Top 10 IDs base on their value
First , we need to set the reduce to 1. For each map task, it is not a good idea to output each key/value pair. Instead, we can just output the top 10 IDs based on their value. So, less data will be written to disk and transferred to the reducer. If we need to get the top 10 for each mapper task, we need to iterator over the whole split. In map function, we collect each id/value, add it to the data structure that supports sorting like black-red tree, keep only the top 10. In the cleanup function, we output the result.
1 //hadoop code for map/reduce task , see the cleanup function. 2 public void run(Context context) throws IOException, InterruptedException { 3 setup(context); 4 try { 5 while (context.nextKey()) { 6 reduce(context.getCurrentKey(), context.getValues(), context); 7 } 8 } finally { 9 cleanup(context); 10 } 11 }
The map task below. the sorted IDs is written in cleanup function.

The reduce task has the similar logic.(Note: there is only 1 reducer)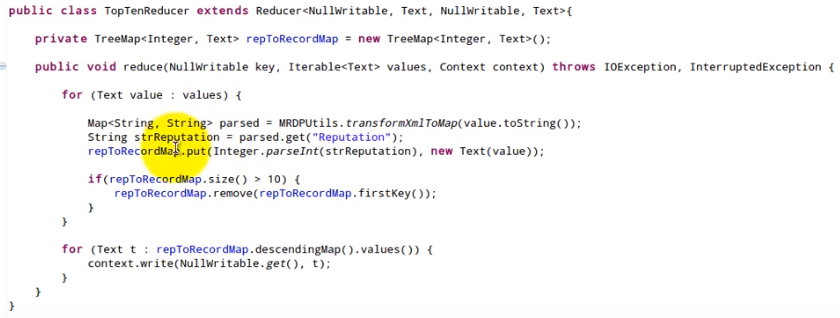
reference:https://www.youtube.com/watch?v=Bj6-maOjB8M