GitHub地址:https://github.com/HelloIK/Maths-Question-Generator
施工中
一. 项目相关要求
实现一个自动生成小学四则运算题目的命令行程序(具体要求参见需求文档)
二. 项目成员及分工概况
生成题目模块
解析答案模块
测试
三. PSP
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 900 | 1200 |
| Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | 480 | 480 |
| · Design Spec | · 生成设计文档 | 30 | 30 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 120 | 240 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 20 |
| · Design | · 具体设计 | 60 | 60 |
| · Coding | · 具体编码 | 400 | 600 |
| · Code Review | · 代码复审 | 120 | 120 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 100 | 120 |
| Reporting | 报告 | ||
| · Test Report | · 测试报告 | 30 | 60 |
| · Size Measurement | · 计算工作量 | 20 | 15 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 30 |
| 合计 | 1600 | 2500 |
四. 解题思路
1) 生成题目模块:
算术表达式:e = n | e1 + e2 | e1 − e2 | e1 × e2 | e1 ÷ e2 | (e),
我们首先来定义一下什么是表达式。这是一个递归的定义:
• 由一个 位于左边的表达式 和一个 操作符 加上一个 位于右边的表达式 组成。
• 一个 操作数。
不难看出,表达式的定义和二叉树十分契合。用二叉树来实现表达式十分友好。我们当初其实有考虑过用逆波兰表达式,现在回想起来或许用逆波兰表达式编码会更容易。
2) 解析答案模块:
• 文本读写 -> stream流
• 题目解析 -> 考虑到每一个表达式实际上都是由多个Token(符号或数字)组成,因此可以先为表达式定义一种符合运算规则的文法定义,然后递归进行词法分析和语法分析
• 结果处理 -> 需要将生成结果进行相应的处理(如,约分、取零、消除假分数等)
• 比较判断 -> 与读入的回答文件进行对比,判断正误给出成绩
五. 设计说明
• 项目结构图

• 源文件目录结构图

• 设计说明
1) 生成题目模块:
• 如何判断重复
程序一次运行生成的题目不能重复,即任何两道题目不能通过有限次交换+和×左右的算术表达式变换为同一道题目。例如,23 + 45 = 和45 + 23 = 是重复的题目,6 × 8 = 和8 × 6 = 也是重复的题目。3+(2+1)和1+2+3这两个题目是重复的,由于+是左结合的,1+2+3等价于(1+2)+3,也就是3+(1+2),也就是3+(2+1)。但是1+2+3和3+2+1是不重复的两道题,因为1+2+3等价于(1+2)+3,而3+2+1等价于(3+2)+1,它们之间不能通过有限次交换变成同一个题目。
给定两棵树T1和T2。如果T1可以通过若干次左右孩子互换就变成T2,则我们称两棵树是“同构”的。同构的定义和同一个表达式的定义略有区别,但道理是一样的。我们可以把两个表达式的重复,抽象成一种特殊的同构。
最优的做法是构造出一个映射F,使得F(E1)=F(E2)当且仅当表达式E1=E2。但考虑到题目要求操作符的数量被限制到最多3个,也就是说树的最大节点数是7,最大深度是4,且仅仅在树的深度是3且有3个操作符的情况下才可能出现满二叉树,即使暴力递归也花不了多少时间,所以我们可以不那么严格。
我设计了一个哈希函数H,它能保证当E1=E2时,H(E1)=E(E2),但反过来却不能保证H(E1)=E(E2)时,E1=E2。在比较两个表达式时,先比较hash值,如果相等,再遍历两棵树来判断是否是重复。其实我的hash函数设计得不算好,勉强能用,如果有谁有好的思路请告诉我。一开始我的hash函数设计的思想是这样的:同构的表达式具有的token总是相同的,因此我对每个token求hash,再异或。例如:
1 1 + 2 x 3 = 3 x 2 + 1 2 3 hash(1) Xor hash(+) Xor hash(2) Xor hash(x) Xor hash(3) = hash(3) Xor hash(x) Xor hash(2) Xor hash(+) Xor hash(1)
但异或最大的问题就是相同两个数异或之后结果为零,因此1+1和2+2具有相同的hash值,而且(1+2)x3和1+2x3具有相同的hash值。后来我对hash函数做了一点改进,在每个操作符节点里存了该操作符运算的结果,用这个结果来做hash而不是用符号本身,减少了碰撞,但总体思路还是利用了异或运算符的交换律。
因此,现在我们可以用一个哈希表来实现我们的判重。当我们插入一个表达式到哈希表时,对桶内具有同一hash值的表达式暴力递归是否相同。由于hash函数已经帮我们进行了一次筛选,大大减少了比较的次数。哈希表的具体实现我使用了C++STL中的unorder_set。
后来我查资料时了解到判断树是否同构有更好的解,就是利用最小表达的思想可以为每个表达式按照字典顺序构建出一个字符串,相同的表达式具有相同的字符串。但这时候我已经完成了大部分的工作,而且程序的性能还能接受,因此并没有做出改进。事实上假如程序的性能不太能接受,我大概率也是选择开多一个线程而不是去大动干戈去改算法。
• 如何处理特殊数字
• 我们只有在减法的时候才会出现负数,因此我们遇到负数时,直接把减号左右两边的表达式交换过来。
• 在遇到除数是0时,把被除数和除数的位置交换,如果交换后除数还是0(0 ÷ 0),把除数替换成1。
• 核心代码
• hash函数
1 inline size_t hasher(std::shared_ptr<Expression> e) { 2 size_t ret = 0; 3 e->inOrder(e->root, [&](Expression::ExprPtr p) { 4 int v = p->result->_numerator; 5 int u = p->result->_denominator; 6 size_t h1 = std::hash<int>()(u); 7 size_t h2 = std::hash<int>()(v); 8 ret ^= (h1 ^ h2); 9 }); 10 return ret; 11 }
• 判断表达式相等
1 bool 2 ExpressionTree::isEqual(ExprPtr & lhs, ExprPtr & rhs) { 3 // 判断叶子情况 4 if (lhs == nullptr && rhs == nullptr) 5 return true; 6 if ((lhs == nullptr && rhs != nullptr) 7 || (lhs != nullptr && rhs == nullptr)) 8 return false; 9 // 判断答案 10 if (lhs->result->equal(rhs->result) == false) 11 return false; 12 // 判断类型 13 if (typeid(*lhs) != typeid(*rhs)) 14 return false; 15 16 // 判断是否相同 17 // 如果是加法和乘法,判断是否同构 18 if (!isEqual(lhs->rchild, rhs->rchild) 19 || !isEqual(lhs->lchild, rhs->lchild)) 20 return false; 21 22 if (typeid(*lhs) == typeid(Plus) || typeid(*lhs) == typeid(Mul)) { 23 if (!isEqual(lhs->rchild, rhs->lchild) 24 || !isEqual(lhs->lchild, rhs->rchild)) 25 return false; 26 } 27 28 return true; 29 }
• 用字符串表示表达式树,并加入括号
1 string ExpressionTree::_toStringIter(ExprPtr p, int precedence, int leftOrRight) { 2 if (p->type() == OPERATOR) { 3 int e = std::dynamic_pointer_cast<BinaryPredicate>(p)->precedence(); 4 string ret = _toStringIter(p->lchild, e, LEFT) 5 + p->toString() 6 + _toStringIter(p->rchild, e, RIGHT); 7 // 如果当前运算符优先级小于上一个运算符 8 // 或者当前运算符优先级等于上一个运算符,但在上一运算符右边 9 if (e < precedence || (e == precedence && leftOrRight == RIGHT)) { 10 ret = string("(") + ret + string(")"); 11 } 12 return ret; 13 } else { 14 return p->toString(); 15 } 16 }
• 题目生成
1 ExpressionTree::ExprPtr 2 ExpressionTree::_iterGenerateToken(size_t &operatorNum, unsigned int range) { 3 if (operatorNum == 0) { 4 return addOperandRandomly(range); 5 } 6 int type = randomBetween(0, 1); 7 if (type == 0) { 8 operatorNum--; 9 auto p = addOperatorRandomly(); 10 p->lchild = _iterGenerateToken(operatorNum, range); 11 p->rchild = _iterGenerateToken(operatorNum, range); 12 adjustAndEval(p); 13 return p; 14 } else { 15 return addOperandRandomly(range); 16 } 17 } 18 19 void ExpressionTree::adjustAndEval(ExprPtr p) { 20 // 如果是除号 21 if (typeid(*p) == typeid(Div)) { 22 // 如果除号右边是零,交换左右表达式 23 // 如果交换之后右边还是零,则换成数字1 24 if (p->rchild->result->isZero()) { 25 exchange(p->lchild, p->rchild); 26 } 27 if (p->rchild->result->isZero()) { 28 p->rchild = std::make_shared<NumberToken>(1, 1); 29 } 30 } 31 p->result = p->eval(); 32 // 如果结果是负数,交换左右两个表达式 33 if (p->result->isNegative()) { 34 exchange(p->lchild, p->rchild); 35 p->result = p->eval(); 36 } 37 }
2) 解析答案模块:
• 主要逻辑
首先,由程序从用户输入的路径中读取相应的题目文件和回答文件,然后按行读取题目文件,同时解析题目并计算出正确答案,然后与回答文件中的答案进行比较,若相等则判定回答正确,反之则错误,最后将结果显示于Console并写出Grade.txt。由于文件的输入输出以及字符串对比的部分处理较为简单,以下将不会着重说明。
• 解析题目
应该如何让计算机理解表达式的定义,通过观察现有表达式,首先应该做的便是 "分词"(tokenize),即读取每个字符并将其组合为"单词",例如,如果输入: 12 + 1 ‘ 34 / 56 * 15 ÷ 2 , 那么解析模块应该产生如下的单词列表: 12 + 1 ’ 34 / 56 * 15 ÷ 2
实际上,一个单词就是一个字符序列,用来表示数字或者运算符。在产生了单词之后,由于计算表达式是存在相应的运算优先规则的,程序需要确保对运算顺序的正确执行。于是,为了让计算机能够理解这些规则,这里我们设计了一个"文法"(grammar)来定义表达式的语法,如下所示
• 表达式(Expression)
• 组合式
• 表达式 "+" 组合式
• 表达式 "-" 组合式
• 组合式(Combine)
• 基本单元
• 组合式 "*" 基本单元
• 组合式 "÷" 基本单元
• 基本单元(Unit)
• 数字
• "(" 表达式 ")"
• 数字(Number)
• 整数
• 整数 "/" 整数
• 整数 "'" 整数 "/" 整数
这个规则集合的优先级由上至下逐级递增,因为它们依赖其下一层级的规则来定义自身。依据上述规则,可以对给定输入进行语法分析。首先从顶层规则 表达式(Expression) 开始搜索单词,并根据文法进行匹配。我们以 1 + 2 为例,阐述分析的过程:
1 + 2 作为一个表达式读入
读取表达式左边,进入组合式
读取组合式左边,进入基本单元
读取基本单元,进入数字
读取数字,获得整数 1
1 作为单个 数字 提权为 基本单元
1 作为单个 基本单元 提权为 组合式
1 作为单个 组合式 提权为 表达式
读取下一个单词,为 "+" ,满足了 表达式 "+" 组合式,此时只需要读取 "+" 后的组合式
读取组合式左边,进入基本单元
读取基本单元,进入数字
读取数字,获得整数 2
2 作为单个 数字 提权为 基本单元
2 作为单个 基本单元 提权为 组合式
表达式 "+" 组合式 提权为 表达式
解析完成,同时计算也完成,此时返回的结果也是一个单词
• 核心代码
• 表达式实现
1 Token CheckProcess::expression() { 2 Token left = combine(); 3 Token token = getToken(); 4 while (1) { 5 switch (token.type) { 6 case '+': 7 left += combine(); 8 token = getToken(); 9 break; 10 case '-': 11 left -= combine(); 12 token = getToken(); 13 break; 14 default: 15 index--; 16 return left; 17 } 18 } 19 }
• 组合式实现
1 Token CheckProcess::combine() { 2 Token left = unit(); 3 Token token = getToken(); 4 while (1) { 5 switch (token.type) { 6 case '*': 7 left *= unit(); 8 token = getToken(); 9 break; 10 case DIV_CODE1: case DIV_CODE2: 11 left /= unit(); 12 token = getToken(); 13 break; 14 default: 15 index--; 16 return left; 17 } 18 } 19 }
• 基本单元实现
1 Token CheckProcess::unit() { 2 Token token = getToken(); 3 switch (token.type) { 4 case '(': { 5 Token _token = expression(); 6 token = getToken(); 7 // should be ")" 8 return _token; 9 } 10 case 'n': 11 return token; 12 } 13 }
• 单词解析实现
1 Token CheckProcess::getToken() { 2 if (index >= size) 3 return Token('e'); 4 char ch = line.at(index); 5 6 switch (ch) { 7 case '(': case ')': case '+': case '-': case '*': case DIV_CODE1: case DIV_CODE2: 8 if (ch == DIV_CODE1 || ch == DIV_CODE2) index++; 9 index++; 10 return Token(ch); 11 case '0': case '1': case '2': case '3': case '4': 12 case '5': case '6': case '7': case '8': case '9': { 13 string num = ""; 14 readMultiNums(num); 15 Token token('n', std::atoi(num.c_str())); 16 17 if (index < size - 1) { 18 ch = line.at(index + 1); 19 string molecular = ""; 20 string denominator = ""; 21 bool numFlag = false; 22 23 if (ch == '\'') { 24 index += 2; 25 readMultiNums(molecular); 26 numFlag = true; 27 ch = line.at(index + 1); 28 } 29 if (ch == '/') { 30 if (!numFlag) 31 molecular = num; 32 index += 2; // point the next integer behind "/" 33 readMultiNums(denominator); 34 } 35 if (!molecular.empty()) { 36 token.denominator = std::atoi(denominator.c_str()); 37 if (numFlag) 38 token.molecular = std::atoi(num.c_str()) * std::atoi(denominator.c_str()) + std::atoi(molecular.c_str()); 39 else 40 token.molecular = std::atoi(molecular.c_str()); 41 } 42 } 43 index++; 44 return token; 45 } 46 } 47 }
六. 性能分析
• 生成题目模块
1)考虑到在使用性能向导模式下测试时,程序的执行时间会被放大,所以实际上的执行速度是要比分析报告中快几个数量级的,因此最初我们对这个结果是基本满意的。
通过分析函数调用情况发现,"哈希函数"调用情况与预期一致,占用了主要的时间开销,但是此时改用别的方案并不现实,因为核心部分的运算是不可避免的,而且也无法确定是否新的方案就一定优于原有方案,冒然对代码进行大规模重构存在风险。故这里我们决定不对哈希函数的方案进行修改,而最终的测试结果也证明了使用哈希函数的方案是可行有效的 (见后测试结果)。
• 分析报告

2)但是,我们在调用树中发现,生成单词的函数调用存在一些问题:调用的次数异常,比预期的高了很多。经过排查发现,原因其实非常简单:在生成的题目中,我们对操作符号数量的控制出了疏漏,误将3写成了4,导致生成出来的题目几乎都是4个操作符, 这样无形中增加了表达式树的层级或广度,增大了运算量。
如此低级的错误出现确实不应该出现,原因在于开发过程中做单元测试时,我主要的关注点大多放在了结果是否能正确匹配上,忽略了生成的题目文件本身的符号已经超过这次作业的要求,在和卓辉讨论时便告诉他测试没有问题,这样一来导致多出一位符号的问题一直遗留到了最后才发现。
• 调用树
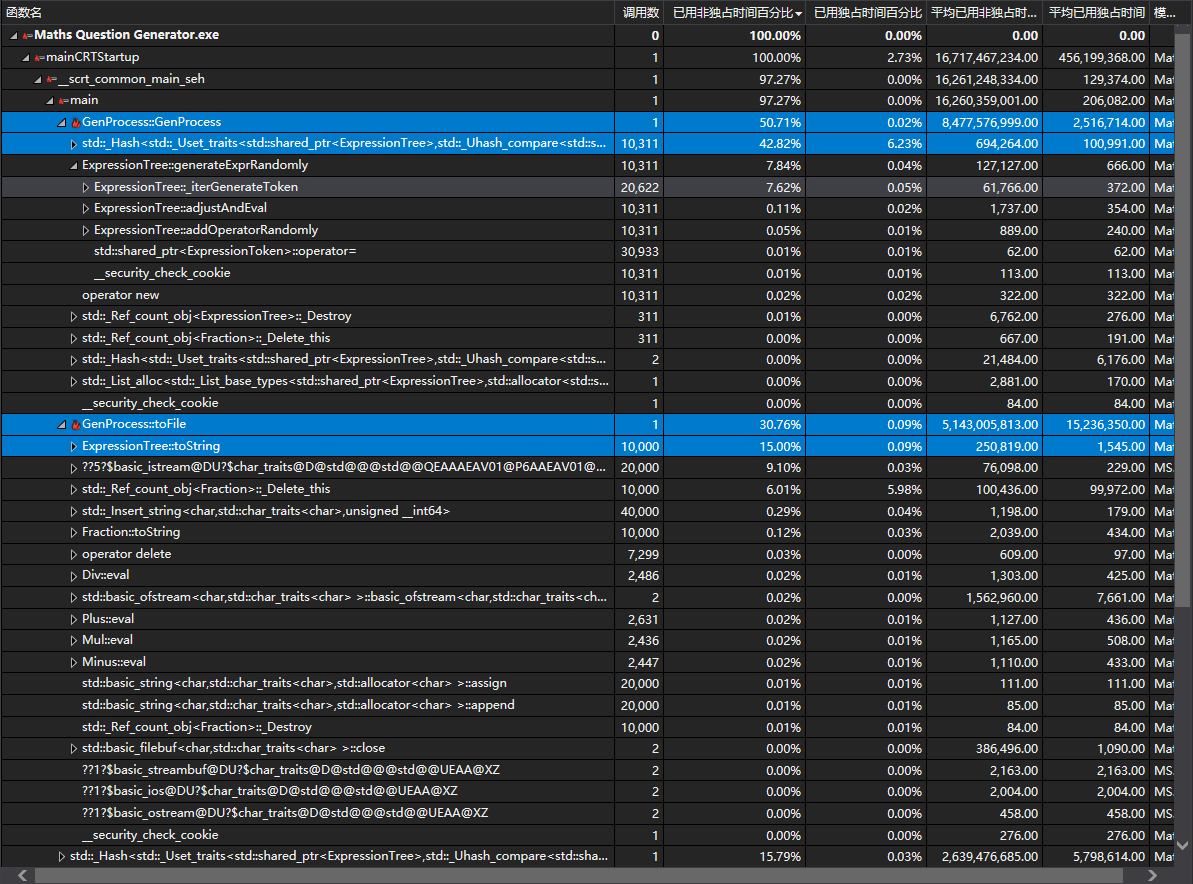
3)对符号数量进行修改以后,程序的性能确实有了提升
• 对比图

4)由于在上文中提到的运算符号多了一个的原因,这一次我们重新排查了一次生成出来的题目文件,发现我们生成出来的题目虽然完全符合规范要求,但是分数的占比实在过大,几乎达到了95%以上,由于分数生成过程相对复杂,因此我们决定控制分数生成的几率,期望能提高效率。
但是测试结果不尽人意,控制分数前后的时间开销几乎没有差别。经过分析我们发现,虽然控制分数生成几率后,生成的时间开销减少了,但是由于整数的占比增大,实际上会提高发生重复的几率,进而导致去重操作的增加,这一点从下面两张函数调用图的占比中可以明显看出,优化后哈希函数的调用明显增加。
• 函数调用详细-优化前

• 函数调用详细-优化后

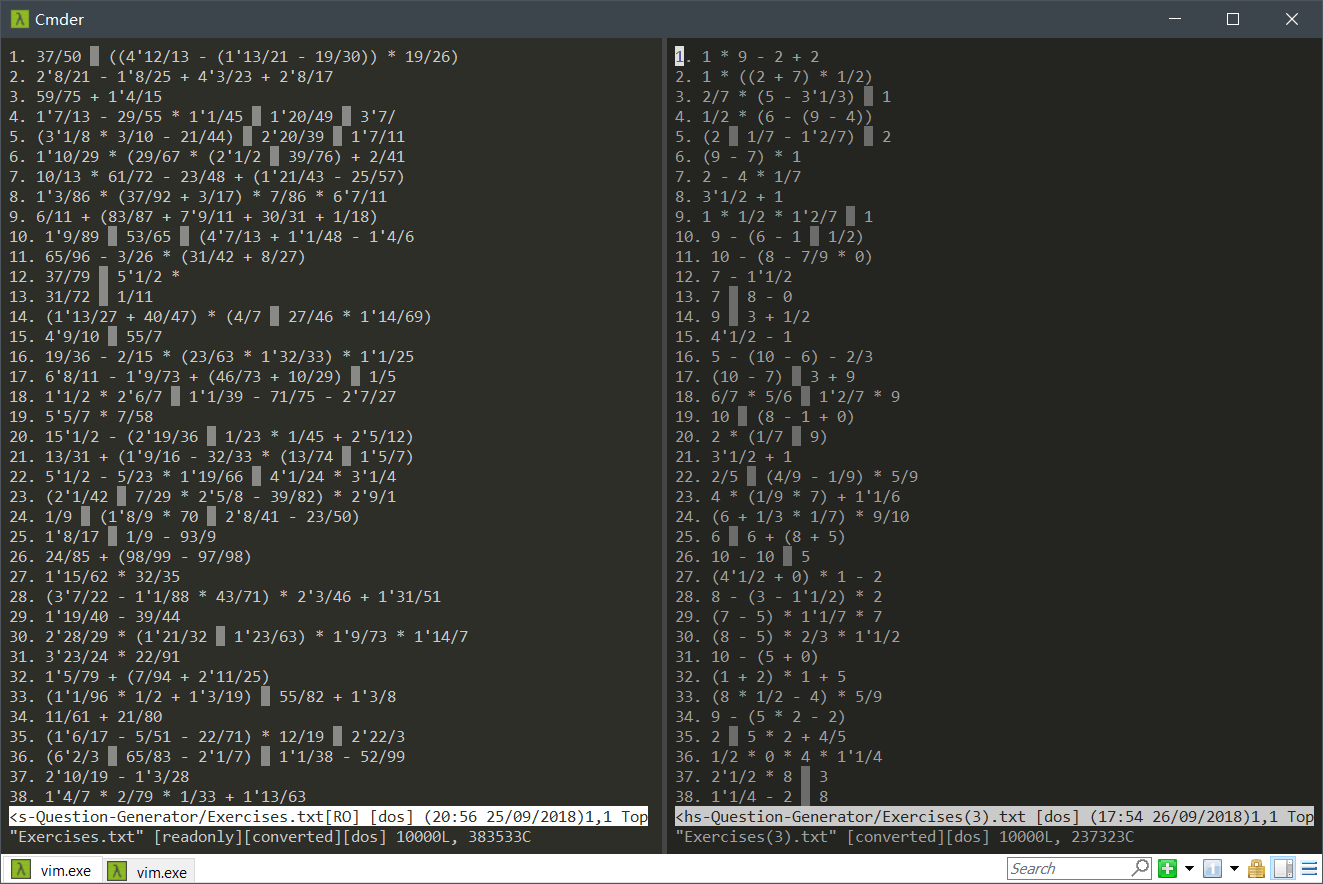
5)尽管在上述中的测试中,我们发现控制分数的占比不能有效提升性能,但是在最终版本我们仍决定引入控制分数的机制,提高整数出现的占比。因为考虑到此次作业实际上是"小学生计算题生成",给小学生的作业题几乎全是分数与代分数确实是不妥。
• 题目生成图 (左:引入前;右:引入后)
• 解析答案模块
1)最初预期可能存在的优化方向与约分有关,约分操作是内嵌入重载运算符中,还是等待得出最终运算结果后再一次性进行约分,但从测试报告来看,约分所需要的计算公因数的操作实际上占比极低,故最后并没有做改动,仍旧沿用了等待结果一次性约分的做法,不过这种方式存在安全缺陷,当运算量特别大时可能会发生溢出,不过考虑到此次题目的要求至多仅有三个运算符,所以最终还是选择了这种方案。执行处理的总体速度基本上达到了预期。
• 分析报告

2)耗时最多的是Expression函数,因为实现的时候是用递归的方式,所以实际上这里的Expression运算耗时是单词解析和语法分析的总和,属于正常的运算,难以再进行调优,而IO的输入输出也很难再进行调优。
• 调用树
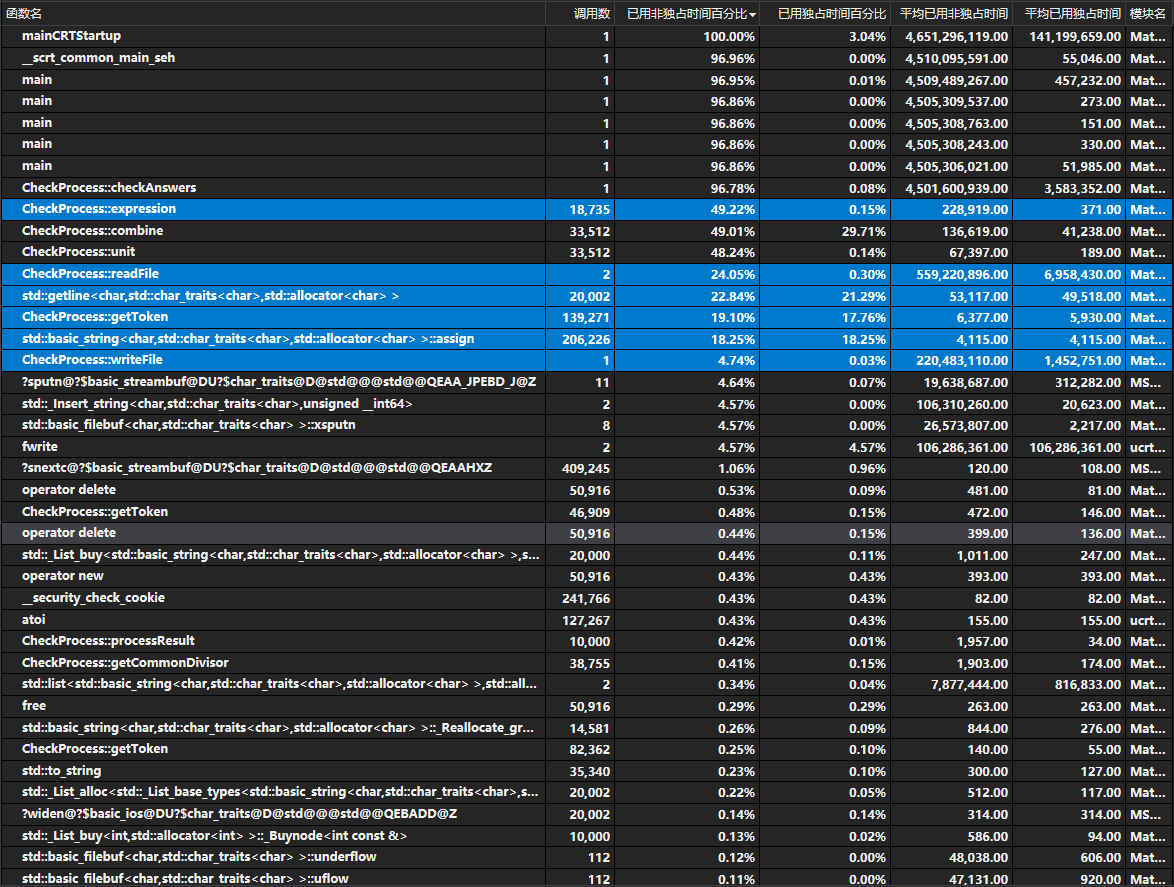
七. 测试结果
• 单元测试
此处的单元测试不包含项目早期对独立导入表达式的测试部分(TestCheck1 ~ TestCheck6),因为相应的函数已经根据实际情况转为private方法,而后续测试中调用的函数仍会调用该方法,所以此处不再展示

• 生成1万道题目耗时
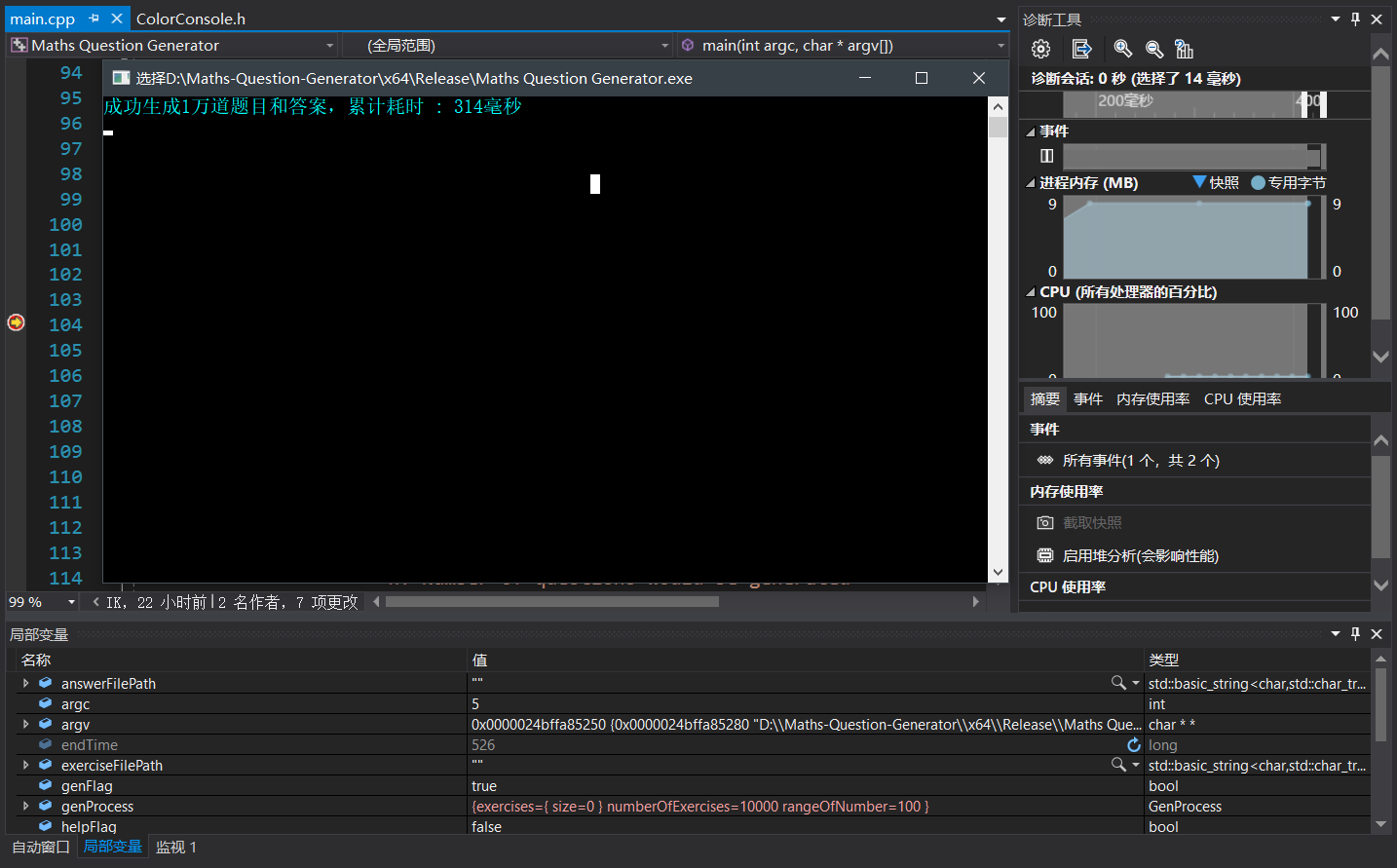
• 解析1万道题目耗时

• 生成题目和正确答案
• 错误情况处理

• 生成题目和正确答案
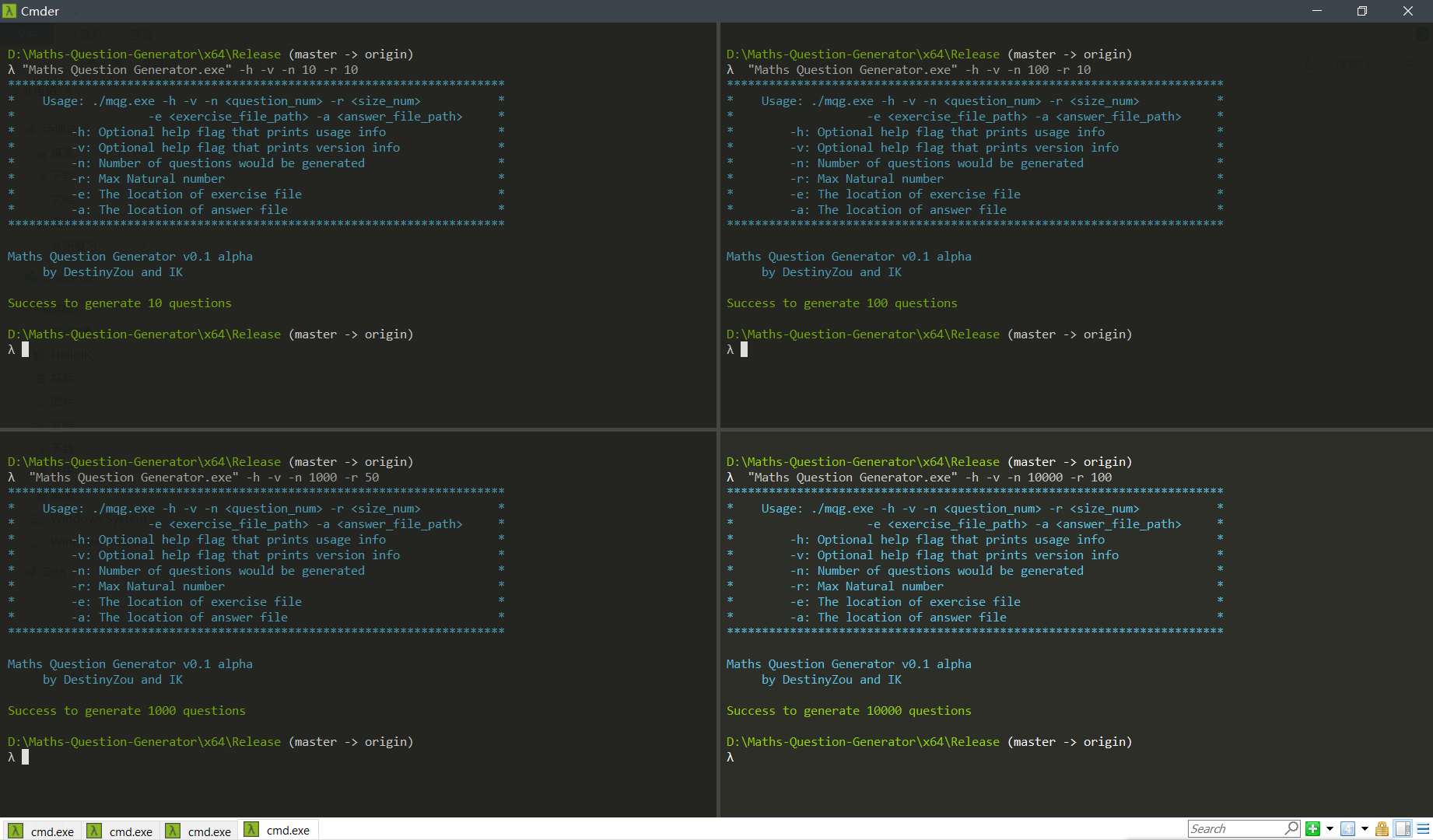
• 写出的Exercises.txt与Answers.txt文件
此处的乱码是因为我的vim编码设置没有对应除号
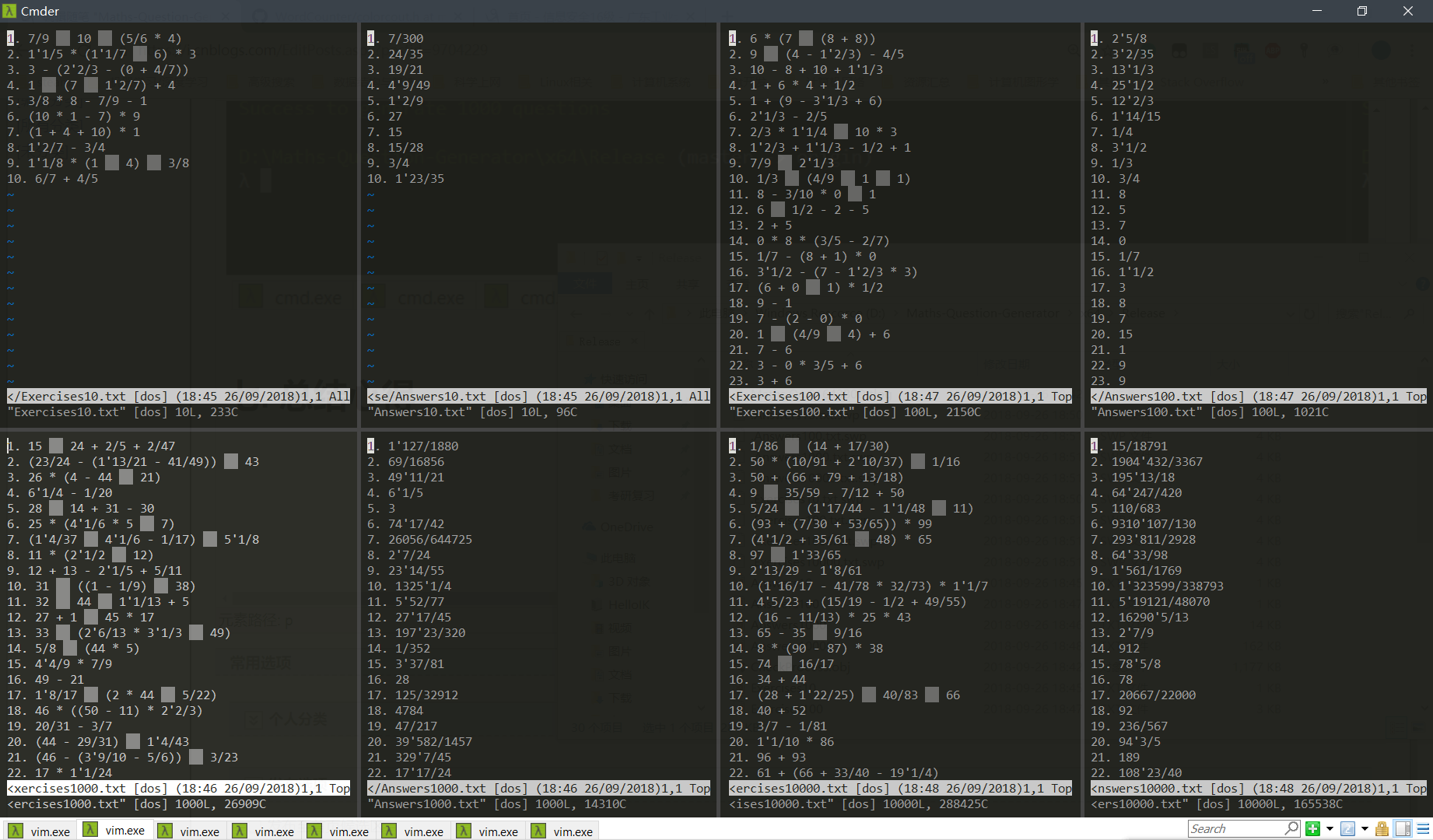
• 解析题目并给出判断
• 错误情况处理

• 解析题目和判断正误

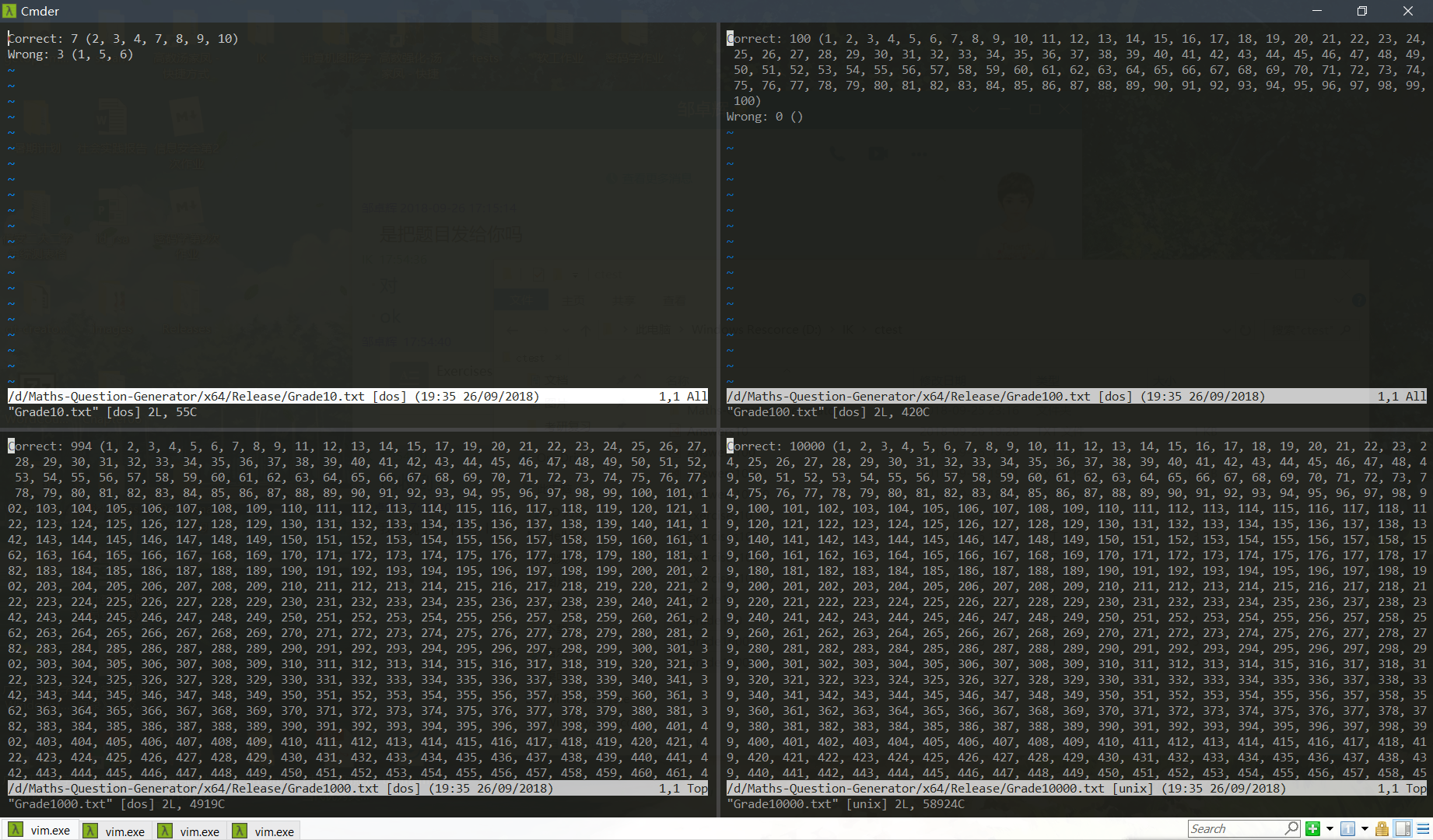
• 写出的Grade.txt文件
八. 总结心得
通过这次结对编程,贯彻了团队合作的精神,同时也遇到了许多问题,学到了很多新的知识。