移动端AR的适用分析(二)
1. 单目SLAM难点
2. 视觉SLAM难点
3. 可能的解决思路
单目slam的障碍来自于理论和实践两个方面。理论障碍可以看做是固有的,无法通过硬件选型或软件算法来解决的,例如单目初始化和尺度问题。实践问题包括计算量,视野等,可以依靠选型、算法、软件设计等方法来优化。不过在同等硬件水平下,优化也存在极限的。比如对O(1)的算法不满意从而设计O(1/n)的算法似乎是不可能的……
1. 单目SLAM难点
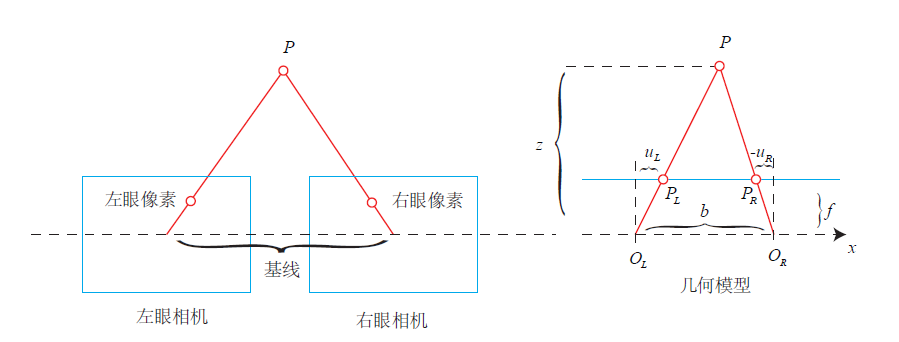
单目的优点是成本低,最大的局限性是测不到空间物体的距离,只有一个图像。所以早期视觉SLAM也被称为“只有角度的SLAM”(Bearing Only)。距离在定位中至关重要,双目和RGBD相机的使用就是为了能够计算(或测量)这个距离。上一个图你们直观体会一下距离的重要性:


很显然,没有距离信息,我们不知道一个东西的远近——所以也不知道它的大小。它可能是一个近处但很小的东西,也可能是一个远处但很大的东西。只有一张图像时,你没法知道物体的实际大小——我们称之为尺度(Scale)。
可以说,单目的局限性主要在于我们没法确定尺度,而在双目视觉、RGBD相机中,距离是可以被测量到的(当然测量也有一定的量程和精度限制)。双目视觉和人眼类似,通过左右眼图像的差异来计算距离——也就是所谓的立体视觉(Stereo)。RGBD则是把(通常是红外)光投射到物体表面,再测量反射的信息来计算距离的。具体原理分结构光和ToF两种,在此不多做解释,还是上图直观感受一下。
距离未知导致单目SLAM存在以下问题:
- 需要初始化
- 尺度不确定
- 尺度漂移
而一旦我们拥有了距离信息,上述几条就都不是问题,这也是双目和RGBD存在的意义。下面分别讲一下以上几条。
---------------我是分割线-----------------
1.1 初始化
单目SLAM刚开始时,只有图像间的信息,没有三维空间的信息。于是一个基本问题就是:怎么通过两张图像确定相机自身运动,并且确定像素点的距离。这个问题称为单目SLAM初始化问题。一般是通过匹配图像特征来完成的。匹配好的特征点给出了一组2D-2D像素点的对应关系,但由于是单目,没有距离信息。初始化的意义是求取两个图像间的运动和特征点距离,所以初始化完毕后你就知道这些特征点的3D位置了。后续的相机运动就可以通过3D点-2D点的匹配信息来估计。后续的问题叫PnP(Perspective n Point)。
对,你想的没错,单目的流程就是:初始化——PnP——PnP——……
初始化的运动是通过对极几何来求解的,结构是由三角测量得到的。初始化问题是一个2D-2D求运动和结构的问题,比3D-2D的PnP要难(信息更少,更不确定)。我不展开对极几何求运动的原理,但是理解它,对理解单目局限性是很有帮助的。如题主感兴趣,请看Multiple View Geometry第8章。如果在知乎上写,会占掉很大的篇幅。
1.2 运动问题
对极几何最终会分解一个本质矩阵(Essential Matrix)(或基本矩阵(Fundametal Matrix))来得到相机运动。但分解的结果中,你会发现对平移量乘以任意非零常数,仍满足对极约束。直观地说,把运动和场景同时放大任意倍数,单目相机仍会观察到同样的图像!这种做法在电影里很常见。例用用相机近距离拍摄建筑模型,影片看起来就像在真实的高楼大厦一样(比如奥特曼打怪兽实际是两个穿着特摄服装的演员,多么无情的现实)。
这个事实称为单目的尺度不确定性(Scale Ambiguity)。所以,我们会把初始化的平移当作单位1,而之后的运动和场景,都将以初始化时的平移为单位。然而这个单位具体是多少,我们不知道(摊手)。并且,在初始化分解本质矩阵时,平移和旋转是乘在一起的。如果初始化时只有旋转而没有平移,初始化就失败了——所以业界有种说法,叫做“看着一个人端相机的方式,就知道这个人有没有研究过SLAM”。有经验的人会尽量带平移,没经验的都是原地打转……
所以,从应用上来说,单目需要一个带平移的初始化过程,且存在尺度不确定问题,这是它理论上的障碍。
1.2 结构问题
由于单目没有距离信息,所有特征点在第一次出现时都只有一个2d投影,实际的位置可能出现在光心与投影连线的任意一处。只有在相机运动起来以后,才可能通过三角测量,估计特征点的距离。
1.3 尺度漂移
用单目估计出来的位移,与真实世界相差一个比例,叫做尺度。这个比例在初始化时确定,但单纯靠视觉无法确定这个比例到底有多大。进而,由于SLAM过程中噪声的影响,这个比♂例还不是固定不变的。当你用单目SLAM,会发现,咦怎么跑着跑着地图越来越小了
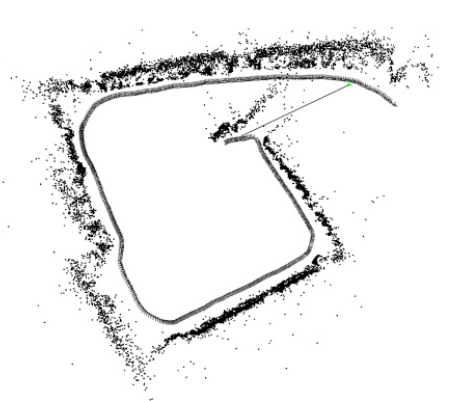
这种现象在当前state-of-the-art的单目开源方案出亦会出现,修正方法是通过回环检测。但是有没有出现回环,则要看实际的运动方式。所以……
2. 视觉SLAM的困难
双目相机和RGBD相机能够测量深度数据,于是就不存在初始化和尺度上的问题了。但是,整个视觉SLAM的应用中,存在一些共同的困难,主要包括以下几条:
1.手机处理速度
2.手机卷帘相机
3.人体移动速度
4.手机移动方向
5.多款相机参数难以统一(android)
目前市面上的android手机多种多样,硬件越来越强大,使用人数也是最多,同时也有前人经验将orb-SLAM2移植到手机上的经验,移植过的人因该都知道,使用的时候,加载词袋模型需要花费20s时间,变成二进制文件也是缓慢,然后出来效果是每秒11(记不太请),慢的可以,然后果断放弃了。
一个彻底的方式:
然后 开始在手机端重写几乎所有算法,框架仿照ORB-SLAM2,以用来更加容易的适用手机的所有的特性,若是想要达到实时效果或者稍有延迟,只有两种路可以选择 1,降低图像的采样率 2,增加手机处理速度,面对需要用在实际中的项目,只有采用谦前者,果断采用每秒10帧采样,并对图像进行压缩,并使用多线程处理,结果效果不好,采样率只有再降~,采样降低势必造成一些精度损失,只能使用其他传感器进行弥补,所以走到了多传感器融合的道路。
然后就是手机相机了,卷帘相机,确实是个头疼的问题,走快了,图像花的不行,发生严重畸变,所有自己就写了个算法对可以用和不可用进行处理,并完善采样过程中的不足,但是依然没有彻底解决,但是解决了不少。
其中一些难点的解决思路。 1. 计算量大:我们从优化算法(采用FAST+SSD提取特征点),使用simd指令集,通过内存换时间这三方面来提升。 2. 单目初始化:我们结合了IMU来解决,首先找到一个平面,然后再从这个平面上来构建地图,这样就不需要平移相机了。 3. 纯旋转:单目通过算法可以解决一部分,可参考《Robust Keyframe-based Monocular SLAM for Augmented Reality 》 ,里面写得很详细。 4. 遮挡和动态物体,特征缺失、动态光源和人物的干扰:首先把屏幕分成区域,使跟踪的特征点均匀分布在这些区域里,再在算法里面进行检测,那么一直在运动的特征点就会被排除掉(加入深度信息后,这个特点胡得到一个很有效的解决,在208年的SLAM大会上CAD&CG国家重点实验室的研究成果显示,深度学习融合深度可以有效地解决这个问题。 5. 回环检测:类似ptam处理,为每一个关键帧创建了一个Small Blurry Image,在回环检测线程里,随时比对两个SBI是否一致,来判断是否回环。 6. 尺度问题:我们采用的是相对尺度,单目+IMU可以解决这个问题,ARKit的绝对尺度做得很不错.
手机移动方向,手机移动方向是个大问题,实际用的时候不能总是手拿着相机不动吧,不现实,Tango不知道怎么做到的,一直研究。要注意:回环检测一定要适合自己系统重写!!,识别不同场景,目前开源的所有算法几乎都尝试过,不是前期库加载太慢,就是效率太低,无法使用!!优化算法可以研究后进行移植,适合自己的,我用的是g2o。再就是手机花费最多的时间是mapping过程,这个过程是将手机形成的三维点进行对帧之间的对照,也就是说是寻找一个三维点被那几个帧看到了,从而进行优化,一定要注意!!!这里最好解决的就是手机参数了,简单粗暴,每个手机都校准一下呗,然后写到数据库中,这里就怀念iphone了,就那么几种型号,怪不的好多做视觉的都使用iphone补充: 注意尺度问题,我推荐使用IMU进行对尺度补充,可以降低计算成本!!
2.1 运动太快
运动太快可能导致相机图像出现运动模糊,成像质量下降。传统卷帘快门式的相机,在运动较快时将产生明显的模糊现象。不过现在我们有全局快门的相机了,即使动起来也不会模糊的相机,只是价格贵一些。

(全局快门相机在拍摄高速运动的物体仍是清晰的)
运动过快的另一个结果就是两个图像的重叠区(Overlap)不够,导致没法匹配上特征。所以视觉SLAM中都会选用广角、鱼眼、全景相机,或者干脆多放几个相机。
2.2 相机视野不够
如前所述,视野不够可能导致算法易丢失。毕竟特征匹配的前提是图像间真的存在共有的特征。
2.3 计算量太大
基于特征点的SLAM大部分时间会花在特征提取和匹配上,所以把这部分代码写得非常高效是很有帮助的。这里就有很多奇技淫巧可以用了,比如选择一些容易计算的特征/并行化/利用指令集/放到硬件上计算等等,当然最直接的就是减少特征点啦。这部分很需要工程上的测试和经验。总而言之特征点的计算仍然是主要瓶颈所在。要是哪天相机直接输出特征点就更好了。
2.4 遮挡
相机可能运动到一个墙角,还存在一些邪恶的开发者刻意地用手去挡住你的相机。他们认为你的视觉SLAM即使不靠图像也能顺利地工作。这些观念是毫无道理的,所以直接无视他们即可。
2.5 特征缺失、动态光源和人物的干扰
老实说SLAM应用还没有走到这一步,这些多数是研究论文关心的话题(比如直接法)。现在AR能够稳定地在室内运行就已经很了不起了。
3. 可能的解决思路
前边总结了一些单目视觉可能碰到的困难。我们发现大部分问题并不能在当下的视觉方案能够解决的。你或许可以通过一些工程技巧加速特征匹配的过程,但像尺度、遮挡之类的问题,明显无法通过设计软件来解决。所以怎么办呢?——既然视觉解决不了,那就靠别的来解决吧。毕竟一台设备上又不是只有一块单目相机。更常见的方案是,用视觉+IMU的方式做SLAM。广角单目+IMU被认为是一种很好的解决方案。它价格比较低廉,IMU能在以下几点很好地帮助视觉SLAM:
- IMU能帮单目确定尺度
- IMU能测量快速的运动
- IMU在相机被遮挡时亦能提供短时间的位姿估计
所以不管在理论还是应用上,都出现了一些单目+IMU的方案[2,3,4]。众所周知的Tango和Hololens亦是IMU+单目/多目的定位方式(在2018年全国slam论坛见到前TANGO时表示,这个问题是另一种底层技术,特点描述为低帧运行,高帧显示的技术。用Tango玩MC,缺点是盖的房子尺寸和真实世界一样。盖二楼你就得真跑到楼上去盖——这怎么造圆明园?)
(这货就是靠后边这鱼眼+IMU做跟踪的)
reference:
- Strasdat, Montiel, A.J.Davison, Scale drift-aware large scale monocular SLAM, RSS 2006.
- Leutenegger et. al., Keyframe-based visual-inertial odometry using nonlinear optimization, IJRR 2015.
- Huang Guoquan, Kaess and Leonard, Towards Consistent Visual-Inertial Navigation, ICRA 2014.
- Li Mingyang and Mourikis, High-precision, consistent EKF-based visual-inertial odometry, IJRR, 2013.
- ORB-SLAM: a Versatile and Accurate
- Monocular SLAM System
- [Monocular Visual-Inertial State Estimation for Mobile Augmented Reality
- A Multi-State Constraint Kalman Filter for Vision-aided Inertial Navigation
- Robust Keyframe-based Monocular SLAM for Augmented Reality
- Parallel Tracking and Mapping on a Camera Phone
- gaoxiang视觉SLAM十四讲