1.摘要
本文将对Tesseract OCR引擎做一个综合概述,重点放在OCR引擎几个创新/不寻常的方面,尤其包括线查找(line finding),特征/分类方法(features/classification methods),以及自适应分类器(adaptive classifier).
2.简介--动机和历史
Tesseract 是由HP在1984年到1994年之间开发的一个开源OCR引擎。它就像一颗超新星,横空出现在1995年拉斯维加斯大学OCR准确率年检上[1],因其优异的成绩闪闪发光,然后以相同的神秘感销声匿迹。现在,这是第一次披露关于它详细的架构和算法。
Tesseract开始于HP Bristol实验室的博士研究项目[2],作为惠普平板扫描仪系列的合适软件或者硬件扩展,进行推动。Tesseract的设计初衷是基于一个状况:当时的商业OCR引擎还在发展初期,除了高质量的印刷字体外,其他字体表现非常糟糕。
在HP Bristol实验室和HP在科罗拉多的扫描仪部门的一个联合项目之后,相比于商业引擎,Tesseract在精度上有了明显的领先,但是它依然没有成为一个产品。后一阶段的开发是一个针对压缩的OCR研究,又回到了HP Bristol实验室。工作内容更多的是集中在提高排除阻碍的效率而不是基本的准确率。1994年末,该联合项目结束,Tesseract的开发完全终止。1995年,该引擎被送到1995年拉斯维加斯大学OCR准确率年检上,在那里,证明了它的价值。在2005年,HP将其作为开源软件发布。你可以在这里下载(谷歌连接,需要翻墙,也可以在GitHub上下载)。
3.架构
因为HP独立开发了页面布局分析技术并运用到了产品当中,所以Tesseract不需要自己的页面布局分析,Tesseract也因此假定它的输入是一个任意多边形确定文本区域的二进制图像。
处理遵循传统逐步流水线过程,但是可能是不一样的。第一步是连接组件分析,存储组件的轮廓。从计算方面来讲,这在当时是一个代价很大的设计决策,但是它也有一个显著的优势:通过检查轮廓的嵌套以及子轮廓和孙子轮廓的数目,很容易检测和识别反向文本,就像识别黑白文本一样。Tesseract可能是第一个可以如此轻易处理黑白文本的OCR引擎。在这一阶段,轮廓通过嵌套被聚集在一起,成为Blobs。
Blobs组成文本行,对于固定间距和成比例的文本,分析行和区域。根据字符间隔的类型,将文本行分割成不同的单词。固定间距的文本立刻被字符单元格切割。利用确定的和模糊的空格,成比例的文本被分割成为单词。
识别,进行两段处理过程。第一段,尝试依次识别每一个单词,每一个符合要求的单词都当成是自适应分类器的的训练数据。然后,自适应分类器可以更加准确地识别页面后面的文本。
因为存在这样的情况,自适应分类器也许学习到了一些有用的信息,但是没有作用到页面前面的文本。所以,第二段过程重新处理整个页面。在这个过程中,第一段过程没有被很好识别的单词将会被再次识别一次。
最后阶段,处理模糊的空格和检查x高度的可替代假设来定为小覆盖文本。
4.行和词的查找
4.1行查找
4.2基线拟合
一旦文本行找到了,用二次样条更精准的拟合基线。这是一个OCR系统的另一个首次,使Tesseract可以处理带有曲线基线[ 5 ]的页面,这是在扫描常见的伪影,不只是在书籍装订中。
基线的拟合是通过将blobs划分成原始直线基线的连续位移组来拟合的。在最稠密的分割上用一个二次样条拟合,(假设是基线)的最小二乘拟合。二次样条的优点是这种计算相当稳定,但在需要多个样条线段时会出现不连续性的缺点。传统的三次样条可能表现更好。

图1是一个带有拟合基线、上缘线、中线和下缘线的文本行例子,所有这些线都是平行的(整个长度的y间隔是一个常量),并且带有轻微弯曲。上缘线是蓝绿色,它上面的黑线是直的。仔细观察可以发现,蓝绿色的线相对于它上面的黑色直线是弯曲的。
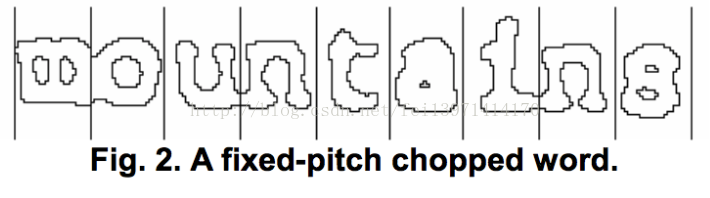
4.3固定字宽的检测和截断
Tesseract测试文本行,判断他们是否固定字宽。在找到固定字宽的文本的地方,Tesseract使用这个宽度将单词截断成为字符,and disables the chopper and associator on thesewords for the word recognition step.
4.4成比例单词查找

5.单词识别
5.1截断连在一起的字符

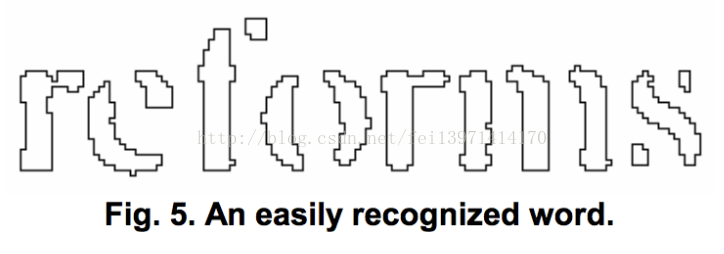
图4展示了带有箭头指示的截断点候选集合,以及被选择的被选择的截断点所组成的‘r’和“m”之间的连接线。
截断点执行按照优先级顺序。任何不能提高结果可信度的截断将不会被执行,但是也不会被完全丢弃,如果需要,这些截断将在后面被associator再次利用。
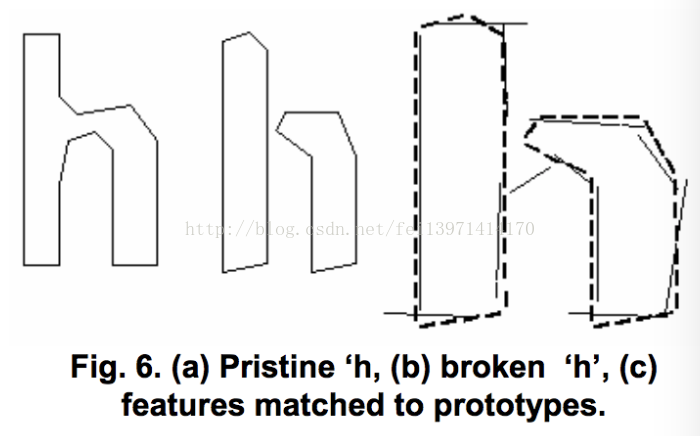
5.2关联损坏字符
6.静态字符分类器
6.1特征
6.2分类
6.3训练数据
7.语言学分析
8.自适应分类器

[1] S.V. Rice, F.R. Jenkins, T.A. Nartker,The Fourth AnnualTest of OCR Accuracy, Technical Report 95-03, InformationScience Research Institute, University of Nevada, Las Vegas,July 1995.
[2] R.W. Smith,The Extraction and Recognition of Textfrom Multimedia Document Images,PhD Thesis, Universityof Bristol, November 1987.
[3] R. Smith, “A Simple and Efficient Skew DetectionAlgorithm via Text Row Accumulation”,Proc. of the 3rdInt.Conf. on Document Analysis and Recognition(Vol. 2), IEEE1995, pp. 1145-1148.
[4] P.J. Rousseeuw, A.M. Leroy,Robust Regression andOutlier Detection, Wiley-IEEE, 2003.
[5] S.V. Rice, G. Nagy, T.A. Nartker,Optical CharacterRecognition: An Illustrated Guide to the Frontier, KluwerAcademic Publishers, USA 1999, pp. 57-60.
[6] P.J. Schneider, “An Algorithm for Automatically FittingDigitized Curves”, in A.S. Glassner,Graphics Gems I,Morgan Kaufmann, 1990, pp. 612-626.
[7] R.J. Shillman,Character Recognition Based onPhenomenological Attributes: Theory and Methods,PhD.Thesis,Massachusetts Institute of Technology. 1974.
[8] B.A. Blesser, T.T. Kuklinski, R.J. Shillman, “EmpiricalTests for Feature Selection Based on a PscychologicalTheory of Character Recognition”,Pattern Recognition8(2),Elsevier, New York, 1976.
[9] M. Bokser, “Omnidocument Technologies”,Proc. IEEE80(7), IEEE, USA, Jul 1992, pp. 1066-1078.
[10] H.S. Baird, R. Fossey, “A 100-Font Classifier”,Proc. ofthe 1stInt. Conf. on Document Analysis and Recognition,IEEE, 1991, pp 332-340.
[11] G. Nagy, “At the frontiers of OCR”,Proc. IEEE80(7),IEEE, USA, Jul 1992, pp 1093-1100.
[12] G. Nagy, Y. Xu, “Automatic Prototype Extraction forAdaptive OCR”,Proc. of the 4thInt. Conf. on DocumentAnalysis and Recognition, IEEE, Aug 1997, pp 278-282.
[13] I. Marosi, “Industrial OCR approaches: architecture,algorithms and adaptation techniques”,DocumentRecognition and Retrieval XIV,SPIE Jan 2007, 6500-01.