed)?
- Add cache in driver.
Note the # sign in the URI. Before it, you specify the absolute data path in HDFS. After it, you set a name(symlink) to specify the local file path in your mapper/reducer.
1 job.addCacheFile(new URI("/user/ricky/user.txt#user")); 2 job.addCacheFile(new URI("/user/ricky/org.txt#org")); 3 4 return job.waitForCompletion(true) ? 0 : 1;
- Read cache in your task(mapper/reduce), probably in setup function.
1 @Override 2 protected void setup( 3 Mapper<LongWritable, Text, Text, Text>.Context context) 4 throws IOException, InterruptedException { 5 if (context.getCacheFiles() != null 6 && context.getCacheFiles().length > 0) { 7 8 File some_file = new File("user"); 9 File other_file = new File("org"); 10 } 11 super.setup(context); 12 }
Reference:
https://www.youtube.com/user/pramodnarayana/videos
https://stackoverflow.com/questions/19678412/number-of-mappers-and-reducers-what-it-means