说到数据结构,一般面试的时候经常会问这个问题,这个属于很基本的知识点,但是往往平时开发的时候自然而然的会用,面试需要你系统说的时候可能就卡壳了,今天打算把它系统整理下,以后也可以很好的表述出来。。。
说到开发:
程序开发 = 数据结构 + 算法;
用这个公式可以大体表述我们开发的架构,所以数据结构是开发的基础框架。
一、官方概念:
数据结构是一门研究非数值计算的程序设计问题中的操作对象,以及它们之间的关系和操作等相关问题的学科。
可以理解为是数据元素之间存在的关系的集合。
二、数据结构的细分:
数据结构中的具体结构是我们需要学习和研究的主体对象,因为数据在内存中的表现形式都是二进制。传统上,我们把数据结构分为逻辑结构和物理结构。
(一)、逻辑结构:反应元素之间的逻辑关系,即元素前后之间的关系,和存储位置没有任何关系。
·1、集合结构
集合结构中的元素属于同一个集合中,它们的关系是并列关系。
2、线性结构
线性结构中的元素存在一对一的关系。
3、树形结构
树形结构中的元素一般存在一对多的关系。
4、图形结构
图形结构中的元素存在着多对多的相互关系。
(二)、物理结构:又叫存储结构。指数据在在计算机存储空间的存储形式,即数据在存储器中的存放形式,存储器主要针对内存而言,硬盘、光盘、软盘等外部存储器的数据组织常用文件结构来描述。
1、顺序存储结构
顺序存储结构是把数据元素存储在连续的数据单元里,其数据间的逻辑关系和物理关系是一致的。典型:数组。
2、链式存储结构
链式存储结构是把数据元素存储在非连续的数据单元里,即把数据存储在内存的任意的位置,这些数据在内存中的地址可以是连续的也可以是不连续的。它是通过指针来找到对应的元素。
三、java中常用的数据结构
1、线性表
线性表在内存中是一块连续的存储空间;在线性表中访问元素的速度很快,但是在添加或者删除元素的时候,改变线性表的长度,它会在移动元素上耗费大量的时间。线性表最直接的代表是:数组,ArrayList
2、链式表
链表的存储是链式的,它不强迫数据是在一片连续的内存空间;它可以是分散存储的。所以,它的每个元素除了包括元素的值外,还要包括一些额外的信息;如:它的下一个元素在什么地方。
最基本的链式存储中的元素包括两部分:元素值和下个元素的位置;JAVA 中对链表的实现是通过类:LinkedList来实现的。 (这篇博客关于链表的例子解释很清楚,可以看看)
3、栈
栈是一种只能在一端进行插入和删除操作的特殊线性表。
其中,允许插入和删除的一端称为栈顶,另一端称为栈底。通常,将栈的插入操作称为入栈,删除操作称为出栈。入栈时元素总是放在栈底,而出栈的总是栈顶元素。因此,栈中元素采用的是“后进先出”的方式。
栈的数据元素类型可以任意,只要是同一种类型即可。它的基本操作包括清空、判空、求元素个数、获取栈顶、入栈和出栈等。
public class StackTest {
private Object[] stacks;//栈内的元素数组
private int top;//栈顶的指针值
public StackTest(int maxSize) {
stacks = new Object[maxSize];
top = 0;
}
/**
* 清楚栈内元素
*/
public void clear() {
top = 0;
}
/**
* 栈内元素是否为空
*
* @return
*/
public boolean isEmpty() {
return top == 0;
}
/**
* 栈内元素的个数
*
* @return
*/
public int length() {
return top;
}
/**
* 栈顶元素
*
* @return
*/
public Object peek() {
if (!isEmpty()) {
return stacks[top - 1];
} else {
return null;
}
}
/**
* 入栈
*
* @param e
*/
public void push(Object e) throws Exception {
if (top == stacks.length) {
throw new Exception("栈已满");
} else {
stacks[top++] = e;
}
}
/**
* 出栈
*
* @return
* @throws Exception
*/
public Object pop() throws Exception {
if (top == 0) {
throw new Exception("栈已空");
} else {
return stacks[--top];
}
}
}
4、队列
队列(queue)也是一种线性表,它的特性是先进先出,插入在一端,删除在另一端。就像排队一样,刚来的人入队(push)要排在队尾(rear),每次出队(pop)的都是队首(front)的人。
队列(Queue)与栈一样,是一种线性存储结构,它具有如下特点:
1)队列中的数据元素遵循“先进先出”(First In First Out)的原则,简称FIFO结构。
2)在队尾添加元素,在队头删除元素。
5、串
串(string)是由零个或多个宇符组成的有限序列,又名叫字符串。
串中的字符数目n称为串的长度,定义中谈到“有限”是指长度n是一个有限的数值。零个字符的串称为空串(null string),它的长度为零,可以直接用两双引号一表示,也可以用希腊Φ字母来表示。所谓的序列,说明串的相邻字符之间具有前驱和后继的关系。
空格串,是只包含空格的串。注意它与空串的区别,空格串是有内容有长度的,而且可以不止一个空格。
子串与主串,串中任意个数的连续字符组成的子序列称为该串的子串,相应地,包含子串的串称为主串。
子串在主串中的位置就是子串的第一个字符在主串中的序号。
6、数组
数组是用来存放同一种数据类型的集合,注意只能存放同一种数据类型(Object类型数组除外)。
数组的局限性分析:
①、插入快,对于无序数组,上面我们实现的数组就是无序的,即元素没有按照从大到小或者某个特定的顺序排列,只是按照插入的顺序排列。无序数组增加一个元素很简单,只需要在数组末尾添加元素即可,但是有序数组却不一定了,它需要在指定的位置插入。
②、查找慢,当然如果根据下标来查找是很快的。但是通常我们都是根据元素值来查找,给定一个元素值,对于无序数组,我们需要从数组第一个元素开始遍历,直到找到那个元素。有序数组通过特定的算法查找的速度会比无需数组快,后面我们会讲各种排序算法。
③、删除慢,根据元素值删除,我们要先找到该元素所处的位置,然后将元素后面的值整体向前面移动一个位置。也需要比较多的时间。
④、数组一旦创建后,大小就固定了,不能动态扩展数组的元素个数。如果初始化你给一个很大的数组大小,那会白白浪费内存空间,如果给小了,后面数据个数增加了又添加不进去了。
很显然,数组虽然插入快,但是查找和删除都比较慢,而且扩展性差,所以我们一般不会用数组来存储数据,那有没有什么数据结构插入、查找、删除都很快,而且还能动态扩展存储个数大小呢,答案是有的,但是这是建立在很复杂的算法基础上。
7、广义表
广义表是由零个或多个原子或子表组成的优先序列,是线性表的推广。区别在于:线性表的元素仅限于原子项;而广义表的元素即可以是原子项,也可以是广义表。
具有递归特性:由表头、表尾的定义可知:任何一个非空广义表其表头可能是原子,也可能是列表,而其表尾必定是列表。每个表尾又可以继续分为表头,表尾……
8、树和二叉树
二叉树:每个结点至多只有两棵子树(即二叉树中不存在度大于2的结点),并且,二叉树的子树有左右之分,其次序不能任意颠倒。
满二叉树:2^k-1个结点的深度为K的二叉树。
完全二叉树:一棵具有n个结点的二叉树的结构与满二叉树的前n个结点的结构相同,这样的二叉树称作完全二叉树。即树的结点对应于相同深度的满二叉树。
基本操作:树的主要操作有
(1)创建树IntTree(&T)
(2)销毁树DestroyTree(&T)
(3)构造树CreatTree(&T,deinition)
(4)置空树ClearTree(&T)
(5)判空树TreeEmpty(T)
(6)求树的深度TreeDepth(T)
(7)获得树根Root(T)
(8)获取结点Value(T,cur_e,&e),将树中结点cur_e存入e单元中。
(9)数据赋值Assign(T,cur_e,value),将结点value,赋值于树T的结点cur_e中。
(10)获得双亲Parent(T,cur_e),返回树T中结点cur_e的双亲结点。
(11)获得最左孩子LeftChild(T,cur_e),返回树T中结点cur_e的最左孩子。
(12)获得右兄弟RightSibling(T,cur_e),返回树T中结点cur_e的右兄弟。
(13)插入子树InsertChild(&T,&p,i,c),将树c插入到树T中p指向结点的第i个子树之前。
(14)删除子树DeleteChild(&T,&p,i),删除树T中p指向结点的第i个子树。
(15)遍历树TraverseTree(T,visit())
1、链式存储的二叉树的基本操作以及算法实现
因为顺序存储只适用于满二叉树,如果存储完全二叉树,会造成空间的大量浪费,比如最坏情况下,k度的完全二叉树每个节点只有左子树存在,这样将有2^k-k-1个节点存储空值。所以选用链表存储二叉树更合适。
树的链式存储结构可抽象出来,Java语言描述如下:
public class TreeNode {
int data;
TreeNode leftNode;
TreeNode rightNode;
public TreeNode() {
}
public TreeNode(int data) {
this.data = data;
this.leftNode = null;
this.rightNode = null;
}
public TreeNode(int data, TreeNode leftNode, TreeNode rightNode) {
this.data = data;
this.leftNode = leftNode;
this.rightNode = rightNode;
}
}
//实现二叉链表结构,建立二叉树
public TreeNode createTree() {
int data[] = {1, 2, 0, 0, 3, 4, 5, 0, 6, 7, 8, 0, 0, 9};
TreeNode tree;
for (int i = 0; i < data.length; i++) {
tree = new TreeNode(data[i]);
tree.leftNode = createTree();
tree.rightNode = createTree();
}
return tree;
}2、二叉树的遍历操作
如果遵循先左后右的规则,那么二叉树的遍历方法可分为三种:先根序遍历;中根序遍历;后根序遍历。
//先根序的递归方法遍历
public void disp(TreeNode tree) {
if (tree != null) {
System.out.print(tree.data);
disp(tree.leftNode);
disp(tree.rightNode);
}
}
//中根序的递归方法遍历
public void disp(TreeNode tree) {
if (tree != null) {
disp(tree.leftNode);
System.out.print(tree.data);
disp(tree.rightNode);
}
}
//后根序的递归方法遍历
public void disp(TreeNode tree) {
if (tree != null) {
disp(tree.rightNode);
System.out.print(tree.data + " ");
disp(tree.leftNode);
}
}四、Android中常用的数据结构
Android中一般使用的数据结构有Java中基础数据结构Set,List,Map,还有Android特有的,不如SparseArray。数据结构图,表述如下:
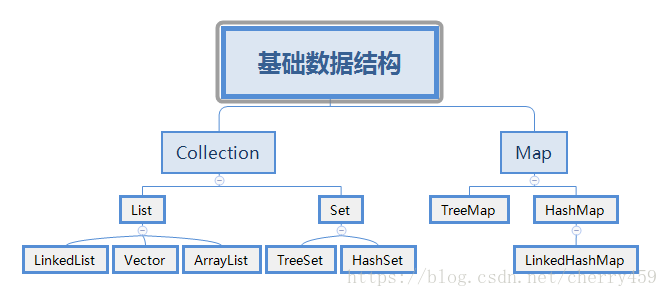
Collection 是所有集合类的接口,Set,List都实现Collection接口。Collection元素迭代:
/**
* 迭代访问集合中的子元素
*/
private void test() {
Iterator it = collections.iterator();//collections 就是需要遍历的元素集合
while (it.hasNext()) {
Object next = it.next();//得到下一个元素
}
}1、Set
Set 一般使用是TreeSet 和 HashSet,Set是一个不能包含重复元素的集合。
1)、TreeSet
根据二叉树实现,放入数据不能重复且不能为null,可以重写compareTo()方法来确定元素大小,从而进行升序排序。
/**
* TreeSet的集合创建
*/
public void createSet() {
Set<Integer> sets = new TreeSet<>(new MyOrderComparator());
sets.add(1);
sets.add(2);
sets.add(4);
for (Integer inn : sets) {
LogUtils.e("元素输出: " + inn);//结果:1 2 4
}
}
static class MyOrderComparator implements Comparator<Integer> {
@Override
public int compare(Integer o1, Integer o2) {
if (o1 < o2) {
return -1;
}
if (o1 == o2) {
return 0;
}
if (o1 > o2) {
return 1;
}
return 0;
}
}2)、HashSet
根据hashCode来决定存储位置,所以必须实现hashCode()方法,存储数据是无序的且不能重复,可以存储null,但是有且仅有一个。
public void createSet() {
Set<String> sets = new HashSet<>();
sets.add("orange");
sets.add("apple");
sets.add("orange");
sets.add("orange");
sets.add("orange");
sets.add(null);
sets.add("apple");
sets.add("orange");
sets.add(null);
sets.add(null);
sets.add(null);
sets.add(null);
for (String inn : sets) {
LogUtils.e("元素输出: " + inn);//输出结构:orange apple null
}
}2、List
List比较常用的是ArrayList 和 LinkedList,还有一个Vector,不太常用。
未完待续