今天看到传智播客有关爬虫的视频课,其中使用的语言为python2版本,经过本人的修改将其用python3实现。
在此过程中学到一些东西,特此记录。
知识点一:注意观察被爬网站的域名特点。
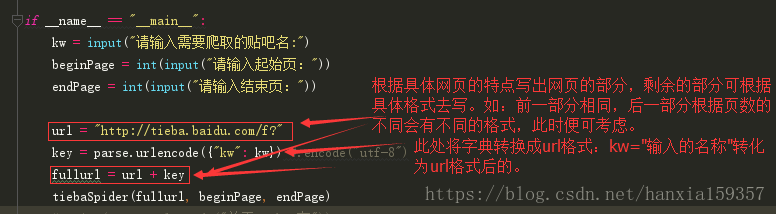
知识点二:按照页数爬取信息。

知识点三:注意编码格式的问题,可解决:写入文件时UnicodeEncodeError: 'gbk' codec can't encode character '\xba' in p.......的问题。

完整代码:(有些冗余,赶着睡觉呢!!)
from urllib.request import urlopen
from urllib import parse
def loadPage(url, filename):
"""
作用:根据url发送请求,获取服务器响应文件
url: 需要爬取的url地址
filename : 处理的文件名
"""
print ("正在下载 " + filename)
# request = urllib.Request(url, headers = headers)
html = urlopen(url).read().decode("utf-8")
# print(html.read().decode("utf-8"))
print(html)
return html
def writePage(html, filename):
"""
作用:将html内容写入到本地
html:服务器相应文件内容
"""
print ("正在保存 " + filename)
# 文件写入
with open(filename, "w",encoding="utf-8") as f:
f.write(html)
print ("-" * 30)
def tiebaSpider(url, beginPage, endPage):
"""
作用:贴吧爬虫调度器,负责组合处理每个页面的url
url : 贴吧url的前部分
beginPage : 起始页
endPage : 结束页
"""
for page in range(beginPage, endPage + 1):
pn = (page - 1) * 50
filename = "第" + str(page) + "页.html"
fullurl = url + "&pn=" + str(pn)
print (fullurl)
html = loadPage(fullurl, filename)
print ("网站内容:",html)
writePage(html, filename)
print ("谢谢使用")
if __name__ == "__main__":
kw = input("请输入需要爬取的贴吧名:")
beginPage = int(input("请输入起始页:"))
endPage = int(input("请输入结束页:"))
url = "http://tieba.baidu.com/f?"
key = parse.urlencode({"kw": kw}) #.encode("utf-8")
fullurl = url + key
tiebaSpider(fullurl, beginPage, endPage)
# print(parse.urlencode("关于Python在"))
print("key",key)
print(parse.urlencode({"kw":"除了web开发以外,还有其他吗?"}))
html = urlopen("http://tieba.baidu.com/f?kw=python&pn=100")
print(html.read().decode("utf-8"))